Hi! My sabbatical ended and I’ve been working again since two months ago. Boo. However there’s this thing I just wanted to get off my chest, so I spent a few hours that I did not really have and wrote some code and this blog post about it!
Last year, I made a 4164/4116 DRAM tester for the Raspberry Pi Pico, which works just as you would expect, you program the Pico, place it on a breadboard, add some wires and something to drop the 5V to 3.3V for the Q output, place the 4164 or 4116 chip you’d like to test on the breadboard, connect a USB cable from the Pico to a computer, and look at the terminal output (or just the on-board LED). This is useful if you have already extracted a 4164 chip that you have determined to be bad. (I have written previously how you could determine whether a 4164 chip is bad, here and here.)
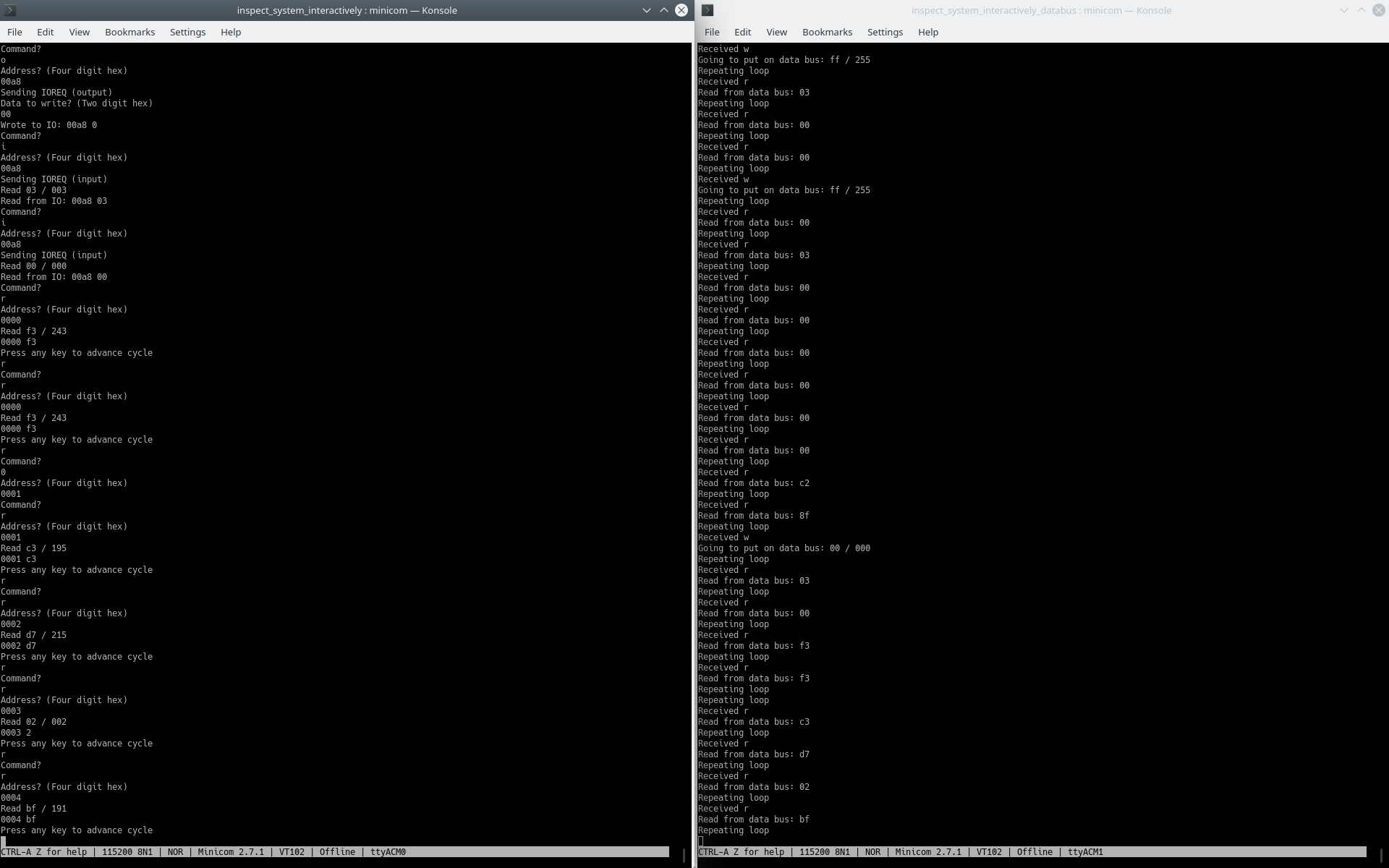
We “allocate” 64 KB of RAM on the Pico. We need to read in two 8-bit addresses, and combine them to a 16-bit address. If a write is being attempted, we write the same bit value into the appropriate address of Pico’s RAM. If a read is being attempted, we check if the DRAM’s output is the same as what we have in the Pico’s RAM. (We could also use 64 Kb of RAM on the Pico at a minimum, but as we’ll see in the next section we do not really have a lot of time for such shenanigans.)
Note: to use this software, you need to at least mostly know what you’re doing.
Example usageTest clip close-upWiring closeup
One note on hooking up the Pico directly to 5V components, as seen in the above pictures
Not guaranteed to not fry your Pico (note the double negation), do this at your own risk. Your Pico will possibly also draw more current than a normal TTL chip when driven above 3.6V or so, which could easily damage your precious hardware! (The current on the address pins will likely be supplied by a pair of 74LS157 chips, on the Q pins by the RAM chip, and the current on the RAM’s data in pin by the CPU or any other. \RAS and \CAS probably by custom logic chips.) Use a 74HCT245 between the Pico and the device you’d like to test.
Caveat 1
The Pico is very fast when compared to an 8-bit computer from the 1980s, but 4164 transition times are extremely fast too. If you look at a timing diagram for the 4164 (which you will find in any 4164 datasheet), you will notice that all transition times listed are on the order of <ten, tens, or low hundreds of nanoseconds. Most 4164 chips have a -20, -15, -12, or -10 suffix in their part number. This indicates the minimum allowable number of nanoseconds × 10 for the sum of all transitions. (If the DRAM is driven faster, it probably won’t work correctly. However, if it’s driven slower, most things will generally work out, though if your system e.g. reads the DRAM’s output too slowly it might be too late and not work out.)
The stock Pico runs at 125 MHz, which means that one CPU cycle is 8 ns. From hearsay, you can probably overclock any Pico to 200 MHz (clock cycles are 5 ns), and many people report that their Pico runs fine even at 400 MHz (clock cycles are 2.5 ns). For -15 DRAMs, you have 150/8 = 18.75 CPU cycles per transition if the DRAM is driven at its max speed. (Note: it isn’t on MSX machines, at least.) 18 CPU cycles isn’t a lot. Remember, we need to convert two 8-bit addresses to a 16-bit address, and then check if the newly read value matches our previously recorded value. Is that doable in 18 CPU cycles? I don’t think so, but I’m not an ARM assembly expert.
So, did I get it to work? Well… sort of but not quite.
Caveat 2
Note that there are many failure modes for DRAM chips. For example, if the chip gets super-hot within a few seconds, it’s probably shorted. I’d expect there to be a very low resistance between ground and another pin. Before hooking up the “live” tester I’m going to explain on this page, check for that kind of stuff. I would not recommend using the live tester on a chip that gets super-hot within seconds. You could risk melting your connectors, and if the short is not between VCC and GND, potentially also risk your Pico due to excessive current on a pin driven by the Pico.
Caveat 3
Untested with 4116 chips, only tested with my MSX’s main RAM.
Current status
The live tester successfully verifies that a TMS4164-15 DRAM chip under test in my stand-alone 4164 RAM tester is outputting the correct values. (There is no reason why it shouldn’t work with a 4116 chip. The tester certainly does! You just need to re-wire slightly. Also, 5V on the Pico, yeah, it doesn’t seem to “explode immediately.” But -5V or 12V? You’d better leave those pins unconnected!)
On a real system (my trusty Hitachi MB-H2 MSX) with TMS4164-15NL DRAM chips, the live tester manages just fine from power up, up until the first ~11000 comparisons (which is a split second), but at some point reads a 0 when it should have been a 1, and prints an error. Printing errors takes a long time at 115200 bps, so we go completely off the rails once we’ve encountered the first error. (That’s slightly configurable though, see “Lnobs” section for details.)
However, in the live tester’s “DEBUG” mode, it just collects a lot of samples into memory, and prints them out when the sample memory is full. Using a simple script (the Perl script included in the repo), I can then verify that all the samples check out. Note that the DEBUG code also prints out who many times it had to wait until it got data from the PIO. The answer is 0 times every time, which means that we’re too slow or almost too slow. (Sometimes there is a handful of mismatches, I’ll look into those at some point. Could be that we were just too slow, or the 5V is messing with the system ;D)
There’s a lot that could be improved, hence the “WIP” attribute in title. The first obvious improvement would be to try a little harder in the non-debug mode. The Pico has two CPU cores, and we’re only using one. We could attain more throughput by running according to the following scheme:
Core 1: Wait for sample 1 Tell core 2 to wait for sample 2 Process sample 1 Wait for sample 3 Tell core 2 to wait for sample 4 Process sample 3 …
Core 2: Wait for instructions from CPU 1 Wait for sample 2 Process sample 2 Wait for instructions from CPU 1 Wait for sample 4 Process sample 2 …
Another potential optimization would be to write the processing code in ARM assembly. (My experience with ARM assembly is mostly read-only, so not sure how much better I can get without spending way too much effort.)
Also I haven’t tried overclocking yet. Probably should!
Some more technical details
We use two PIO state machines. One waits for RAS high→low (“RAS SM”, and the other one waits for CAS high→low (“CAS SM”, which comes after the RAS transition.
Not all RAS transitions are followed by CAS transitions. For example, refresh is mostly RAS-only. In addition, though perhaps not used on the MSX(?), RAS transitions may be followed by multiple CAS transitions.
In the C code, we wait for events on the CAS SM, and then read from both the RAS SM’s FIFO and the CAS SM’s FIFO. In the PIO code, the CAS SM tells the RAS SM whether to push its address or not. (We could alternatively (maybe) always push and have the CPU make sure the FIFO never gets full, but my experiments in that regard didn’t go that well.)
There are a lot of defines that change the way the system works.
Knobs
Setting PRINT_ERROR_THRESHOLD to something above 0 only starts printing errors after encountering that many errors.
CORRECT_ERRORS causes the Pico’s memory to be updated when we encounter a mismatch
VERBOSE_STATUS_LEDS causes the Pico to perform GPIO writes at GPIO16+ (or so, I recommend you check the source to find the exact GPIO pin number) to indicate whether we’re reading or writing. This isn’t very beneficial performance-wise.
SWAP_RAS_AND_CAS_ADDRESSES: my Hitachi MB-H2 MSX applies the CPU’s A0-A7 to the RAM pins at RAS time, and A8-A15 at CAS time. When thinking “rows” and “columns”, most people would probably assume that “rows” use the more significant bits, but that is not necessarily the case, and it doesn’t matter. When operating in DEBUG mode, you’ll see accesses that are mostly linear if this define is set correctly. Otherwise each access will be 256 apart.
I haven’t seen any DRAM chip failures (except on YouTube) where only some addresses were broken and the chip appeared to work otherwise. (SRAM chips are different story. I’m sort of planning on doing an SRAM tester too, but probably not too soon.) Most DRAM chips I’ve seen are an all-or-nothing affair. For all-or-nothing affairs, this chip tester is very likely to find the problem immediately, especially if you compare all 8 chips and only one is weird. For hypothetical chips with just a single address problem (or perhaps, a single broken row), either it’ll be difficult with the code not 100% working right now, or it might take several attempts and statistics.
(I do not recommend watching this demo on a smartphone. It’s quite flashy and exacerbated my headache. Also, the WebMSX code will ask you to go fullscreen, but I don’t think you can start the demo without going fullscreen and then back again.)
In part 1, we constructed a 48 KB ROM to play a tune called “Popsa 2”. We didn’t apply any real compression algorithms but implemented a set of scripts to find repeated sections in a binary file and added an instruction to the .psg file format to “call” repeated sections. Using real compression algorithms we could achieve much better compression, and each tune would just occupy a couple KBs. Using our method, we _just_ manage to fit the tune into a single cartridge. Popsa 2 fit into 48 KB, and the tune we’re going to do today is going to require a 64 KB ROM. If the previous track didn’t quite do it for you, I think it might be worth giving this one a chance. It’s a very complex piece of wonder-inducing music in my opinion. (Press the power button and in the menu that pops up, choose “Power” to boot the ROM.)
64 KB ROMs still require a header at 0x4000 or 0x8000. This means that we need to add a header and some entrypoint code to set up the slots right in the middle of our data. That’s inconvenient, but I didn’t feel like changing the structure of the program, so I just added one check each at the beginning and end of the main loop to see if the HL register has gone above a certain value. If yes: before the main loop, it adds an offset; after the main loop, it subtracts the same offset again. This way, we don’t have to do anything too complex when jumping to a previous section of the track.
In part 1, I mentioned a problem in WebMSX that prevented the 48 KB ROM from working. 64 KB ROMs are not affected by this problem. The WebMSX player at the top of this article page plays the ROM linked to above. The ROM also works on real hardware (the Hitachi MB-H2 MSX1 I repaired a while ago).
Aside: disabling WebMSX’ auto-scroll
In the unlikely event that you have read this blog’s front page sometime in the last few months, you might have noticed that it scrolled automatically to this WebMSX player, even though this post is now very much not the newest post on this blog! I only noticed this a short while ago and decided to fix it, because it’s quite annoying. The below code snippets are taken from the WebMSX commit with the tag “v6.0.4”. Older or newer versions may look different.
All you need to do is remove the “this.focus()” line in the powerOn function in CanvasDisplay.js:
this.powerOn = function() {
this.setDefaults();
updateLogo();
document.documentElement.classList.add("wmsx-started");
setPageVisibilityHandling();
this.focus(); // <-- this is the line you need to remove or comment out
if (WMSXFullScreenSetup.shouldStartInFullScreen()) {
setFullscreenState(true);
if (FULLSCREEN_MODE !== 2 & isMobileDevice) setEnterFullscreenByAPIOnFirstTouch(); // Not if mode = 2 (Windowed)
}
};
If you prefer to just edit the minified version, search for the call to setPageVisibilityHandling() and then edit out the “this.focus(),” bit.
This article is somewhat technical. If you just want to listen to a chip tune on WebMSX, maybe go for part 2 instead.
In previous articles I explored the YM2151 and the VGM file format. In this article, we’ll go back a generation and listen to some tunes written for the DSG (doorbell sound generator) PSG (programmable sound generator, i.e., the General Instruments AY-3-8910, or compatibly, Yamaha’s YM2149). PSG files (and particularly ASC files) are mainly used for ZX Spectrum chip tunes (I think), but the MSX has the same sound chip so why not play some chip tunes on the MSX?
Well, before we spend time working on something just slightly above PC beeper music… are there even any decent PSG tunes? Well, I’ve found at least one that like, “Popsa 2”, as is included in the below mix (scroll down a bit) on YouTube for example, and some of the commenters on this video seem to like “Illusion”.
Unfortunately, it doesn’t work in WebMSX (after 20 seconds or so). But it works in all three (NTSC) openMSX machines I bothered to test with, and it also works on my real MSX1 (Hitachi MB-H2). To get it to run in WebMSX, you have to “Set ROM format” -> “KonamiSCC”, but even then it’ll crash after a few minutes (vs. 20 seconds for e.g. ASCII8). For some reason it doesn’t let me choose “Normal”. I’m quite sure it would work with that setting if it were available. :p I’ll look into the matter at some point, probably. Looks like WebMSX will require a patch to work. Patch is submitted and will probably make it into the next version.
This machine produces NTSC color artifacts like there is no tomorrow.
Caution: writing to certain PSG registers is unsafe on certain MSX machines. I don’t think my code writes to these registers, but I didn’t make 100% sure. (However, openMSX gives you a warning when it notices unsafe writes, and I didn’t get a warning.)
“Popsa 2” was made in a program called ASC Sound Master. The “.asc” file can be downloaded here: https://zxart.ee/eng/authors/d/dreamer/popsa-2/. These .asc files are pretty small. They can be converted to PSG using ZXTune (https://bitbucket.org/zxtune/zxtune/) (and from PSG they can easily be converted to e.g. VGM, see bottom of this post), but the resulting files are too large to fit on a regular MSX1 cartridge.
ZXTune compilation and conversion:
git clone https://bitbucket.org/zxtune/zxtune.git
cd zxtune
make platform=linux system.zlib=1 -C apps/zxtune123/ -j4
bin/linux/release/zxtune123 --convert mode=psg,filename=foo.psg -- Dreamer\ -\ POPSA-2\ \(1994\).asc
The original .asc file is 3720 bytes. The resulting .psg is 129028 bytes. If you convert that to VGM, the resulting size is 187342 bytes.
The PSG file format
The PSG file format is very similar in concept to the VGM file format, except that only one chip is supported, the PSG. It seems it’s primarily used for ZX Spectrum chip tunes. As only one chip is supported, you don’t need the “command byte” that indicates what chip is to be written to. So you only have pairs of “register address” and “register value to write”.
There’s also a header in the first 16 bytes. The first three bytes are “PSG”, dunno about the rest.
The PSG only has 16 (IIRC) registers, and some of those aren’t even relevant for sound. In other words, the registers 0x10 to 0xff don’t exist and the designers of this file format used that opportunity to fit in a “wait” command at 0xff (one raster scan, so 1/50s or 1/60s depending on whether the system is PAL or NTSC). There’s also a command that waits multiple raster intervals, 0xfe, and a command that ends the tune, 0xfd. Ignoring the header, here are the first few bytes of the Popsa 2 PSG file:
All this means: wait 1 raster interval, then write to registers 00 through 0a with values 41, 05, 0b, 01, …, respectively, wait 1 raster interval, write to registers 02, 03, 07, 09, 0a, with values e0, 00, 38, 0d, 0c, respectively, wait 1 raster interval. (As you can see the 0xff command doesn’t take any parameters.)
Now that we know mostly how this file format works, it’s time to think about how to fit roughly 126 KB of data into my 48 KB cartridge. We could easily use an off-the-shelf compression library, but where’s the fun in that? That’s like… modern programming, ew.
We’ll invent another command for PSG, 0xfc, which takes a two-byte parameter that tells it to jump back somewhere (for a while, and then returns to its original location). We also need to write a program that identifies repetitive sections in the music (of which there are plenty). The former is pretty easy, so let’s talk about the latter program first.
Compute MD5 sums of a 100-byte window for every byte in the file. So we end up with 129028-100=128928 MD5 sums. Easy and fast on modern hardware. See code snippet below.
Check if we even have repeated chunks, e.g. by executing: md5sum chunks/* | awk ‘{print $1}’ | sort -n | uniq -c
We may want to check a couple other window sizes to see if we can get better results. A lower window size means we’ll find more repetition, but we need 3 bytes to encode a jump in our PSG file.
Re-assemble PSG file using a quick-and-dirty and probably somewhat buggy script. (See below.)
The resulting data length is 42158 bytes for the Popsa 2 song.
For task (1) we first convert the PSG file into hex, and later into tokens:
xxd -p Dreamer\ -\ POPSA-2\ \(1994\).psg | sed -r -e 's/(..)/\1 /g' | tr -d '\n' > Dreamer\ -\ POPSA-2\ \(1994\).psg.hex
# Then remove 16-byte header using a standard text editor
Then divide the tokens into chunks using the below script, divide_tokens_into_chunks.sh:
#!/bin/bash
N=100 # sliding window length
mkdir -p chunks_N$N
line_count=$(cat tokens | wc -l)
for ((i=0; i<$((line_count-N)); i++)); do
tail -n +$i tokens | head -n $N > chunks_N$N/chunk_$i
done
rm chunks_N$N/chunk_0 # same as chunk_1
You know, looking back at this code for the first time in a while, I see there’s a nice off-by-1 error and a nice rm command to fix half of the problem. But the great thing about this being a hobby is that I don’t need to care. :)
Next, we have a Perl script that creates our PSG file. It needs some help though, so we do this first:
(We can’t do md5sum chunks_N100/* because that expands to a tad too many arguments in our case. xargs automatically cuts down the number of arguments to a more reasonable value.) This is the main program. Usage: ./compress_aggressive_but_convert_to_psg.pl < chunks_N100_md5sums > foo.psg
#!/usr/bin/perl
# dependencies:
# chunks_N$N/ (directory)
# chunks_N$10_md5sums (file) # example generation: find chunks_N10/ | xargs md5sum > chunks_N10_md5sums
use strict;
use warnings;
use feature "switch";
my $N = 100;
my $md5s = {};
my @chunks;
my $md5;
my $file;
my $debug_logged = 0;
my $lines = [];
my $current_output_byte_number = 0;
for (my $chunk_number = 0; <>; $chunk_number++) {
/([a-z0-9]+)\s+([a-zA-Z0-9_\/]+)/;
$md5 = $1;
$file = $2;
if (exists $md5s->{$md5}) {
# can't call chunks that already contain a call because that call would take us beyond the N token window that we can see from where we are
# that means it's likely we'd generate wrong code
# so we'll just move on and maybe we'll find a nicer block
my $target_chunk_number = $md5s->{$md5}->{chunk_number};
my $concatted_chunks = join('', @chunks[max(0, $target_chunk_number-$N)..min($#chunks, $target_chunk_number+$N)]);
if (($concatted_chunks =~ /; call/) or # NOTE "call wait_for_raster" is allowed
($chunk_number - $target_chunk_number < $N)) {
# 1) can't convert due to existing call; nothing to be done here, or
# 2) we can't call something right behind us
# DANGER let's head back to the non-exists path
goto NON_EXIST_PATH;
} else {
if (!$md5s->{$md5}->{converted_to_call}) {
convert_to_callable_sub($target_chunk_number);
$md5s->{$md5}->{converted_to_call} = 1;
}
my $output_byte_number_high = int($md5s->{$md5}->{output_byte_number} / 256);
my $output_byte_number_low = $md5s->{$md5}->{output_byte_number} % 256;
$chunks[$chunk_number] = sprintf("fc %02x %02x ; call " . $md5s->{$md5}->{output_byte_number} . " ($md5)\n", $output_byte_number_high, $output_byte_number_low);
$current_output_byte_number += 3;
# skip next N-1 rows
for (0..$N-1) {
my $foo = <>;
$chunk_number++;
$chunks[$chunk_number] = "";
}
}
} else {
$md5s->{$md5} = {};
$md5s->{$md5}->{chunk_number} = $chunk_number;
$md5s->{$md5}->{converted_to_call} = 0;
NON_EXIST_PATH:
open my $fh, '<', $file or die "Can't open \"$file\": $!";
my $token = <$fh>;
close $fh;
my $asm = convert_to_asm($token);
$md5s->{$md5}->{output_byte_number} = $current_output_byte_number;
$current_output_byte_number += (scalar(split(" ", $asm)));
$chunks[$chunk_number] = $asm;
}
}
print foreach @chunks;
print "infloop:
jr infloop\n";
# no changes needed
sub convert_to_callable_sub($) {
my $block_number = shift;
}
# don't actually do anything here
sub convert_to_asm($) {
my $string = shift;
return "$string";
}
sub min($$) {
my ($a, $b) = @_;
return $a if ($a < $b);
return $b;
}
sub max($$) {
my ($a, $b) = @_;
return $a if ($a > $b);
return $b;
}
The output of this program is in hex. Now we just need some assembly code to read the data and put it into the PSG registers. Here’s the core part:
ld hl,psg_begin
main_loop:
ld a,(hl)
cp 0xff
jr z,wait
cp 0xfe
jr z,wait_n_times
cp 0xfd
jr z,end
cp 0xfc
jr z,jump
jr register_write
inc_loop:
inc hl
jr loop
wait:
call wait_for_raster
jr inc_loop
register_write:
ld a,(hl)
out (0xa0),a
inc hl
ld a,(hl)
out (0xa1),a
jr inc_loop
wait_for_raster:
in a,(0x99)
and 128
cp 128
jr nz,wait_for_raster
ret
psg_begin:
include "foo.psg"
ds 010000h-$ ; fill rest with 0s
Understanding the above should help understanding the full implementation. (The above doesn’t include the code for the 0xfe, 0xfd, and 0xfc commands.) Note that we can’t use the above wait_for_raster on NTSC machines because the tune assumes 50 Hz. So we’ll instead emulate the 50 Hz interval using a busy loop.
For 0xfd (end of song), we just enter an infinite loop. For 0xfe, we just call wait_for_raster multiple times. For 0xfc, we need to store where we left off, then set hl to the address in the parameter, then execute exactly 100 main loop runs, then set hl back to its previous address and continue as normal.
Here’s the code, which also includes some VRAM writes to visualize the music a little bit. Does it look good? Eh, I dunno. It was an experiment. I changed the registers to be displayed because some registers don’t see updates very often. The overall visuals are a bit noisy, but there is one section that looks good in my opinion, and it’s also the section that I like best in the tune, right at the end. You can clearly see one of the registers changing right in sync with the doorbell sound. (It looks even more in sync in openMSX.)
N: equ 100
org 4000H
db "AB"
dw entry_point
db 00,00,00,00,00,00,00,00,00,00,00,00
SetVdpWrite: macro high low ; from http://map.grauw.nl/articles/vdp_tut.php
ld a,low
out (0x99),a
ld a,high
add 0x40
out (0x99),a
endm
vpoke: macro value
ld a,value
out (0x98),a
endm
entry_point:
; copy cart rom (c000-f000) to ram
in a,(0a8h)
and 11000000b ; we want to know which slot is RAM, and AFAIK RAM should be mapped in at 0xc000-0xffff.
ld c,a ; save value for later
in a,(0a8h)
and 00001100b ; we are executing from cartridge ROM at 0x4000~0x7fff, so the 2-bit value for this region is known correct. we just have to make the slots above this one the same value.
ld b,a ; save a
rla ; << 1 (now have 000xx000b)
rla ; << 1 (now have 00xx0000b)
or b ; | saved b (now have 00xxxx00b)
rla ; << 1 (now have 0xxxx000b)
rla ; << 1 (now have xxxx0000b)
or b ; | saved b (now have xxxxxx00b)
; ld a,01010100b ; set pages 0: rom 1: rom 2: cart 3: cart
out (0a8h),a
copy_c000_f000:
ld hl,0c000h ; start at c000
copy_c000_f000_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
and 00111111b ; only keep settings for lower three slots
or c ; add in setting for top slot (saved earlier)
; ld a,011010100b
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 0f0h
jp z,other_init ; done with this copy
jp copy_c000_f000_loop
; entry_point:
; ld a,0xd4
; out (0xa8),a ; set slots
other_init:
; set ports to bios:cart:cart:ram
in a,(0a8h)
and 00111111b ; only keep settings for lower three slots
or c ; add in setting for top slot (saved earlier)
out (0a8h),a ; set port
; set colors
ld a,011110000b ; set data to be written into register (white on black)
out (099h),a
ld a,010000111b ; set register number (7)
out (099h),a
SetVdpWrite 0x20 0x05
vpoke 0x0f ; set white on black for some part of the screen
vpoke 0x0f ; set white on black for some other part of the screen
video_init:
; put chars /0123456789 into 0x1800-0x1AFF
SetVdpWrite 0x18 0x00
ld b,64 ; 64 chars
video_loop_1:
vpoke 0x2f
djnz video_loop_1
ld b,64 ; 64 chars
video_loop_2:
vpoke 0x2f
djnz video_loop_2
ld b,64 ; 64 chars
video_loop_3:
vpoke 0x33
djnz video_loop_3
ld b,64 ; 64 chars
video_loop_4:
vpoke 0x33
djnz video_loop_4
ld b,64 ; 64 chars
video_loop_5:
vpoke 0x36
djnz video_loop_5
ld b,64 ; 64 chars
video_loop_6:
vpoke 0x36
djnz video_loop_6
ld b,64 ; 64 chars
video_loop_7:
vpoke 0x31
djnz video_loop_7
ld b,64 ; 64 chars
video_loop_8:
vpoke 0x31
djnz video_loop_8
ld b,64 ; 64 chars
video_loop_9:
vpoke 0x35
djnz video_loop_9
ld b,64 ; 64 chars
video_loop_10:
vpoke 0x35
djnz video_loop_10
ld b,64 ; 64 chars
video_loop_11:
vpoke 0x37
djnz video_loop_11
ld b,64 ; 64 chars
video_loop_12:
vpoke 0x37
djnz video_loop_12
ld b,64 ; 64 chars
ld b,0 ; flag to indicate whether we are jumping around at the moment (0 means we aren't) (NOTE: nested jumping isn't supported)
ld c,0xa0 ; first PSG port
ld hl,psg_begin
jr main_loop
loop:
ld a,b
cp 0
jr z,main_loop ; b isn't set so just head back to the loop
pop af
dec a
cp -1
jr z,restore_hl
push af ; don't need this on the stack if we go to restore_hl, so place it after the jump
jr main_loop
restore_hl:
ld b,0 ; unset flag
pop hl
inc hl
; and continue executing into loop
main_loop:
ld a,(hl)
cp 0xff
jr z,wait
cp 0xfe
jr z,wait_n_times
cp 0xfd
jr z,end
cp 0xfc
jr z,jump
jr register_write
inc_loop:
inc hl
jr loop
wait:
call wait_for_raster_50hz_emu
jr inc_loop
wait_n_times: ; safe to assume that param isn't 0
push bc
inc hl
ld b,(hl)
wait_n_times_loop:
call wait_for_raster_50hz_emu
djnz wait_n_times_loop
pop bc
jr inc_loop
end:
jr end ; infinite loop
jump:
inc hl
ld d,(hl)
inc hl
ld e,(hl)
push hl
ld b,1 ; signal that we're calling a previous segment
ld a,N ; we want to execute N instructions before going back to where we left off
push af
ld hl,psg_begin
add hl,de
jr loop
register_write:
ld a,(hl)
out (c),a
; really we only need ld a,(hl) and out (0xa1),a, but let's poke around in the VRAM to make this program slightly less boring
; we'll modify the tile definitions of characters /, 0, ..., 9 (8 bytes each starting at 0x178) and just put in the same value we're writing to the PSG register
or a ; clear carry flag to make rla behave
; a = a*8 for vram write address
rla ; *2
rla ; *2 (*2*2 == *4)
rla ; *2 (*2*2*2 == *8)
ld d,a ; vram write address
inc hl
ld a,(hl)
ld e,a ; vram write value
out (0xa1),a
ld a,0x78
add a,d ; vram address low byte is 0x78 + (psg register)*8
; color change code currently commented out because it's not very pleasant to look at
; ; let's also change some colors when register 5 is written to, which doesn't appear to happen very often
; ; for register 5 a is 5*8 + 0x78 = 0xa0
; cp 0xa0
; jr nz,skip_color_change
; ld d,a
; ld a,e
; out (099h),a
; ld a,010000111b ; set register number (7)
; out (099h),a
; ld a,d
skip_color_change:
SetVdpWrite 1 a ; vram address high byte is 1 (full address: 0x178)
vpoke e
vpoke e
vpoke e
vpoke e
vpoke e
vpoke e
vpoke e
vpoke e
jr inc_loop
wait_for_raster:
in a,(0x99)
and 128
cp 128
jr nz,wait_for_raster
ret
wait_for_raster_50hz_emu:
; CPU clock is 3579545 Hz
; decrement and loop routine takes 36 instructions per loop run (wait_for_raster_50hz_emu_loop up to (not including) low_0)
; (https://www.overtakenbyevents.com/tstates/)
; want routine to finish in 1/50 or a second, so:
; 3579545/50/36=1988.636111111111, let's very scientifically, er, let's throw out that whole calculation and say 1650 because we have overhead and I have experimentally determined that to sound close enough to the original :p
; our overhead varies depending on code path. some rhythm problems are audible, but not _too_ terrible
ld de,1650
wait_for_raster_50hz_emu_loop:
dec de
ld a,e
cp 0
jr z,low_0
jr wait_for_raster_50hz_emu_loop
low_0:
ld a,d
cp 0
jr z,high_low_0
jr wait_for_raster_50hz_emu_loop
high_low_0:
ret
psg_begin:
include "foo.psg"
ds 010000h-$
Compiles with z80asm. Other assemblers might need some tweaks.
Bonus: converting PSG files to VGM
This is implemented in straight-forward C. Compilation: cc -o psg2vgm psg2vgm.c Execution: ./psg2vgm Dreamer\ -\ POPSA-2\ \(1994\).psg | xxd -r -p > foo.vgm
I have a Yamaha MSX1 (YS-503) with 64 32 KB of RAM and an SFG-01, which has a YM2151 on it. I do not have a floppy drive, but I have a way to easily “make cartridges” that are up to 48 KB in size. This blog post explores the source code of vgmplay-msx and ports portions of the program to work off a cartridge. Here’s how the result looks in openMSX:
Here are ROM files that work in OpenMSX, one with the SFG-01 inserted into slot 2, and the other with the SFG-01 inserted into slot 3, both playing the first ~20 seconds of track 2 on https://vgmrips.net/packs/pack/fantasy-zone-ii-dx-sega-system-16c, “10 Years After ~ Cama-Ternya [Demo]”.
VGM files have a 128 or 256-byte header followed by the actual song data. The song data entirely consists of 1-byte commands possibly followed by a couple bytes of arguments to the command. The only commands we are interested in are “YM2151 register write” and the “wait” commands, of which there are a few. (And maybe the end of song/loop commands.) Everything else is irrelevant for our setup and what we want to do.
We only have 48 KB of ROM space, which means that it’s a bit of a tight fit for the program and the song data. The stock vgmplay.com file is about 32 KB, but it includes code (src/drivers/) for a lot of chips. We only need src/drivers/SFG.asm. There are also vast regions of 0s. We also don’t need any code to make song data fit into more than 64 KB of RAM (src/MappedReader.asm). We don’t need support for compressed .vgm files. And we don’t need any MSX-DOS-specific code, nor do we need code to handle reading from the floppy drive. Song data tends to be relatively large too: the song I used in Raspberry Pi Pico implementation of the YM3012 DAC (mono) was around 1 minute and is 68 KB in size. We’ll have to either truncate it, or find something shorter or simpler.
vgmplay-msx is written in a rather unusual assembly dialect. The assembler supports scoping, and there appears to be a bit of a “class” hierarchy. For example, MappedReader (src/MappedReader.asm) extends Reader (lib/neonlib/src/Reader.asm).
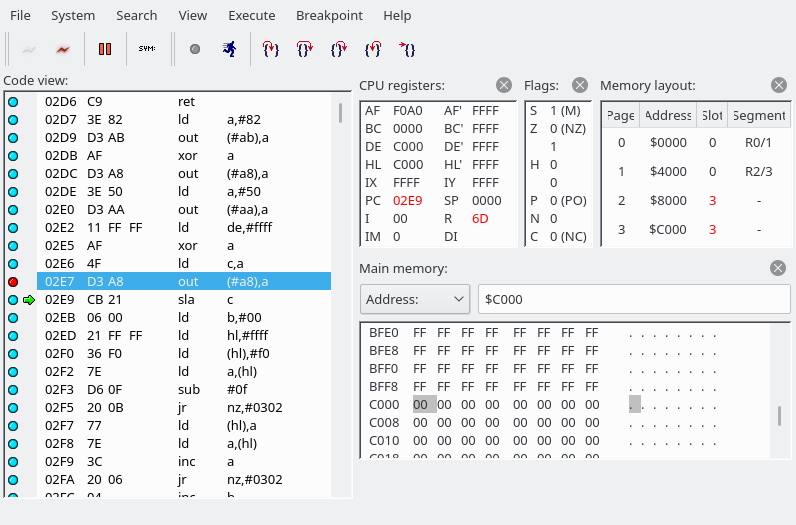
After putting the MSXDOS22.ROM into .openMSX/share/systemroms and booting from MSXDOS22.dsk, and adding the Yamaha SFG-01 extension (Hardware -> Extensions), and executing ‘make’ in the vgmplay-msx source directory, I was able to execute ‘vgmplay foo.vgm’ in MSX-DOS and hear the VGM file being played back in openMSX. After reading the code for a little bit, I opened and connected the debugger. In System -> Symbol manager, we can read the symbols generated by the assembler, vgmplay.sym, which are quite convenient.
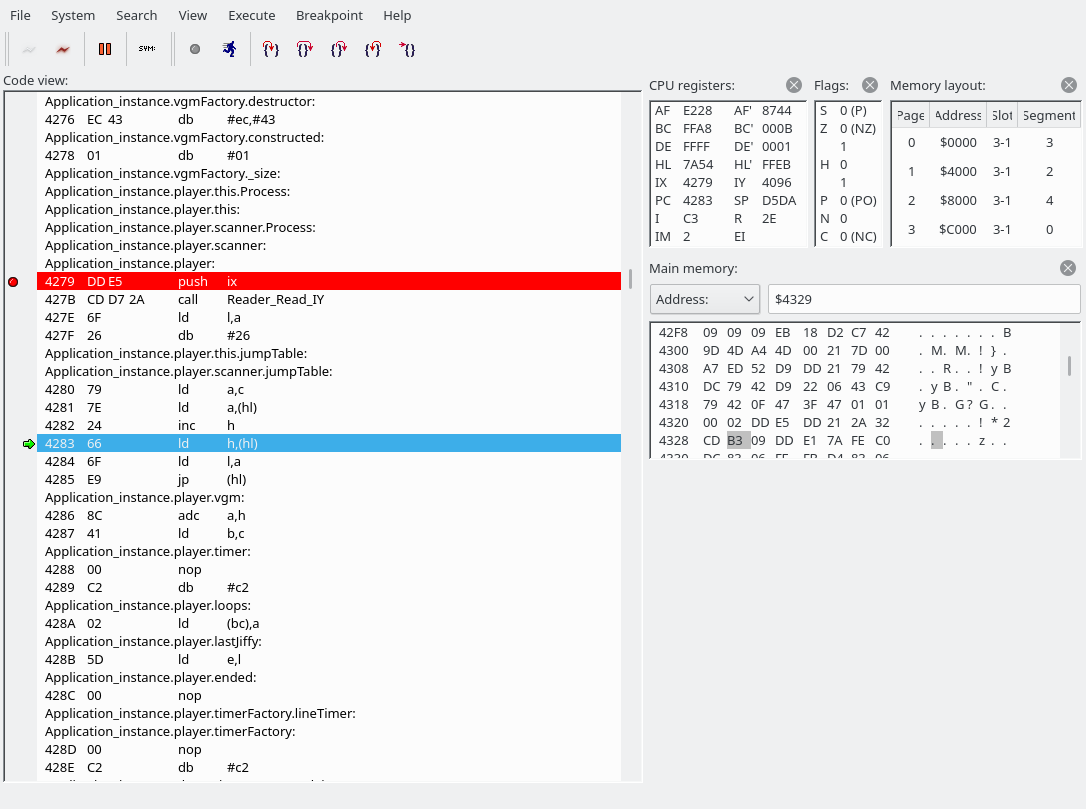
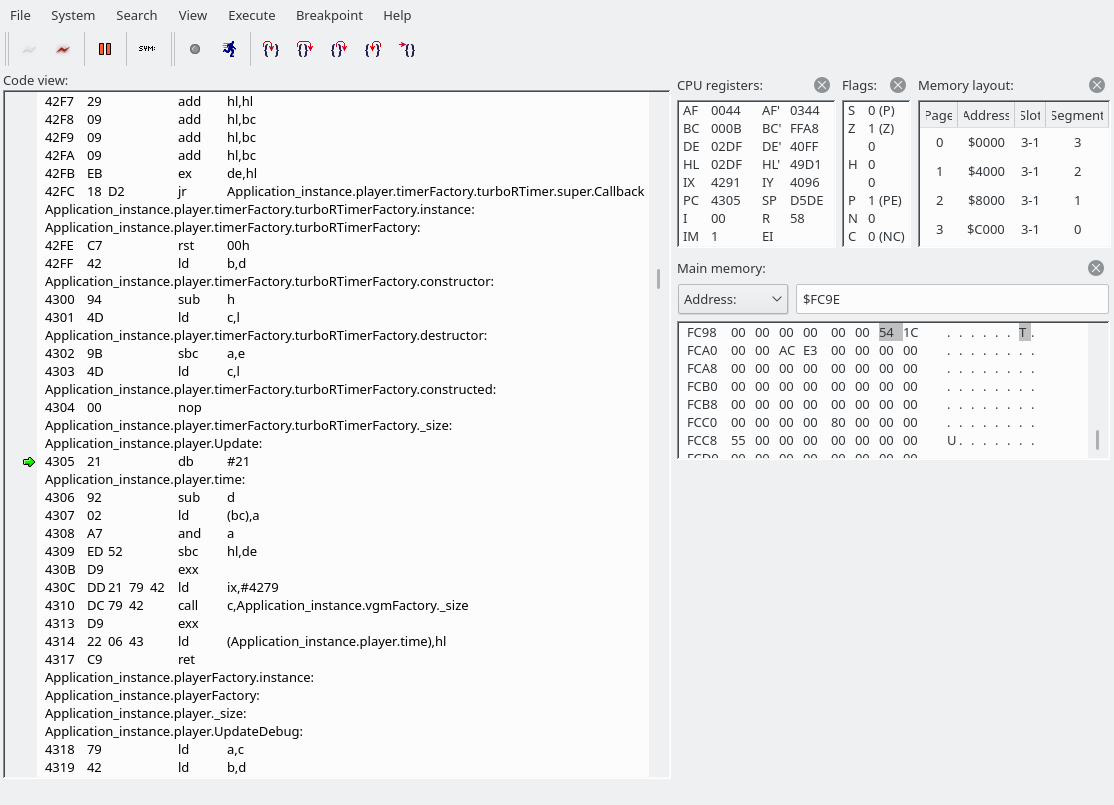
Note: openMSX debugger fails to show the correct disassembly when there is a label in the middle of an instruction. Below, 427F 26 db #26 and 4280 79 ld a,c are actually a single instruction, which you can manually decode using something like this:
Here, in Reader_Read_IY we read a byte from the VGM music data. We then create an address by reading one byte from 79xx (where xx is the read byte) and one byte from 80xx (again, xx is the previously read byte) and jump to it. This is the main jump table.
The jump table is defined in src/Player.asm, and for efficiency reasons is separated into two in Player_InitCommandsJumpTable in the same file.
; Shuffles the commands jump table so that the LSB and MSB are separated.
; This allows faster table value lookups.
Player_InitCommandsJumpTable: PROC
...
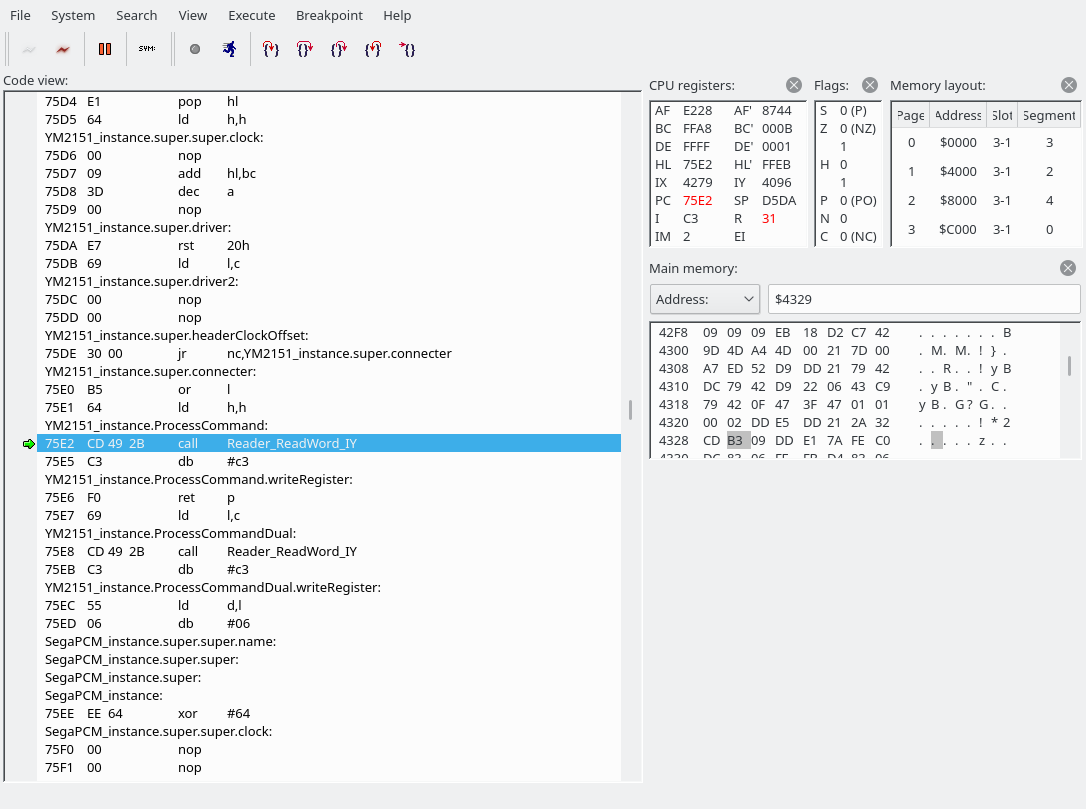
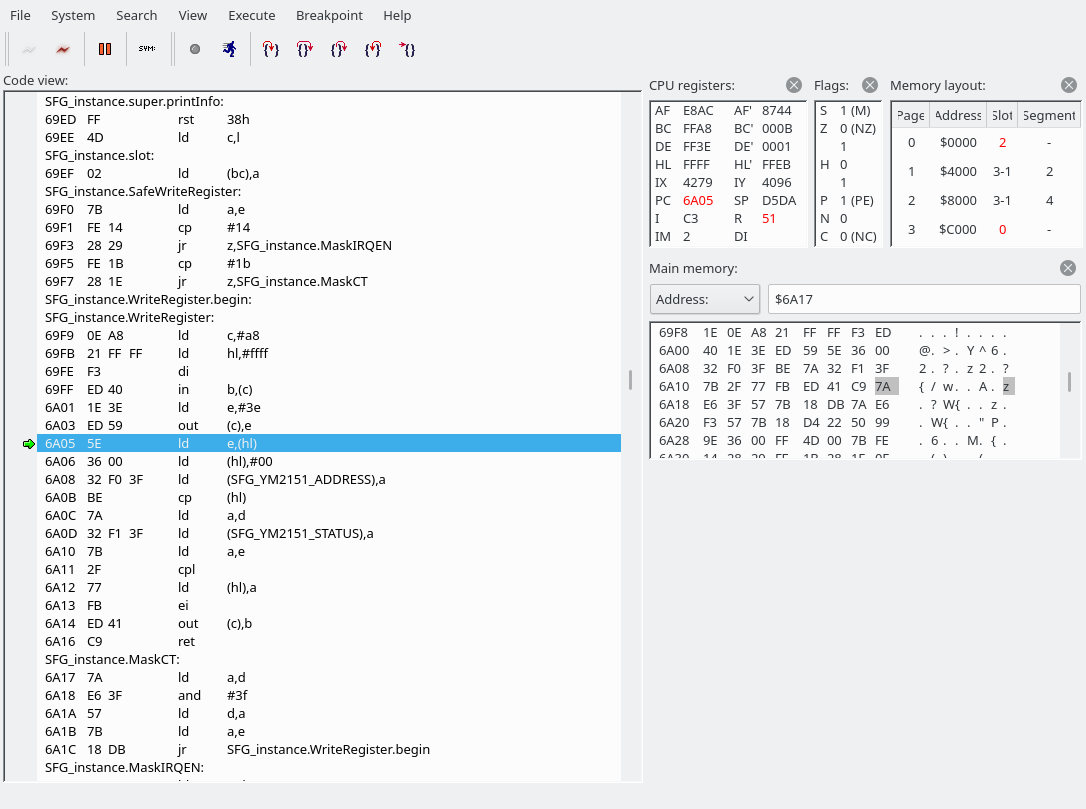
The byte we read was a 0x54, which indicates that we are going to write to the YM2151. This is where we have jumped:
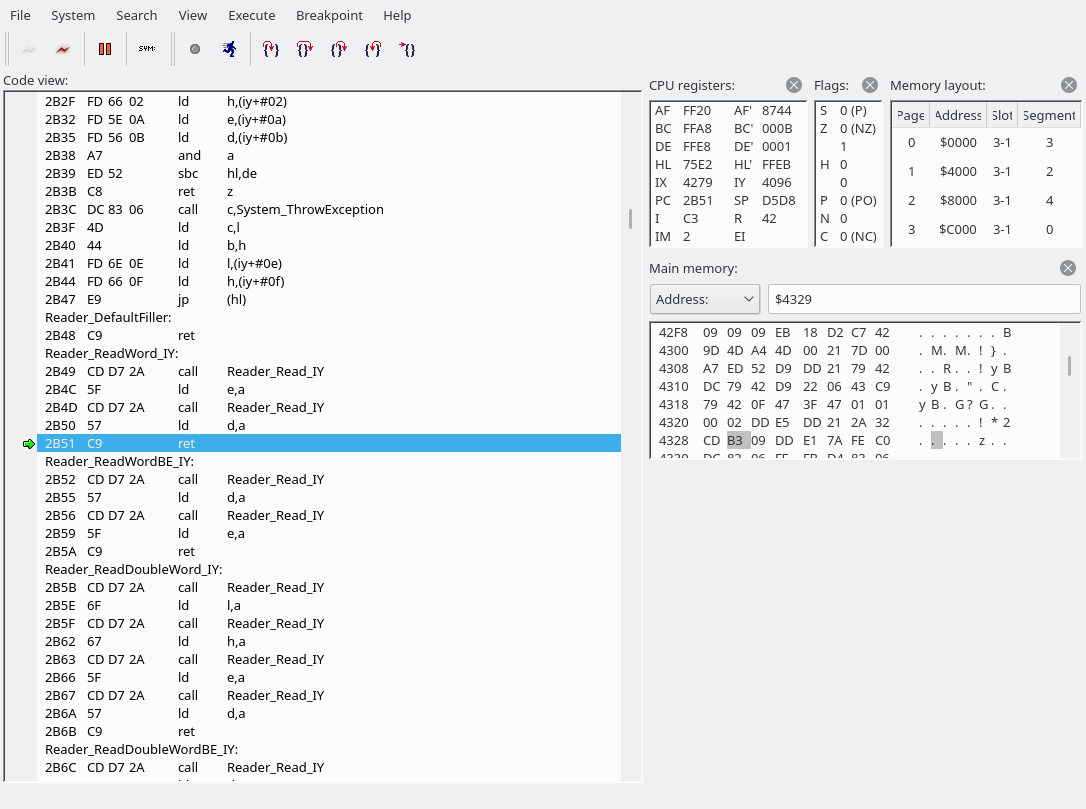
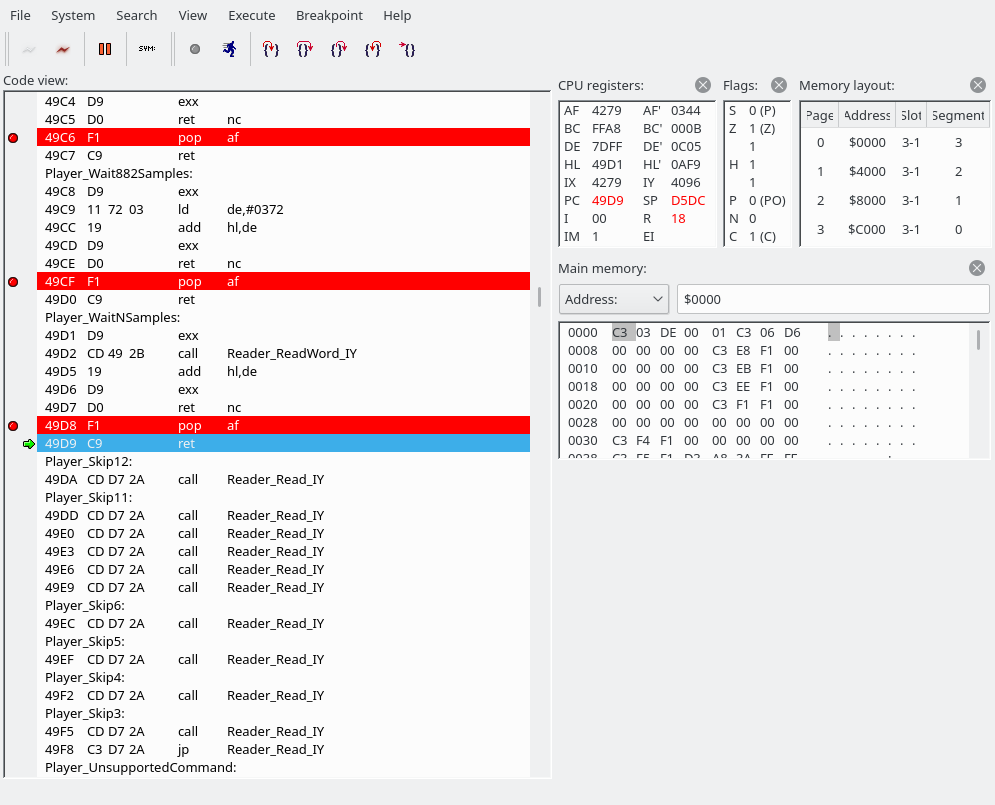
We are going to read a word (two bytes). The first byte holds the address of the YM2151 register to write to, the second byte the data. It looks like the next instruction has been butchered by the openMSX debugger again. C3F069 is actually “JP 69F0”.Reader_ReadWord_IY simply calls Reader_Read_IY twice. (The first screenshot also used Reader_Read_IY to fetch the command byte.) The address goes into the E register, the data into the D register.
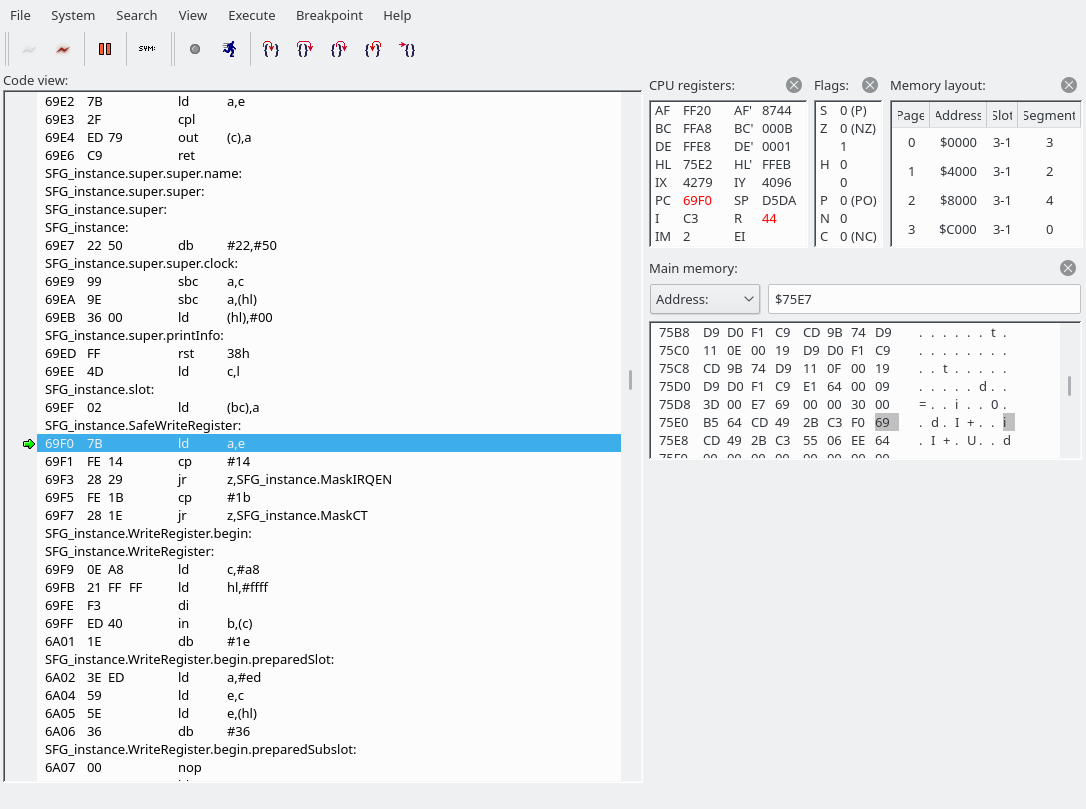
We have now jumped to 69F0. The source file is src/drivers/SFG.asm.
There are a few things to unpack here.
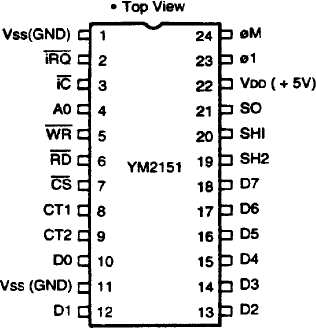
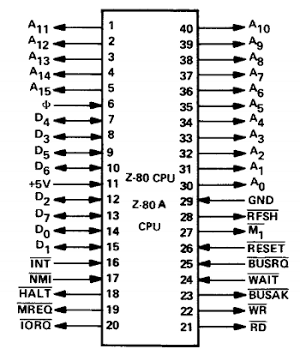
First of all, we look into the address value and may jump to MaskIRQEN or MaskCT if the address is exactly 0x14 or 0x1b, respectively. Our E is set to E8, so that doesn’t apply here, so we fall right through into SFG_instance.WriteRegister. I am going to guess that the MaskIRQEN and MaskCT sections modify some bits in the address register to perhaps turn off a feature in the YM2151 that would trigger output on the interrupt or one of the CT pins, but I don’t know for sure. Here’s a pinout of the YM2151 BTW:
There are IRQ and CT pins, and IIRC they are output pins.
Next, let’s edit the symbol file to work around the debugger’s inability to disassemble instructions that have labels in the middle… Search for ‘6a02’ and ‘6a07’ in the symbol file, remove the symbol file from the debugger, and add it back in again. Then our WriteRegister function becomes a little clearer:
We read from and write to the A8 I/O port. This screenshot is from after executing the OUT instruction, which modifies the slot selection; the modifed slots are highlighted in red in the upper-right corner.
The SFG’s YM2151 registers are memory-mapped(!) at the following addresses:
If you know quite a bit about how the MSX works, you may know that the MSX in general doesn’t use memory-mapped I/O, and you may also know that 0000-3FFF is where the system ROM is usually located (mapped; it can be unmapped and something else can be mapped instead). In the screenshot above, you can see that there’s an “in b,(c)” instruction at 69FF, where C holds #A8. This is the I/O register that allows you to remap stuff. See this link if you want to know more about how this register works: http://map.grauw.nl/resources/msx_io_ports.php#ppi. (BTW, this page is probably authored by the same person who wrote vgmplay-msx.) So “in b,(c)” saves the contents of the #A8 into B.
In order to perform memory-mapped I/O, we have to unmap any ROM or RAM currently mapped in. And when we’re done, we obviously have to map it back in. (Oh, good that we saved the #A8 contents into B.) ROM and RAM mappings vary between MSX models, which means the OUT part of the code is probably generated dynamically somewhere in the init code. (Hence the labels in the middle of our instructions.) The next instructions (6A05 and 6A06) save the contents of the subslot register (FFFF) into E (so we can change it back later) and set the subslot register to 0. (Note that at this point our register address has already been moved into register A, while data is still in register D.)
After the OUT is done, we just write our address to SFG_YM2151_ADDRESS and our data to SFG_YM2151_STATUS (which is an alias of SFG_YM2151_DATA, the address is 100% the same). The “cp (hl)” instruction in the middle is just to wait a short moment according to the comment in the source code: “; R800 wait: ~4 bus cycles”. When we’re done, we set the slot and subslot registers back to what they were.
So that’s how we perform a register write. We also need to know how to wait a specific number of cycles. VGM files are full of wait commands, and if the amount of waiting we do is too imprecise, that will definitely be audible. The wait commands in VGM files assume an output sample rate of 44100 Hz, which is different from the actual sample rate on real hardware. The number specifies the number of samples to just leave the YM2151 alone to do its thing. In reality, the YM2151 in the SFG-01 outputs at 3579545/2/32 = 55930.390… Hz. The Z80 runs at 3579545 Hz. So we get 64 Z80 cycles per sample, but because the VGM file wait cycles assume a different sample rate, just adding NOPs would end up being rather imprecise. What’s more, some VGMs are for machines where the YM2151 is clocked at 4000000 Hz, which results in an output rate of 4000000/2/32 = 62500 Hz.
So let’s… jump back to our jump table to see what happens when a wait instruction is encountered!
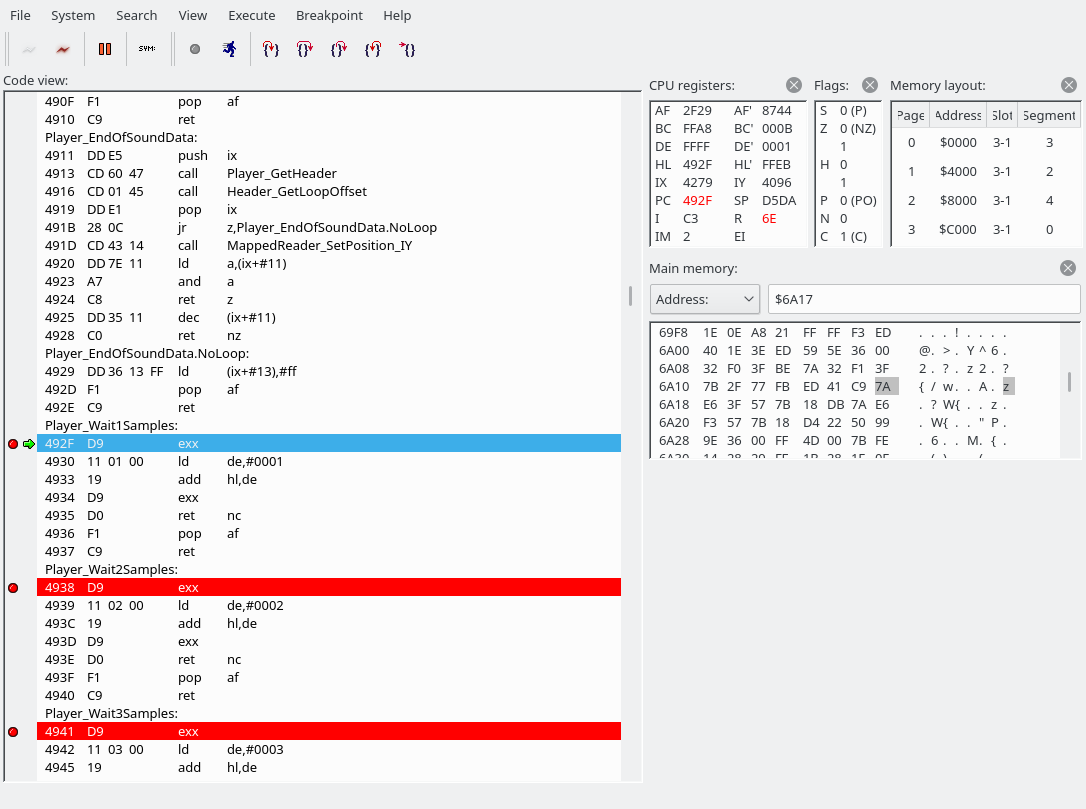
As we can see, there are a lot of commands that perform waits. For Player_Wait1Samples, we jump to 492F:
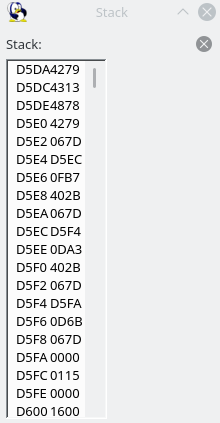
The “exx” instruction switches between the directly usable registers and the shadow registers. (“EXX exchanges BC, DE, and HL with shadow registers BC’, DE’, and HL’.”) Wow, the Z80 has so many registers. All we do here is add 1 to hl’. In a special case, we pop AF from the stack, but we have no choice but to ignore that for now. And basically, Player_Wait2Samples, Player_Wait3Samples, …, Player_Wait16Samples, Player_Wait735Samples, Player_Wait882Samples, all work the same. Player_WaitNSamples grabs its argument, and apart from that also works the same as the others. Here’s a screenshot of the stack, and it’s always the same for all Player_Wait* sections:
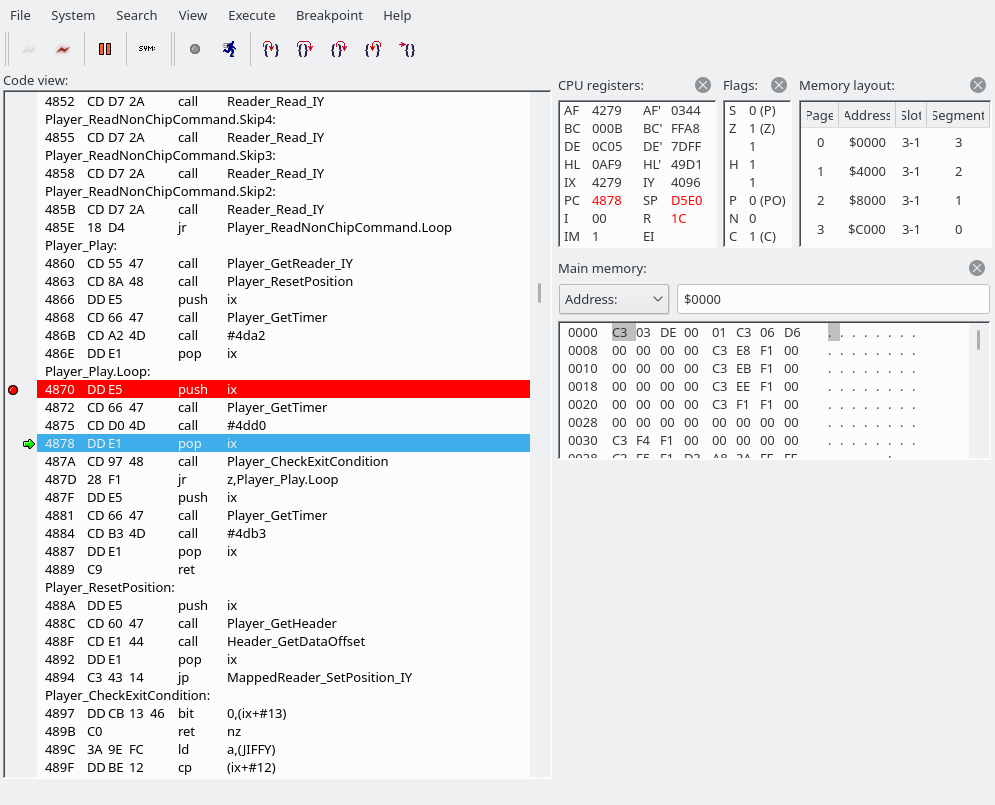
That is, we are going to jump back to 4279, and we have already seen the code at 4279. Scroll up to see it again. It’s our main loop body, where we grab a command and use the jump table to jump somewhere. (What I hadn’t noticed or mentioned above was that it begins with a “push ix” command, which seemingly puts 4279 back on the top of the stack each time.)
Well, this is a good time to think about that “ret nc pop af ret” bit again, right? If the carry flag is set, we do not return. Instead, we grab 4279 off the stack and shove it into the AF register. Then we return, and this time we should return to 4313, according to the above stack screenshot. The carry flag is set if shadow HL overflows. Currently, it’s FF71. Hmm, just a few F9 presses maybe.
Intermission, sort of
But let’s take a step back and think about what we have seen so far. Perhaps the MSX is just way too slow to play VGMs in real time with perfect timing, and it just makes sense to skip all wait commands and just sync whenever the carry flag is set?
There’s a lot of timing code, and it’s all a bit complicated because the code seems very un-assembly-like. (But as this piece of software supports many different configurations, the somewhat object-oriented patterns may maybe make sense.) Looking back at the projects homepage, it appears that on the MSX2, the timing is 300 Hz, so perhaps that means the waits are ignored as they are encountered, but everything is put in sync (up to?) 300 times a second. It looks like on the MSX1 the timing is either 50 or 60 Hz.
The timing resolution is 50 or 60 Hz on MSX1 machines with a TMS9918 VDP, 300 Hz on machines with a V9938 or V9958 VDP, 1130 Hz if a MoonSound or OPL3 is present, and 4000 Hz on MSX turboR.
While the site says that vgmplay-msx works on MSX1 machines, I’m not entirely sure what kind of hardware configuration in e.g. openMSX would allow us to do that, because vgmplay-msx needs 128 KB of RAM, and MSX-DOS2. As far as I know you also can’t give an existing MSX2 machine an MSX1-class TMS9928A VDP, because the MSX2 logo requires the V9938. (Maybe you could try to give it an MSX1 BIOS too, but I think I’m outta here.)
(End of intermission)
So what we’re going to do is: recompile without LineTimer support by commenting out in src/timers/TimerFactory.asm:
TimerFactory_Create:
; call TimerFactory_CreateTurboRTimer ; this line and
; call nc,TimerFactory_CreateOPLTimer ; this line and
; call nc,TimerFactory_CreateLineTimer ; this line.
call nc,TimerFactory_CreateVBlankTimer ; this line is left as-is
ret
So anyway, we’re now running using the VBlankTimer and added breaks like this:
And after the ret we end up here:
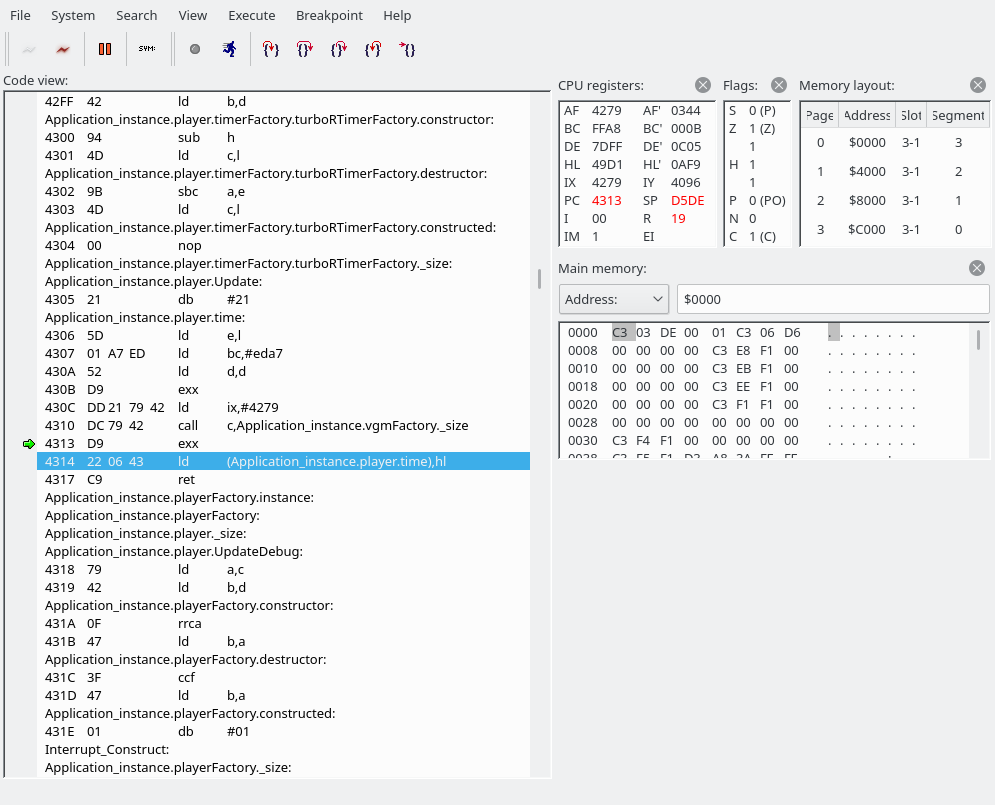
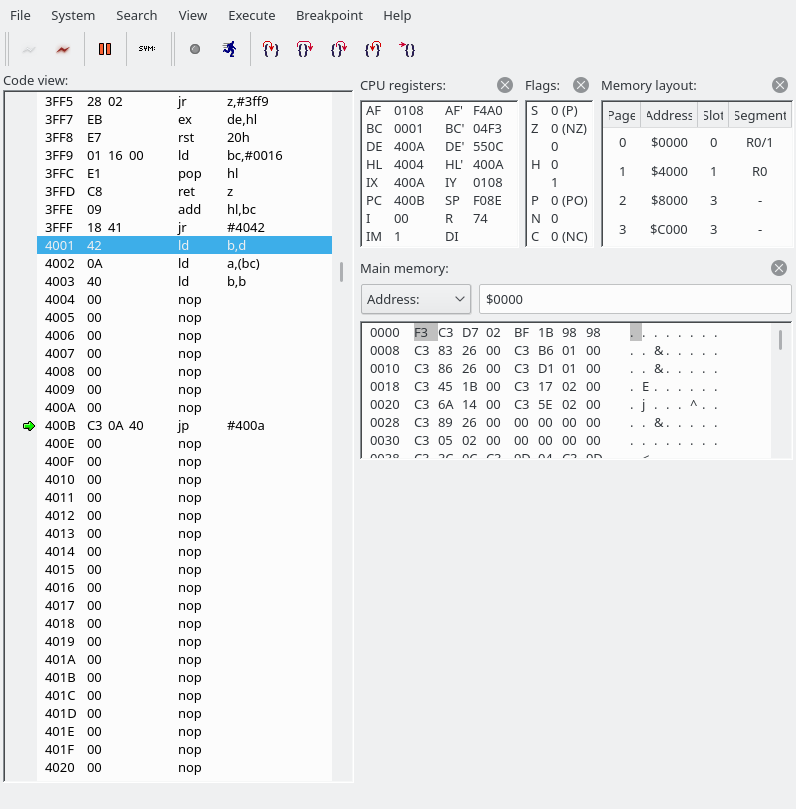
Note that Application_instance.player.time is a variable, not something disassemblablablable.
So what we do here: we save our shadow HL (which has gone past FFFF; it’s currently 0AF9) to a variable called Application_instance.player.time. And after the next ret we’re here:
At some point, we get to “Application_instance.player.timerFactory.vBlankTimer.Update”. Wait, what language is this again?
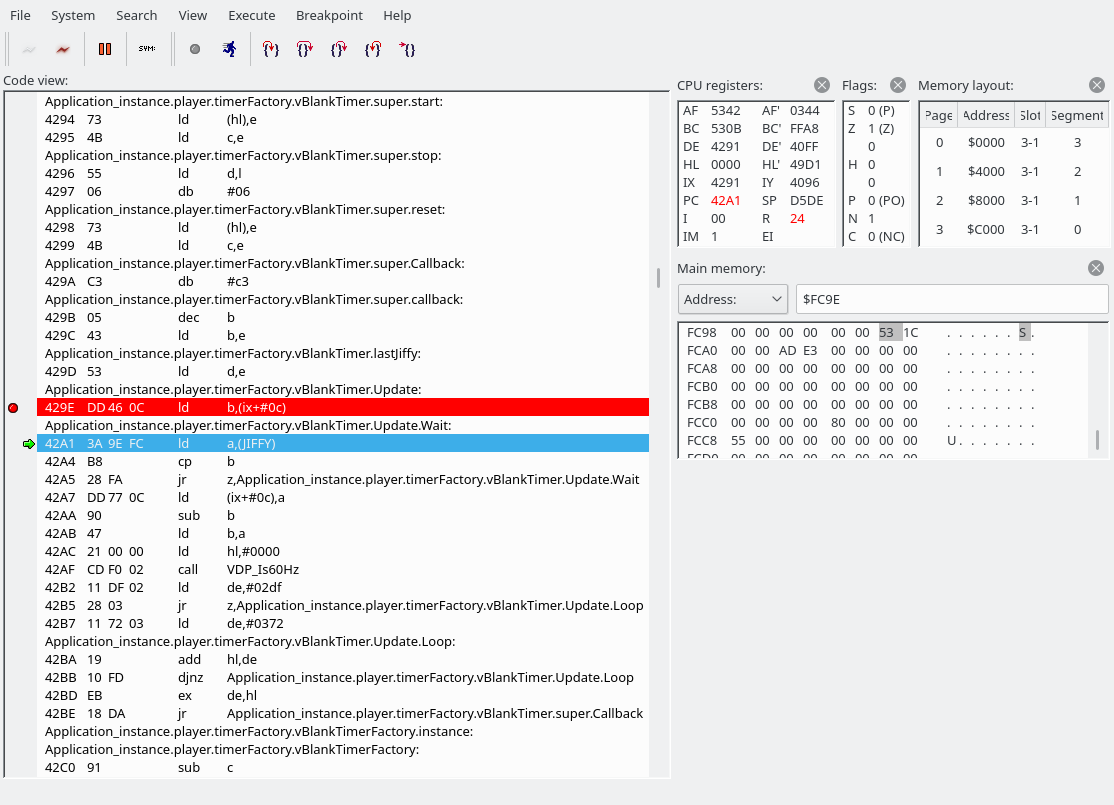
Over here we loop between 42A1 and 42A5 until the JIFFY value contains something different.
Here’s the code with more symbols:
Update: PROC
ld b,(ix + VBlankTimer.lastJiffy)
Wait:
ld a,(JIFFY)
cp b
jr z,Wait
Wait, what’s JIFFY? It’s actually a system variable:
Address: FC9Eh Name: JIFFY Length: 2
Contains value of the software clock, each interrupt of the VDP it is increased by 1. The contents can be read or changed by the function ‘TIME’ or instruction ‘TIME’
After the tight loop is finished, we update lastJiffy with the new JIFFY. Then we set a value for our shadow HL. We either initialize DE with 0x2DF or 0x372 depending on whether we’re on 60 Hz or 50 Hz. (Update: I don’t think this routine works on the MSX1!) Then, we jump to a callback that was set way back when our Timer was first created (i.e., during program initialization), in src/Player.asm:
Actually executing the code we see that we end up in Application_instance.player.Update:
Application_instance.player.time causes the disassembly to look wonky. 4305-4307 loads Application_instance.player.time, currently set to 0292, into the HL register. The next valid instruction is 4308. Also, Application_instance.vgmFactory._size is an alias of Scanner.Process (which is the code we have seen a number of times, where we grab a byte and use the jump table)
We are about to do “sbc hl,de”. The HL register has 0292, DE contains 02DF or 0372, depending on whether the system is 60 Hz or 50 Hz. Note: I don’t think the routine to figure out whether the system is 50 or 60 Hz works on MSX1s.
Address: FFE8h Name: RG09SAV Length: 1
System saves the byte written to the register R#09 here, Used by VDP(10). (MSX2~)
Anyway, I don’t really know where the carry flag that SBC is supposed to take into account comes into play (it’s not set in the code visible in the above screenshot). But anyway, 0292 – 02DF = FFB3. And this is the value we will add numbers to again in the Wait* procedures. Or let’s use our brains just one more time:
There are 0x02DF samples per 60 Hz VSYNC (or 0x0372 samples per 50 Hz VSYNC)
We already “overshot” our previous target by 0x0292 samples in the previous run
We have 0x02DF-0x0292=0x4D samples left until we should wait for VSYNC again
Note: 0x10000-0xFFB3=0x4D
We have now seen enough to take just the parts we need.
What parts do we need?
Jump table
We’ll edit it to remove support for anything but the YM2151 though
We’ll also need the remaining jump locations of course (loop, end of song, wait, etc.)
(Also code to make jump table more efficient)
SFG register writing code
(If possible, also init code to figure out correct slot selection register values.)
Timing code
VSYNC-based timer only
The song data will be directly on the cartridge, so
Let’s do it
For convenience/compatibility with the existing code we will be using the same assembler, Glass, though I don’t think we’ll be using any of its unique features. We won’t be using constructors or a heap, even, but we will use the stack in the same way the existing code is using it.
Cartridge contents are mapped to 4000-7FFF, or if no cartridge was detected at 4000-, then 8000-BFFF. (The MSX BIOS maps in the candidate addresses (starting with 4000-7FFF) and checks for the presence of a header at the beginning of this address space to see check if a cartridge is inserted.) Thus, programs must start like this (I added some useless code in the entry_point that makes it easier to test that this thing is working):
org 4000h ; hex number syntax may differ from assembler to assembler
db "AB" ; all cartridges have this
dw entry_point ; 16-bit absolute pointer
db 00,00,00,00,00,00 ; can be anything probably
entry_point:
nop
jp entry_point
Compilation example if saved as foo.asm:
$ z80asm -o foo.rom foo.asm
$ dd if=/dev/zero of=foo.rom bs=16384 seek=1 count=0 # actually creates a sparse file but that's fine for all intents and purposes
$ hexdump -C foo.rom
00000000 41 42 aa 0f 00 00 00 00 00 00 00 18 fd 00 00 00 |AB..............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001000
The disassembler is (rightly) confused again at 3FFF, but we can see our code and we are indeed executing a NOP and then jumping right back to that NOP, ad infinitum.
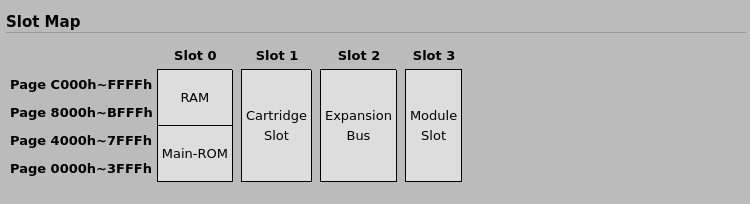
However, we only got our cartridge mapped up to 7FFF, but if we want its whole 48 KB mapped, we need to set port #A8. #A8 of course holds an 8-bit number, but you should interpret it as four 2-bit numbers. “00 00 00 00” (0x00) would mean that everything is on slot 0. “01 01 01 01” (0x55) would mean that everything is on slot 1. You can choose any combination your hardware likes.
All MSXs have Main-ROM in primary slot 0 or in secondary slot 0-0 (see variable EXPTBL below for more details). Cartridge slot that is on top of computer is typically slot 1. If there is another expansion port then this is often slot 2. Although the internal RAM should preferably be in slot 3, this is often not the case for MSX1s.
https://www.msx.org/wiki/Slots
The cartridge slot is “typically slot 1”. I don’t know if there are any computers that have a different number, but it’s easy to determine the number in software: we’re running off 4000-7FFF, so the slot is already set correctly here. We just need to set the page we want to the same number.
Now, if we want to set 4000-FFFF to the cartridge, we won’t have any RAM. And therefore, no stack. vgmplay uses the stack (as seen earlier). vgmplay also uses the BIOS (mapped into 0000-3FFF) because we need the VSYNC interrupt handler, and this interrupt handler writes to a system variable called JIFFY, which is located at FC9E, as mentioned above. We could decide to leave the last slot for RAM, limiting the amount of song data we can play to less than 32 KB. But the amount of RAM we need isn’t exactly very much. In addition, as we have seen, some parts of the vgmplay code are self-modifying.
So what we’ll do instead is: copy the entire cartridge to RAM. Then we’ll be able to use self-modifying code, and we’ll be able to have a stack too. Sounds easy? Well, let’s say we have our copying routine at ROM address 4100. What happens if we try to copy the ROM at 4000-7FFF to RAM? We’ll execute instructions at 4100, and these instructions say to switch 4000-7FFF to RAM, which we do, and then what? We’ll have pulled the carpet from under our feet! One way to avoid this problem is by having two (or more) copies of the copying code.
So first we could copy 8000-BFFF to RAM, which doesn’t require any precautions. For the page starting at C000, we probably shouldn’t copy past F000, which is where the stack and some system variables appear to be located. (Not that the stack holds anything.) But otherwise no precautions are required. Then, we jump to (e.g.) 8100, where we have another copy of our copy routine, and copy 4000-7FFF. (We’ll choose a different location for the second copy because we’d expect the song data to start before 8100. Perhaps F200 or so.) If we copy byte-by-byte (or word-by-word), switching between ROM and RAM every time, we can use a single register to hold the read value and won’t need any buffer memory (which would complicate things a bit). (It finishes in less than 1 second per 16 KB, so no issues here as this is init code.)
One more annoyance is that since we do not have a stack, it doesn’t make a lot of sense to ‘call’ the copy code. Jumping to the code isn’t exactly fun either because we’d have to know where to jump back, and the register dance becomes a little annoying. So we’ll just copy and paste the code. Here’s the first-draft code to copy 4000-F000 from ROM to RAM. This code assumes that the BIOS ROM is in slot 0, the cartridge ROM in slot 1, all RAM in slot 3, and that there are no subslots. This assumption doesn’t hold on many systems. This code can be compiled using z80asm using the following command line:
z80asm -o foo.rom foo.asm
org 4000h
db "AB"
dw entry_point
db 00,00,00,00,00,00
entry_point:
ld a,01010100b ; set rom - cart - cart - cart
out (0a8h),a
; copy 8000-bfff
copy_8000_bfff:
ld hl,08000h ; start at 8000
copy_8000_bfff_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
or 000110000b ; set bits 5-4 to 11 (RAM) (actual value depends on machine)
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 0c0h
jp z,copy_c000_f000 ; done with this copy
jp copy_8000_bfff_loop
copy_c000_f000:
ld hl,0c000h ; start at c000
copy_c000_f000_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
or 011000000b ; set bits 5-4 to 11 (RAM) (actual value depends on machine)
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 0f0h
jp z,copy_4000_7fff ; done with this copy
jp copy_c000_f000_loop
done_copying:
ld a,011111100b ; switch to 4000-ffff to RAM
out (0a8h),a
nop:
nop
jr nop ; infinite loop
seek 0b000h ; b000+4000 = f000
org 0f000h
copy_4000_7fff:
ld hl,04000h ; start at c000
copy_4000_7fff_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
or 000001100b ; set bits 5-4 to 11 (RAM) (actual value depends on machine)
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 080h
jp z,done_copying ; done with this copy
jp copy_4000_7fff_loop
This is pretty almost all that we need to code ourselves, everything else will be copy and pasted from vgmplay-msx! Note: the above doesn’t actually assemble in Glass because Glass requires that reserved words like “org” are indented, and “seek” isn’t supported. The final code will therefore look a bit different.
Putting all the necessary bits together (and throwing out everything else)
I got it to work on an emulated version of my Hitachi H2. (My apologies to the original author of vgmplay. I completely butchered their code.) And right when I start looking at the slot map of the computer I actually intended to run this one (Yamaha YIS-503), I noticed that the silly machine only has 32 KB of RAM, har har har. And (this was expected though not quite to this extent) the slot map is different, so the #a8 port settings will have to adjusted. With 64 KB we could load the whole 48 KB ROM into RAM, but with 32 KB, arranged the way it is, we’ll boot from 8000 and ignore 4000-7FFF. (We could rewrite the self-modifying code to refer to variables in RAM space instead, but unfortunately I’m running out of steam on this project. I’d planned two days and it’s about three days already! :p)
It ended up working on this machine too, of course. Except, I think that openMSX might be putting the SFG-01 into a different slot (2), rather than slot 3 as sort of indicated in the above screenshot. Due to the limited amount of RAM, our music gets truncated even earlier than before. Feel free @ anyone wanting to fix this. TBH, I just want to be able to hear if the music sounds okay or not. (Edit 2023/04/08: I checked on a real YIS-503 and the SFG-01 was indeed in slot 3, so the above screenshot is correct.)
Today’s post is AI-heavy! AI as in OCR (“optical character recognition”). We will OCR (“optical character recognize”) a hex listing for a Prolog interpreter (which used to be thought of as an “AI language”) for the Commodore VIC-20! (As a bonus, some small parts of the tools I made to verify the OCR transcription were written by ChatGPT.)
As you may have heard before, OCRing stuff is error-prone. Ls and Is and 1s being mixed up makes natural language texts annoying to read, and program listings almost useless, because you’ll spend a long time trying to find the error. Why does this take a long time? Because our eyes (and attached circuitry) don’t notice tiny imperfections in a sea of details. However, we are quite good at noticing things that look completely different from the surrounds.
With hex OCR, we really only have to worry about 16 different classes (types of digit). This makes it relatively easy to verify if our OCR is correct (and perform fixes), because we can take our OCR’d digits and temporarily (while remembering their original position) display them all, sorted by class. Like this:
We can easily see that all these are indeed 3s, 4s, and 5s.
Or like this:
We can easily see that there’s a 0 in our list of 6s and a 9 in our list of 7s.
(Note: occasionally, OCR tools will turn a single character into two characters, or the other way round. That kind of problem will require manual edits.)
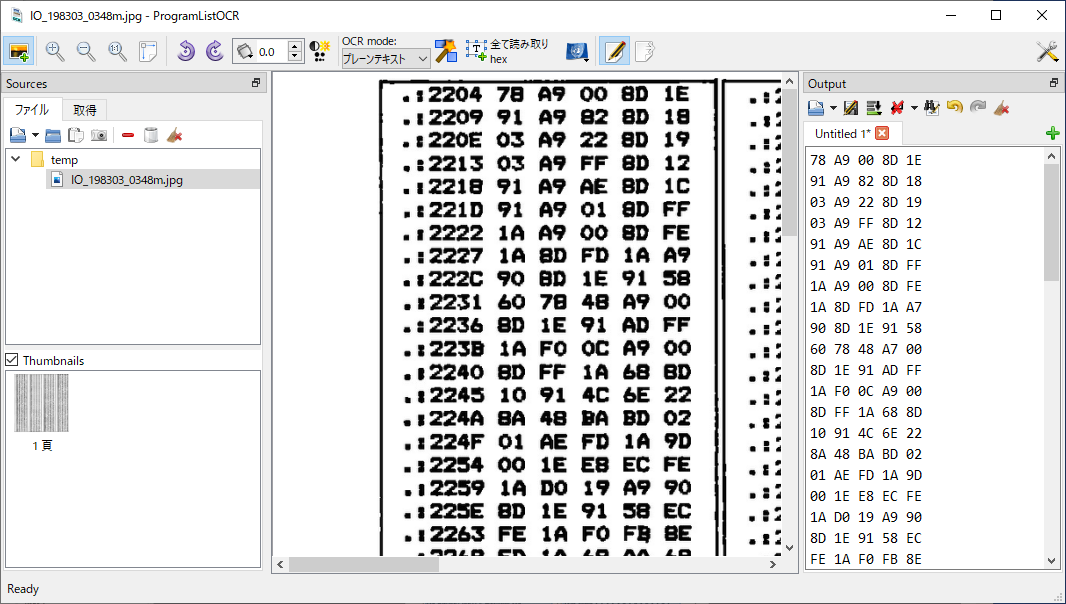
For the original OCR, I used a program called ProgramListOCR. The program supports OCRing hex dumps. This program requires that you touch up input images in (e.g.) Gimp before loading them. It’s not difficult, and the program’s README describes what needs to be done. Unfortunately, this process removes a small amount of detail from the image, making it harder to distinguish between, e.g., Bs and 8s. And unfortunately, I believe the program only runs in Windows. Here’s a screenshot of the program running:
ProgramListOCR made 142 digit mistakes. The hex dump consisted of 7310 digits, so the overall error rate is 1.943%, or the accuracy is 98.057%.
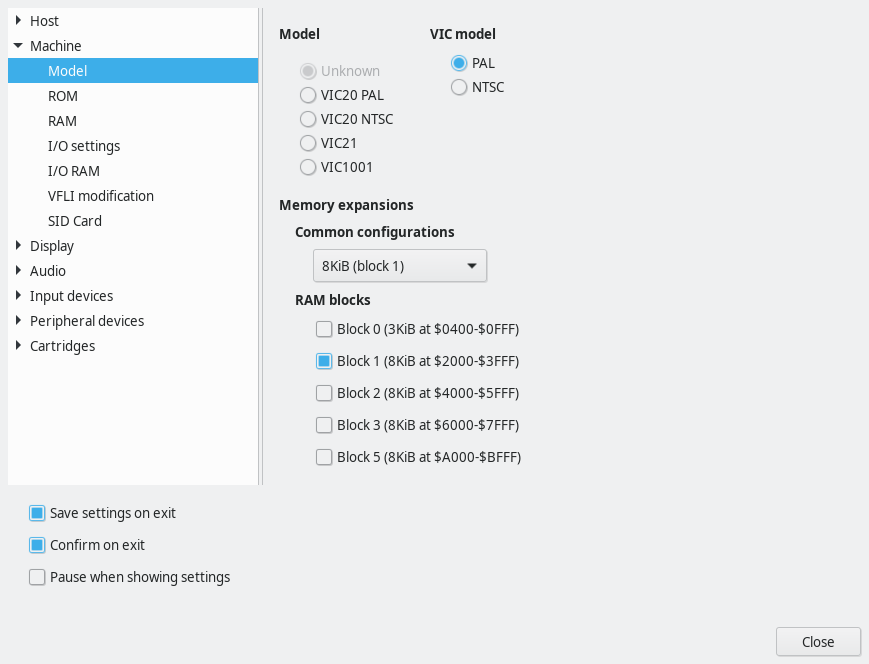
In order to run this on your VIC-20 emulator, you need to set it to have an 8K memory expansion. Then you need to load the binary data into RAM; starting address is 2204. In VICE, you can add the memory expansion in this config window:
Select at least “Block 1 (8KiB at $2000-$3FFF)”. PAL/NTSC etc. do not matter.
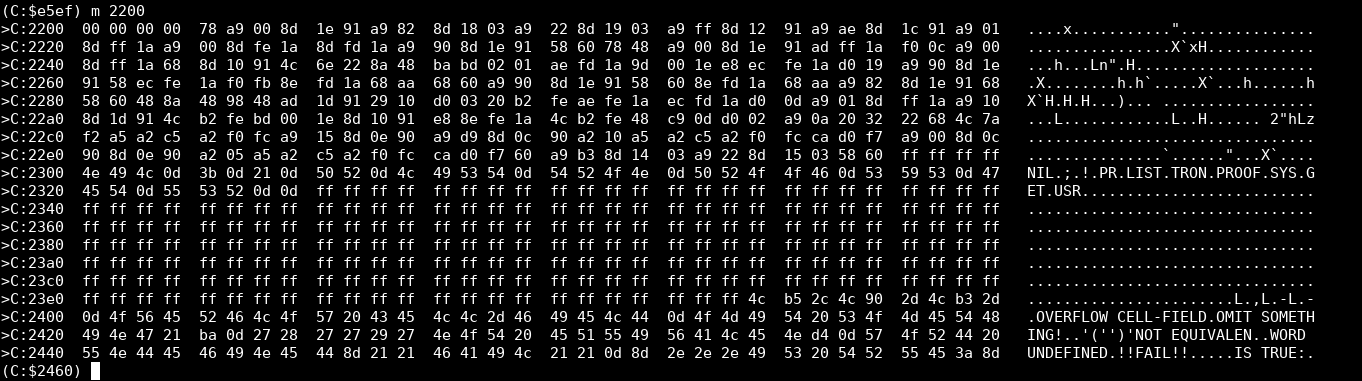
To load the binary data into address $2204 and beyond, start the monitor (Alt+H), and then I wish it’d work with ‘load “/path/to/prolog.bin” 0 2204’. But for some reason that doesn’t work; the first few bytes are garbled and the reset isn’t aligned correctly. If you have this issue, try the other file and ‘load “/path/to/prolog_prefixed_with_zeros.bin” 0 2202’. Execute “m 2200” in the monitor to see if VICE loaded your file into the correct address. The following is an example of a successful load:
2200-2203 don’t matter, 2204- should be 78 a9 00 8d, etc.
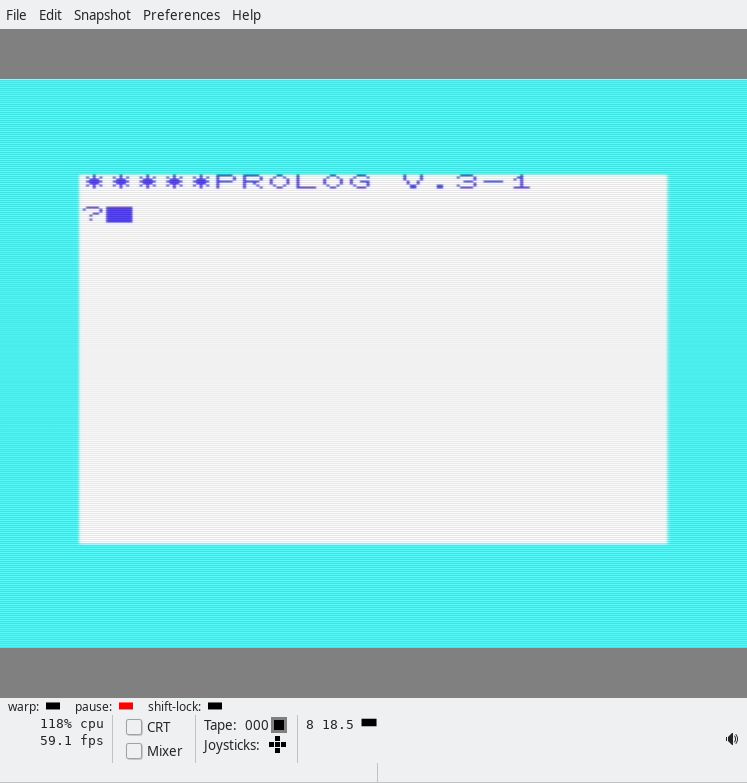
Then you close the monitor and type “SYS 11445” in the BASIC prompt, and you should get something like this:
Having fun with Prolog
There are various sample programs in the magazine. Note that the Prolog interpreter sometimes gives you a question mark prompt, and sometimes a hyphen prompt. You have to delete these manually by pressing backspace (Delete), depending on what you want to do! Let’s start with this short program:
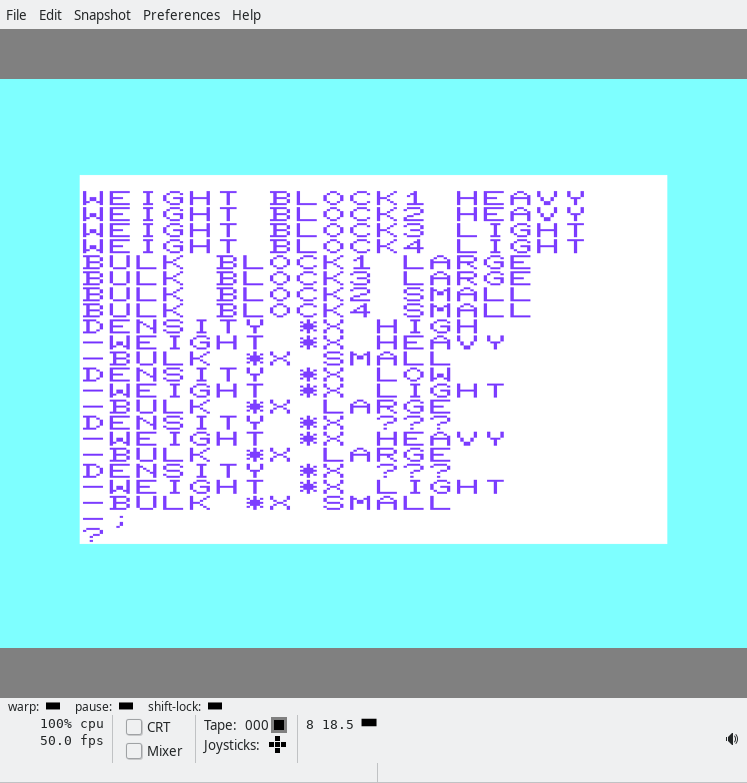
The next program (actually the first in the magazine, and easiest) is a program that tells you whether the density of blocks 1-4 is high or low, or unknown:
That’s the data and the functions, er, I mean predicates.
weight block1 heavy
weight block2 heavy
weight block3 light
weight block4 light
bulk block1 large
bulk block3 large
bulk block2 small
bulk block4 small
density *x high
-weight *x heavy
-bulk *x small
density *x low
-weight *x light
-bulk *x large
density *x ???
-weight *x heavy
-bulk *x large
density *x ???
-weight *x light
-bulk *x small
-;
?
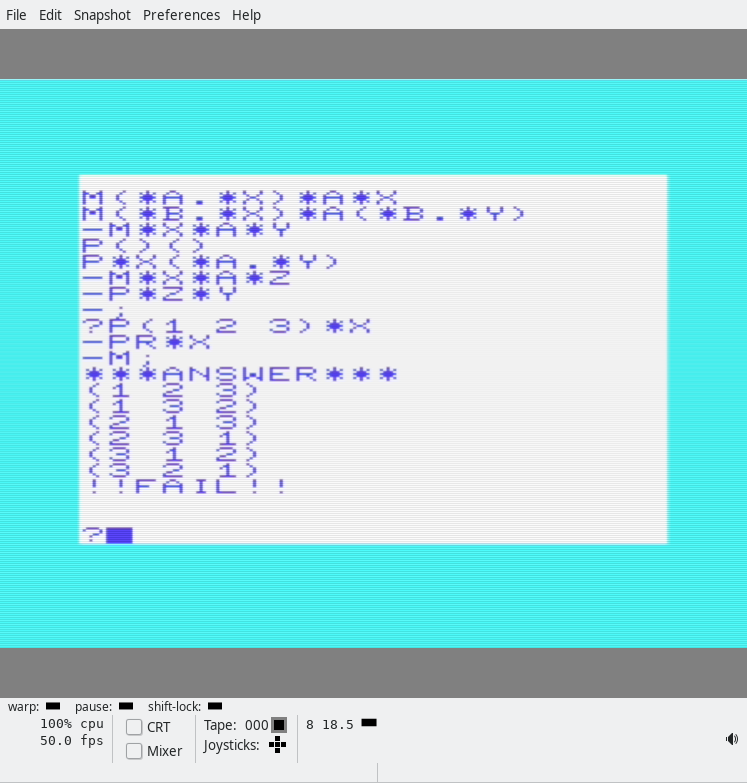
I believe I speak for us all when I say, the syntax looks a bit weird? Anyway, the first few things are the data, er, I means facts. Then you get a function, er, predicate “signature”, and below the predicate signature you get the actual… predicate definition (the lines that start with a hyphen). (Predicates may also be called rules.) Want to finish up the current rules and start a new one with a different signature? Just backspace away the hyphen. When you’re all done, type a semicolon, and you’ll be back at the ‘?’ prompt. Now we can run queries!
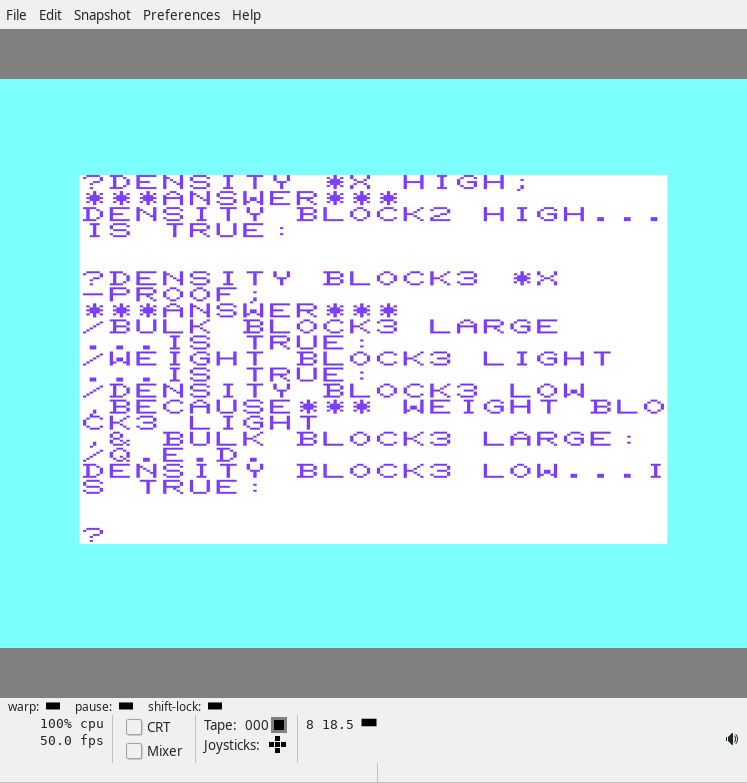
In the screenshot, we first ask which blocks have a high density. The answer is BLOCK2!
Then we ask it the density of BLOCK3 and ask it the reason using the PROOF
Summary: Segmentation tool and OCR verification tool. You can use these tools to either verify an existing OCR’d hex dump, or use them to run your own OCR. (Which isn’t hard! You can probably get ChatGPT to produce a probably working Python script using PyTorch to learn the digits, and easily get 97% (or so) accuracy. Maybe something along the lines of, “Write a Python script that uses PyTorch to train recognition of something like MNIST, except there are 16 classes, not 10. The recognition should use convolutional layers. Input images are PNG files. Labels are in a text file.” (I just tried and the result looks plausible.))
Why hex dumps anyway? Because in the 1980s computer magazines sometimes included printed hex dumps of programs. But that’s just how I got motivated to write these tools. More on that in this post.
If you are familiar with basic image recognition concepts, you may know that detecting hand-written digits is generally considered to be a very easy task, the “hello world” of AI image recognition even. (Didn’t know this? Maybe search for “MNIST dataset”)
If recognizing handwritten digits is considered so easy, recognizing printed digits should be even easier, no? The answer is “yes” and “no”, because I left out some information above. The MNIST dataset consists of images that contain exactly one digit. OCR, on the other hand, requires segmentation. In general, recognizing typed letters if you have them in a nicely cropped single image is quite easy. (Except for letters that look very similar or even identical, of course.) Is segmentation an easy task? Well, there are all kinds of layouts out there. If you want to know more about segmentation, Andrew Ng explained the basics in this and the following few videos: https://www.youtube.com/watch?v=CykIW9hFK24&list=PLLssT5z_DsK-h9vYZkQkYNWcItqhlRJLN&index=108. These videos are part of Andrew Ng’s Machine Learning course on coursera.org, but I can’t find the specific lecture that contained this bit. (tl;dr: basically, you have a pipeline with multiple stages: first you detect regions that vaguely look like text, then a stage that detects if you have a single character or more than one character, and finally a stage that can recognize single characters.)
Performing segmentation on hex dumps and other monospace text is quite easy. However, getting the segmentation wrong can ruin the OCR. Either hardly anything will be recognized, or things will be jumbled up. I played around with Tesseract and a couple other OCR systems but wasn’t able to get good results on hex dumps. Hex dumps have the additional benefit that there are only 16 symbols that need to be recognized. One tool that work pretty well was ProgramListOCR (https://github.com/eighttails/ProgramListOCR). I think it was over 95% accurate with my input images. If it could output the segmentation too, it would be even better, in my opinion.
In this blog post I’m going to describe the tools I linked to above (Segmentation tool and OCR verification tool) and how we can use these tools to get a perfect OCR scan of a hex dump. Because let’s face it… A 99% correct hex dump isn’t all that useful, unless you enjoy sending old CPUs off the rails, or playing spot the difference.
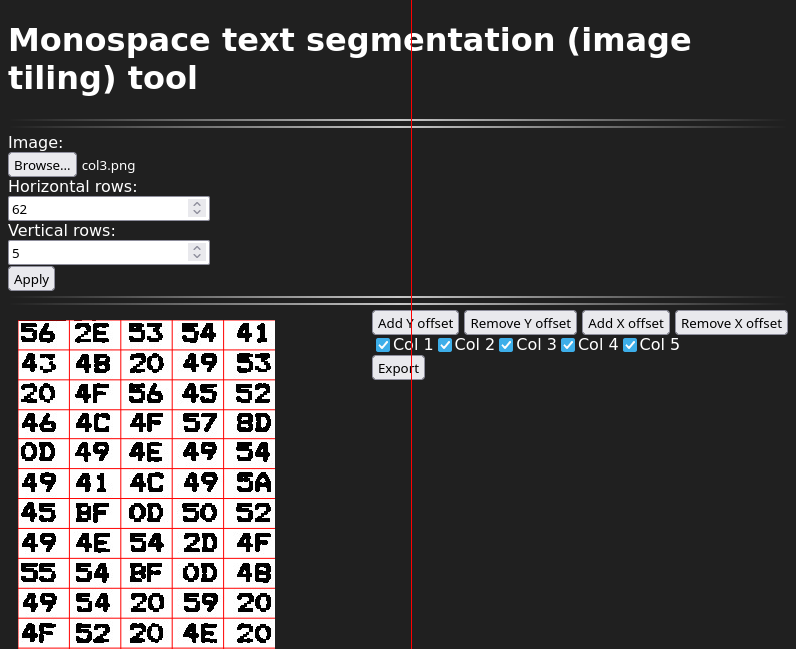
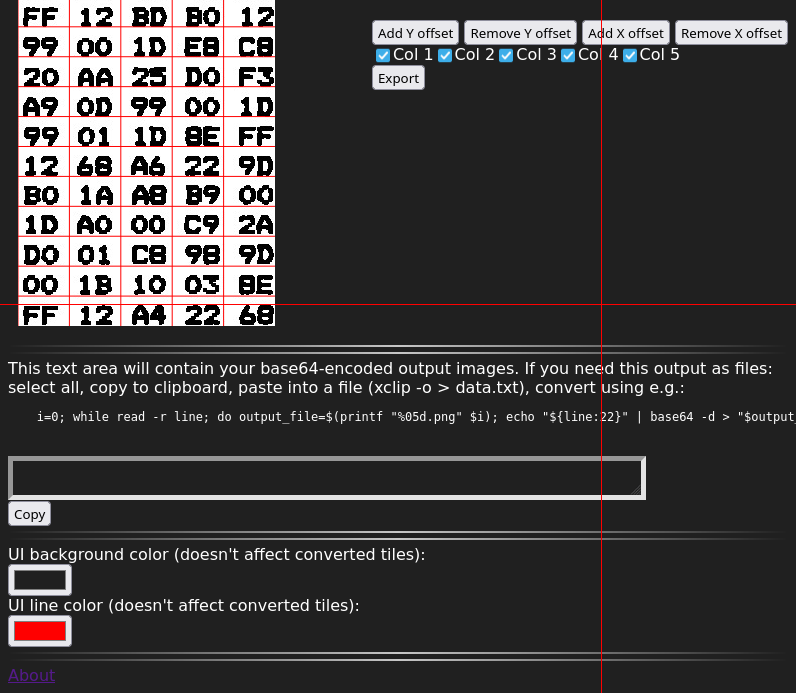
Text segmentation/image tiling tool
The segmentation tools sort of looks like this (at the time of this writing):
Top of page (let’s skip the middle)Bottom
What you can do here is: select an image from a file, specify the number of columns and rows, adjust the rows and columns using the buttons on the right (and then clicking somewhere in the image to that row or column smaller or larger), export to tiles. The adjustment process is best done at high zoom levels (use Ctrl+scroll wheel to zoom). You can also choose to skip certain columns when exporting. You can use the keyboard to do most things. (Cursor keys: move around, space: use current tool at cursor position, T: toggle column export tool, x/X: add/remove X offset tool, y/Y: add/remove Y offset tool.) The tiles will be output into data URLs in the text area at the bottom of the page. You can convert the data URLs back into files using the given shell code snippet. Also reproduced here:
# put contents of clipboard into a file:
xclip -o > data.txt
# convert data URLs in data.txt to PNG files:
i=0; while read -r line; do output_file=$(printf "%05d.png" $i); echo "${line:22}" | base64 -d > "$output_file"; i=$((i+1)); done < data.txt
You can of course also tile into single characters. You’ll just have to fiddle a little more with the offset tools.
OCR verification tool
Here are two screenshots that may help to get some intuition on how to use this tool:
Top of pageBottom
This tool (at the time of this writing) expects as input 1) images as data URLs, to be pasted into the textarea at the top of the page, and 2) the predicted labels corresponding to each image.
The tool then displays the input images sorted into their classes for easy verification by a human. ;) And this is pretty easy for humans, because there are just 16 classes and the human eye is very sensitive to objects that don’t look like the surrounding objects. Here’s another screenshot to demonstrate that it should be easy to find things that look out of place:
The 0 surrounded by 6es and 9 in the cluster of 7s should be pretty easy to spot. (It is also possible that there are Bs surrounded by 8s, but that’s a different topic.)
The web page allows you to drag the images around to put them in the correct category, and to then reconstruct the labels, taking the fixes into account.
Dragging and dropping 9s mis-identified as 7s.
Here’s a more real-world example, with unpolished input images. (If you invest a couple minutes to add/remove offsets in the segmentation tool, you should get slightly better images than this.)
This is one page (around 1/3) of the entire hex dump
The YM3012 IC is a DAC that requires two external op amp circuits and turns a serial digital audio signal consisting of a 10-bit mantissa and 3-bit exponent into an analog signal. (Apparently there is a similar DAC that takes the same input but produces mono output, the YM3014. This would perhaps make this project closer to that one.)
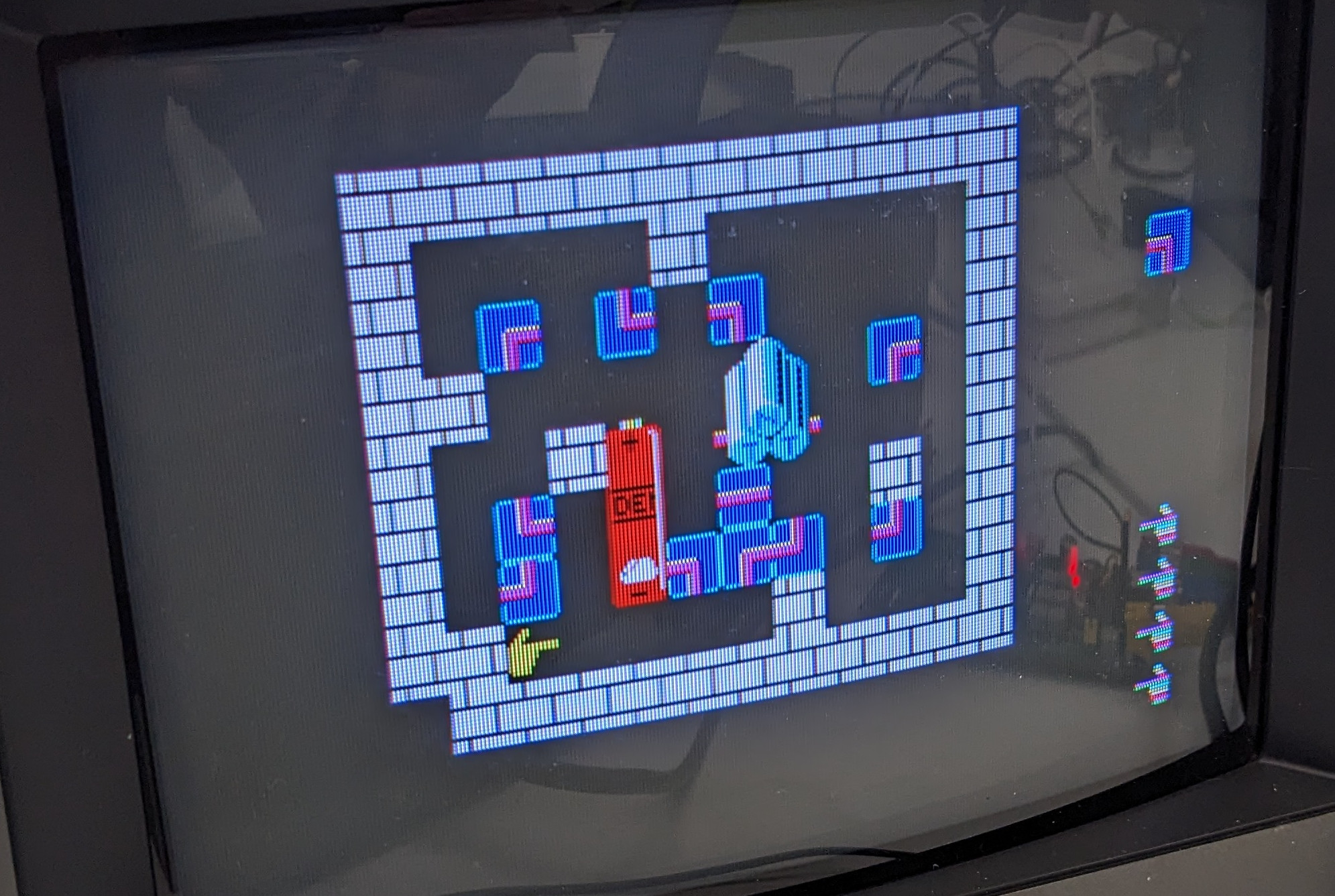
I am currently investigating a fault in an audio module (SFG-01) for certain MSX computers (mostly Yamaha). This audio module is pretty capable and sports a YM2151 FM audio synthesis chip and comes with MIDI input and output ports, a connector for a digital piano keyboard, and software to use the keyboard of course. (I actually never checked if the software is in the module or in the computer.) See this for more information on the SFG-01: https://www.msx.org/wiki/Yamaha_SFG-01.
The fault becomes apparent as soon as two keys are pressed at the same time on the digital piano keyboard. You get a kind of growling/distorted effect. The audio doesn’t sound clean. (Head to the video section below to hear what it sounds like.) My first thought was, that sounds like an analog problem. Aw, I wish. I replaced a couple capacitors without any improvement whatsoever. The removed capacitors all tested fine out-of-circuit, too. A few people said it could be a problem with the op amps. One (relatively) quick way to check if that is the case, is to replace the op amps and try again. But why do it the quick and simple way (with possibly nothing to show at the end) if you can do it the slow and complicated way (with maybe something to show at the end)?
YM3012 pinout
The Raspberry Pi Pico is very good at IO. Not only do we have a lot of pins, but we can read from and write to them very, very fast. However, we aren’t going to go that fast today actually. Neither are we going to be using a lot of pins. In order to build a DAC, we need to read the CLOCK φ1, SD (DATA) and SAM1 and/or SAM2 pins. And then we need output, which in my case is a single pin outputting PWM audio. (It sounds okay, probably not exactly Hi-Fi.) My implementation only reads SAM1 and only outputs a single channel, completely discarding the other channel. It wouldn’t be too hard to get the second channel to work too — the Pico is a dual-core jobby after all, so you could just run the same code on the second core and it’d work. (As there isn’t really a lot of post-processing going on at all, you could most likely even get it to work with just a single core, but I haven’t tried.)
So, in order to test if our DAC, or one of the op amp circuits, or the filter circuits are misbehaving, we just need our Raspberry Pi Pico and check if we’re getting the faulty audio there too. If yes, the DAC is innocent. If no, the DAC or related circuitry would be implicated.
PWM audio
Researching PWM audio on the Pico, I first came across this YouTube video: https://www.youtube.com/watch?v=rwPTpMuvSXg. It turns out, however, that PWM audio is discussed in https://datasheets.raspberrypi.com/rp2040/hardware-design-with-rp2040.pdf, and the creator of the above YouTube video had mostly taken the circuit from there. Basically, you need a medium-sized capacitor to remove the DC bias, some resistors and smaller caps to filter out high-frequency components, and optionally a buffer IC. It’s all right to use a digital buffer IC (I’m using a 74-series logic hex inverter), which then drives the above-mentioned resistors and caps. (The Pico can’t output a lot of current, so I decided to include the buffer, as recommended in the PDF.)
Overview
Since the MSX and its audio module and the keyboard are museum exhibits, and the museum isn’t exactly next door (fortunately not too far away though), I only had limited time to experiment with the original hardware. So what do you do in such a case? Well, I think we all agree that any sane person would immediately head to the internets and check if anyone’s ever implemented the YM2151 (the FM synthesis chip) on an FPGA. (Well, any sane person who owns an unused FPGA. Mine is an UPduino that I bought a couple years ago. They’re actually more expensive now than back then.) As a bonus, if it turns out that the DAC is fine, we should (sometime in the future) be able to hook up our FPGA to the SFG-01 and see if it produces the same weird distorted sound. If it doesn’t, we can be reasonably sure that the YM2151 on the SFG-01 is the one causing the weird sound. (Assuming there are no bad solder joints, etc.)
It turns out that the the YM2151 does indeed exist in the form of Verilog code: https://github.com/jotego/jt51. Amazing! Thank you very much. Impressive. 😳 So all we have to do is:
Put this on our FPGA
Find a way to control the FPGA
Connect the FPGA’s output to our DAC and experiment until it sounds okay
There were many hours spent debugging this. How do you even debug audio that sounds wrong somehow? Well, as with all debugging, you break things up into smaller things that you can actually verify to be correct (or prove incorrect):
Make sure the digital data you are receiving on the Pico is the same as what the FPGA is supposed to be putting on the wire.
Make the FPGA always output the same dummy value. Not the case. The most significant bit is flipped sometimes.
Check if the Pico’s pio_sm_is_rx_fifo_empty() function is lying or something. Yes, looks like it.
Implement a workaround. (More on that later in this post.)
Audio sounds slightly better but overall still crappy.
Forget about the mantissa + exponent algorithms for a second and make the FPGA output straight 16-bit signed PCM.
There’s a hiss but generally speaking it sounds pretty good!
Play around with the PWM audio parameters
Oh wow, the hiss is gone and things sound almost perfect.
Raw PCM audio sounds good, but mantissa + exponent audio still doesn’t.
Make the FPGA output PCM for one sample, and mantissa + exponent of the exact same sample on the next sample.
Put a hexdump in a spreadsheet and see if we can spot the problem. The mantissa + exponent samples should be exactly the same (but with some of the lower bits all 0s), but often they’re somewhat different.
Fix some issues that we introduced in the FPGA code
Output changes continuously and must be latched on the first clock cycle of a new sample
reg/wire confusion
Pico DAC’s mantissa + exponent code was slightly wrong too
The thing mentioned in 1-2 could be a bug in the Pico SDK (or documentation). I’ll probably look into that at some point. The workaround consists of reading from the FIFO twice.
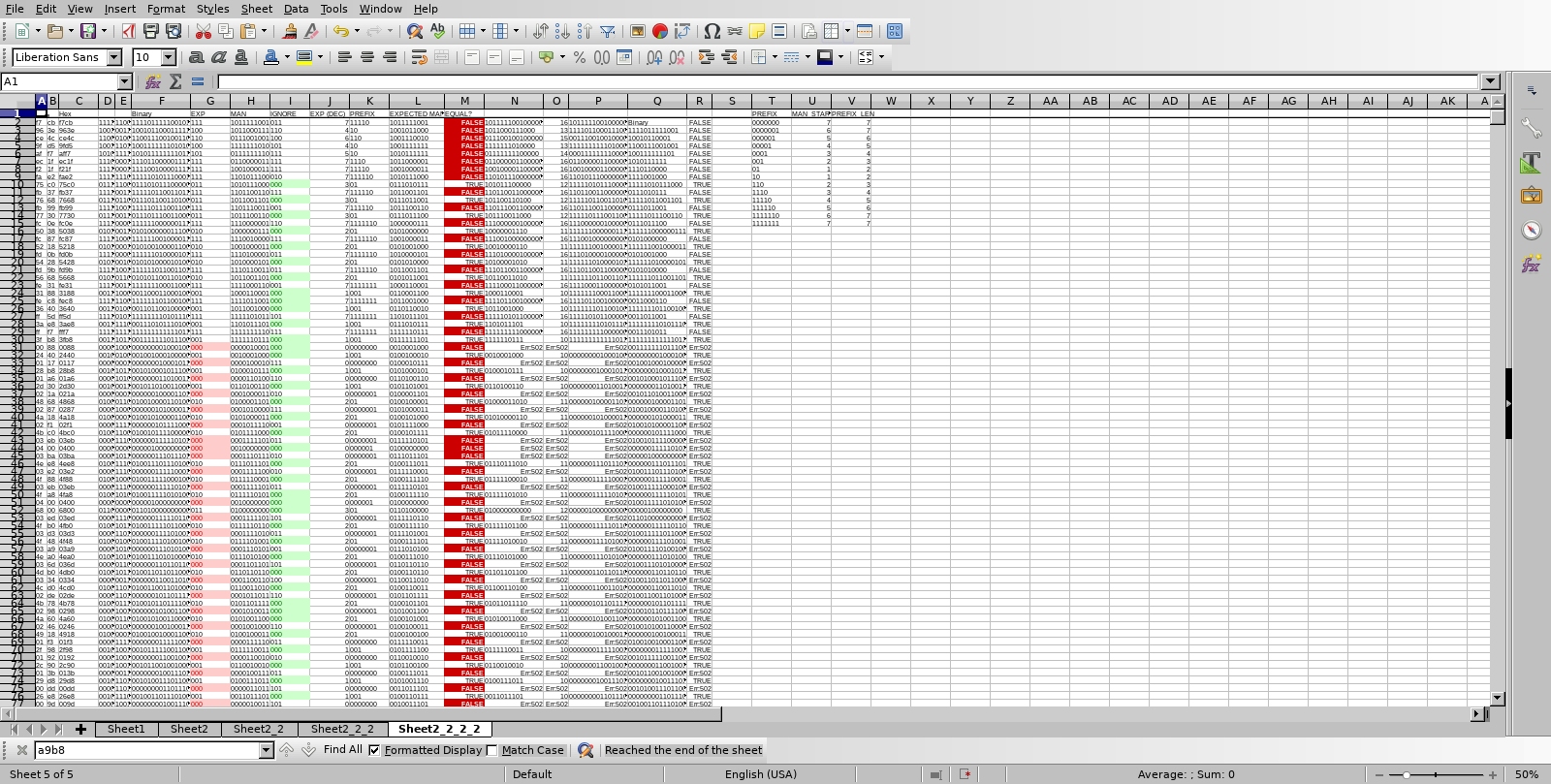
Here’s a screenshot of the aforementioned spreadsheet:
The 2d layout, the conditional formatting, VLOOKUP, string processing functions all make it pretty easy to figure stuff out, in my opinion. YMMV. It would have been helpful if LibreOffice’s HEX2BIN could support more than 8 bits, but 8 bits should be enough for anybody, right?
I also used a tiny script (that I’m including below, just for my own convenience for when I need to get back to something related) to convert a hex dump into audio, using xxd and sox:
#!/bin/bash
# assumes a log file generated e.g. like this: minicom -C sample_dump1.log -D /dev/ttyACM0
tail -n +2 $1 > $1.trunc # get rid of hello world debug output
xxd -p -r $1.trunc > $1.trunc.raw
sox -c 1 -r 62000 -t u16 $1.trunc.raw -b 16 -e signed-integer $1.trunc.wav
Pic/audio/video
JT51 running on the UPduino, RaspiPicoVGM running on a Pico (top right) pico_ym3012 running on a Pico (top left)
I obtained a VGM for the YM2151 from this page: https://vgmrips.net/packs/pack/fantasy-zone-ii-dx-sega-system-16c. I chose “10 Years After ~ Cama-Ternya [Demo]”, and converted this from VGM to a header file for use with RaspiPicoVGM using xxd -i. Below is some audio of this VGM being played back using the above pictured setup. Note that it isn’t perfect, most likely due some issues on the FPGA side:
Played on JT51 controlled by RaspiPicoVGM, DAC’d by ym3012_dac
The below video shows the pico_ym3012 connected to the SFG-01 using tiny test clips, fully reproducing the growling/distorted sound that is the source of this whole investigation.
Verilog lessons learned
If you have a `define in one file and an `ifdef in another file, that `ifdef could very well evaluate as true.
Latching is pretty important
Executing always blocks on the correct conditions is pretty important
The synthesis tool won’t always catch wire vs. reg mistakes
Verilator will catch some things that yosys will just interpret in the probably correct way
The code
The code is also available at https://github.com/qiqitori/pico_ym3012/. License is GPLv3 for ten years after release. If there is no update saying something to the contrary, consider it public domain. I have only reproduced the major bits below.
ym3012_dac.c:
#include <stdio.h>
#include "pico/stdlib.h"
#include "pico/multicore.h"
#include "hardware/pio.h"
#include "hardware/uart.h"
#include "hardware/pwm.h"
#include "ym3012_dac.pio.h"
#include "hardware/irq.h" // interrupts
#define PIN_BASE 0
#define AUDIO_PIN 28
// #define DEBUG 1
// #define JT51 1
#ifdef JT51
#define DESIRED_SAMPLE_RATE 62000 // 4 MHz VGM
#else
#define DESIRED_SAMPLE_RATE 57000 // 315/88 MHz / 2 / 32
#endif
uint16_t samples[110000] = { 0 };
uint16_t last_sample;
int main() {
#ifdef DEBUG
stdio_init_all();
sleep_ms(5000);
printf("Hello world\n");
#endif
// Init PWM for audio out
gpio_set_function(AUDIO_PIN, GPIO_FUNC_PWM);
int audio_pin_slice = pwm_gpio_to_slice_num(AUDIO_PIN);
// Setup PWM for audio output
// We run at around 125 MHz. If we set the pwm counter's top value (== wrap value) to 8192 (generally, bigger is better), the pwm counter can reach the top value 15258.7890625 times per second, which would be our effective sample rate. (Calculation: 125000000/8192)
// However, our target sample rate is larger than that. Let's say if we wanted 44100 Hz: 125000000/44100 = 2834.46712018, so that's the max top value we should set.
// However, our target sample rate is even larger than that. Let's say we want 60 KHz. Then the max top value is 2083.33333333.
// In that case, our samples' max loudness should be about half that, 1041.66666667.
// That's pretty close to 1024. That's good.
// Let's not hard-code this but calculate based on the desired sample rate.
// Note that the desired sample rate depends on the VGM tune played.
uint16_t pwm_wrap = clock_get_hz(clk_sys)/DESIRED_SAMPLE_RATE-24; // TODO: Check if -24 actually improves anything (original intent is to buy microcontroller some time to move to the next sample -- if we don't have enough time, pwm_set_gpio_level might not make it in time and the entire next PWM cycle would be played using the level of the previous sample. I think so anyway.)
pwm_config config = pwm_get_default_config();
pwm_config_set_clkdiv(&config, 1.0f);
pwm_config_set_wrap(&config, pwm_wrap);
pwm_set_gpio_level(AUDIO_PIN, 0);
// pwm_set_phase_correct(audio_pin_slice, true); // TODO: maybe test if this changes anything?
pwm_init(audio_pin_slice, &config, true);
// Init state machine for PIO
PIO pio = pio0;
uint sm = 0;
uint offset = pio_add_program(pio, &ym3012_dac_program);
ym3012_dac_init(pio, sm, offset, PIN_BASE);
#ifdef DEBUG
for (int j = 0; j < 15; j++) {
for (int i = 0; i < 110000; i++) {
samples[i] = ym3012_dac_get_sample(pio, sm);
}
for (int i = 0; i < 110000; i+=8) {
printf("%04x %04x %04x %04x %04x %04x %04x %04x\n", samples[i], samples[i+1], samples[i+2], samples[i+3], samples[i+4], samples[i+5], samples[i+6], samples[i+7]);
}
}
#else
while (true) {
last_sample = ym3012_dac_get_sample(pio, sm); // same as above
// printf("%04x\n", last_sample);
last_sample = last_sample >> 5;
pwm_set_gpio_level(AUDIO_PIN, last_sample);
}
#endif
}
ym3012_dac.pio:
.program ym3012_dac
; // WARNING you need to switch between JT51/YM2151/PCM code yourself by commenting/uncommenting the relevant PIO code blocks below!
; for man+exp (YM2151):
set x, 12 ; Preload bit counter, delay until eye of first data bit
wait 1 pin 1 ; Wait for SAM HIGH // WARNING WARNING WARNING WARNING WARNING WARNING WARNING WARNING change required on JT51: wait 0 pin 1
wait 0 pin 1 ; Wait for SAM LOW // WARNING WARNING WARNING WARNING WARNING WARNING WARNING WARNING change required on JT51: wait 1 pin 1
; ignore first three bits, as specified in data sheet
wait 1 pin 2 ; Wait for clock HIGH
wait 0 pin 2 ; Wait for clock LOW
wait 1 pin 2 ; Wait for clock HIGH
wait 0 pin 2 ; Wait for clock LOW
wait 1 pin 2 ; Wait for clock HIGH
bitloop: ; Loop x times
wait 0 pin 2 ; Wait for clock LOW
wait 1 pin 2 ; Wait for clock HIGH
in pins, 1 ; Sample data
jmp x-- bitloop ;
; for JT51 linear signed 16-bit PCM:
; for linear s16:
; set x, 15 ; Preload bit counter
; wait 0 pin 1 ; Wait for SAM HIGH
; wait 1 pin 1 ; Wait for SAM LOW
;bitloop: ; Execute following code x+1 times
; wait 1 pin 2 ; Wait for clock HIGH
; in pins, 1 ; Sample data
; wait 0 pin 2 ; Wait for clock LOW
; jmp x-- bitloop ;
% c-sdk {
#include "hardware/clocks.h"
#include "hardware/gpio.h"
// #define YM3012_CLK 2000000 // for 4 MHz tunes
#define YM3012_CLK 1790000 // SFG-01 runs at NTSC speed
#define CLK_MULTIPLIER 8 // we need to run faster because we do "wait 1"/"wait 0"s for every transition in PIO code (and have some other extra instructions too)
#define NEGATE_EXP 1
// #define LINEAR_PCM_S16_INPUT 1
// #define DEBUG 1
static inline void ym3012_dac_init(PIO pio, uint sm, uint offset, uint pin_base) {
pio_sm_set_consecutive_pindirs(pio, sm, pin_base, 3, false);
pio_gpio_init(pio, pin_base);
pio_sm_config c = ym3012_dac_program_get_default_config(offset);
sm_config_set_in_pins(&c, pin_base);
// Shift existing values to the right when new value comes in
// The YM3012 receives D0 first, which is the least significant bit
#if LINEAR_PCM_S16_INPUT
sm_config_set_in_shift(&c, true, true, 16); // signed 16-bit linear, shift to right
#else
sm_config_set_in_shift(&c, true, true, 13); // man+exp, 10+3 bits, shift to right
#endif
sm_config_set_fifo_join(&c, PIO_FIFO_JOIN_RX); // appears to be necessary??
float div = (float)clock_get_hz(clk_sys) / (YM3012_CLK*8); // TODO: 4 * actual clock rate would be nice // "For example, the YM2151 internally divides the clock by 2, and has 32 operators to iterate through. Thus, for a nominal input clock of 3.58MHz, you end up at around a 55.9kHz sample rate." https://github.com/aaronsgiles/ymfm/blob/main/README.md
sm_config_set_clkdiv(&c, div);
pio_sm_init(pio, sm, offset, &c);
pio_sm_set_enabled(pio, sm, true);
}
static inline uint16_t ym3012_dac_get_sample(PIO pio, uint sm) {
// 10-bit read from the FIFO (data is left-justified)
uint16_t data_and_exp, data, result, leading_ones;
uint8_t exp;
io_rw_32 *rxfifo_shift = (io_rw_32*)&(pio->rxf[sm]);
while (pio_sm_is_rx_fifo_empty(pio, sm))
tight_loop_contents();
uint16_t rxfifo_contents = *rxfifo_shift; // HACK. If we don't read this twice we may get a stale?? value with the last bit sometimes missing. (HOWEVER reading thrice we get something stale again. Though maybe we're just a little late when reading the third time?) (see example below)
#ifdef LINEAR_PCM_S16_INPUT
#ifdef DEBUG
return (uint16_t)((int16_t)(*rxfifo_shift >> 16)); // don't want that ugly offset when we're debugging
#else
return (uint16_t)((int16_t)(*rxfifo_shift >> 16)+32768);
#endif // DEBUG
#else // !LINEAR_PCM_S16_INPUT:
data_and_exp = (uint16_t)(*rxfifo_shift >> 19);
#ifdef NEGATE_EXP // not needed on JT51
exp = ~((data_and_exp) >> 10) & 0b111; // top 3 bits, negated
#else
exp = ((data_and_exp >> 10) & 0b111); // top 3 bits
#endif
data = data_and_exp & 0b1111111111; // lower 10 bits
if (exp == 0) { // probably doesn't happen on the JT51 at least, and shouldn't happen on YM2151 according to datasheet
result = 0; // according to jt51_exp2lin.v
} else {
#ifdef JT51
result = (data << (exp-1));
// For signed numbers (first bit of mantissa is 1) we need to sign extend by adding a bunch of ones.
// The number of ones to be added is: 16 (because uint16_t) - (left_shift_amount (== exp-1) + 10 (mantissa length)).
// We can create a value with the specified number of leading ones by left shifting a value that is all ones.
// We need to shift by (16-number_of_desired_leading_ones) (e.g., 0xffff with 16 leading ones can only be achieved by left shifting by 0).
// 16 - (16-((exp-1)+10)) = 16 - (16 - (exp-1) - 10) = 0 - -(exp-1) - -10 = (exp-1) + 10 = exp + 9
leading_ones = 0xffff << ((exp-1) + 10);
if (data & (1<<9)) // test for first bit of mantissa
result |= leading_ones; // add leading ones
result = (int16_t)result + 32768;
#else
result = data << 6;
result = result / (2<<(exp-1));
#endif
}
// related to above HACK:
// example output of below printf demonstrating the stale output when reading the first and third times
// first read: 0
// third read: 715653120 or 2863136768
// second read (>> 19): always 5461
// 0 715653120 5461 341 2 170
// 0 2863136768 5461 341 2 170
// 0 2863136768 5461 341 2 170
// 0 715653120 5461 341 2 170
// 0 2863136768 5461 341 2 170
// 0 2863136768 5461 341 2 170
// 0 715653120 5461 341 2 170
// 0 715653120 5461 341 2 170
// 0 715653120 5461 341 2 170
// 0 2863136768 5461 341 2 170
// printf("%u %u %u %u %u %u\n", rxfifo_contents, *rxfifo_shift, data_and_exp, data, exp, result);
return result;
#endif // LINEAR_PCM_S16_INPUT
}
%}
The scaffolding is basically the same as usual. See the Github repository for details.
I like Sokoban. A while ago, I saw someone play a Sokoban-like game called T.N.T. Bomb Bomb on a Sharp MZ-1500. I wanted it and almost immediately headed to the internets to find a disk image or ROM or whatever of it. And while I could find references and YouTube videos, I couldn’t find anything playable. (Note 1: me not being able to find the ROM doesn’t mean that it really doesn’t exist, of course. In fact, maybe this isn’t the first clone of these levels either. Note 2: it is likely that this copy of the game will be properly dumped in the near future.)
Fortunately, the game is partially implemented in BASIC. Which means you could just press Shift+Break and type LIST whenever you wanted! Then you could very easily modify variables and type RUN and play with extra lives or whatever. In my case, I just wanted a picture of every level, so I added a line (line 5) to specify the level to show, hit RUN, and took a picture. Here’s an example:
Hitting enter in this state will render level 4.
(As you can see, the graphics remain on screen after breaking, and sometimes the listing is difficult to see because of this. The graphics can be cleared by executing INIT “CRT:I” in BASIC, but that will cause rendering of the next level to fail.)
It looked like I got correct views of levels 1-10, and I have added these into my JavaScript clone of the game. Levels 11-20, on the other hand, instead of displaying the level number, displayed a game tile (a wire or part of the battery) inside the upper-right corner of the screen. I have therefore not added these levels to my implementation.
Level 1, original game
My very analog way of copying levels into my clone: 1) look at picture like the one above, 2) type out an array like this:
(In reality I added the commas after the fact, using a single find and replace operation. I think it took an hour or two for 10 levels.)
The original game has a concept of “lives”, but I don’t think this is a valuable concept in a Sokoban-like game. So I didn’t port that over. In fact, I added functionality to make it easy to go right back to a point you were at before noticing the smell of brain fart. The game is fiendishly difficult in my opinion, I don’t think it’s necessary to make it any more difficult. In fact, if they hadn’t made it so damn difficult, maybe it would be up there with Sokoban and other famous puzzle games from the 1980s.
By the way, I’ve only solved level 1. It was super hard. Update 2023/03/01: And level 2 and 3! It probably took longer to solve level 1 than implementing the basic game logic. No guarantees that levels 23 4 and beyond are solvable. If you solve anything beyond level 23 4, please send me your sequence strings. I’ll verify them and add a note here or maybe in the game that the level has been shown to be solvable. :)
Making games like this is pretty straightforward, but:
There is one part in my implementation of this game that I think is slightly interesting. Since I do not know the solutions to the puzzles (and there may even be puzzles with multiple solutions), I wrote a small recursive function (trace_wire_path) that traces the electric path and returns true if it leads to the bomb (it starts tracing at a battery terminal). It’s not optimized at all, and I didn’t bother cleaning up the code after getting it to work for the first time (my gut feeling says that it should be easy to replace a lot of the if-thens with lookup tables), but this kind of stuff doesn’t occur too often in regular day-to-day programming, so I thought it was kind of fun. (Though it all depends on what you do for a living, I guess?) Let me know if there’s some corner case where it didn’t work for you. ;)
// for simplicity we always trace from the battery
function trace_wire_path(x, y, dir_x, dir_y) {
// if tile at x, y is inside ELEMENTS_COMPATIBLE_WITH_POS_DIRX array
var tile_to_check = levels[current_level][y][x];
// is this tile compatible with the previous tile?
if ((dir_x == 1) &&
(ELEMENTS_COMPATIBLE_WITH_POS_DIRX.indexOf(tile_to_check) == -1))
return false;
else if ((dir_x == -1) &&
(ELEMENTS_COMPATIBLE_WITH_NEG_DIRX.indexOf(tile_to_check) == -1))
return false;
else if ((dir_y == 1) &&
(ELEMENTS_COMPATIBLE_WITH_POS_DIRY.indexOf(tile_to_check) == -1))
return false;
else if ((dir_y == -1) &&
(ELEMENTS_COMPATIBLE_WITH_NEG_DIRY.indexOf(tile_to_check) == -1))
return false;
// are we done? (we already know we must be on the right side)
if ((tile_to_check == TNT_BOTTOM_LEFT) ||
(tile_to_check == TNT_BOTTOM_RIGHT))
return true;
// what's our new direction?
if ((tile_to_check == HORIZONTAL_WIRE) ||
(tile_to_check == VERT_WIRE)) {
new_dir_x = dir_x;
new_dir_y = dir_y;
} else if ((tile_to_check == CORNER_WIRE_NW) ||
(tile_to_check == CORNER_WIRE_SW) ||
(tile_to_check == CORNER_WIRE_NE) ||
(tile_to_check == CORNER_WIRE_SE)) {
if (dir_x) { // dir_x is 1 or -1
new_dir_x = 0;
if ((tile_to_check == CORNER_WIRE_NW) ||
(tile_to_check == CORNER_WIRE_NE))
new_dir_y = -1; // up
else if ((tile_to_check == CORNER_WIRE_SW) ||
(tile_to_check == CORNER_WIRE_SE))
new_dir_y = 1; // down
} else { // dir_x is 0
new_dir_y = 0;
if ((tile_to_check == CORNER_WIRE_NW) ||
(tile_to_check == CORNER_WIRE_SW))
new_dir_x = -1;
else if ((tile_to_check == CORNER_WIRE_NE) ||
(tile_to_check == CORNER_WIRE_SE))
new_dir_x = 1;
}
}
// recurse
return trace_wire_path(x+new_dir_x, y+new_dir_y, new_dir_x, new_dir_y);
}
Performance
It shouldn’t be a big deal to leave this game open in a tab somewhere. Virtually no CPU and not a lot of memory should be in use when nothing is happening. about:performance snapshot with the game just sitting there, waiting for user input:
No quantifiable energy impact; memory is low too.
In case anyone wants pictures of levels 11-20, which I haven’t included in my clone because they looked a bit suspicious:
11121314151617181920
Yeah, I don’t quite get why the battery isn’t inside the playfield, and there’s no TNT either… If anyone wants to convert these levels into my format, patches are welcome. :)
Copyrights
Copyright status of my clone: I recreated the original graphics in Inkscape. I do not claim any copyright on the graphics. As they are recreated somewhat faithfully, the graphics probably are technically pirated and not copyrightable. The code may or may not be copyrightable. If it is, let’s say it’s GPLv3 for now. However, I disclaim all copyright after release + 15 years.
I will upload the changes necessary to run the JT51 as a drop-in replacement of a real YM2151 relatively soon. Things aren’t 100% ironed out yet.
Update 2023/03/06
The below update states that there are errors in jt51_phrom and jt51_exprom.v, but these errors were minor and have been fixed. However, the fixed jt51_phrom.v doesn’t appear to have a large effect on the final number of LUT4s used. It looks like the mistake I had originally made (a race condition-type of mistake) was responsible for the majority of the savings. Boo.
Here’s a short sound recording with the mistake left in:
And here’s a short sound recording with the mistake ironed out:
In addition, the changes to jt51_sh.v mentioned in the below update might suffer from some problems too. So far I have only managed to run with jt51_sh8 enabled, so I have no way to compare the unmodified jt51_sh implementation to my modified implementation, but I also tried adding jt51_sh10 for another shift register, and that made things sound rather weird. It’s currently not clear to me why that is the case.
Important update 2023/03/01
I finally managed to test the modified code. Do not use it, there are probably errors in it. Using the modified sine tables (jt51_phrom.v) causes everything to sound noisy. Using the modified exprom.v messes something up, but the effect is rather subtle.
Instead, you can save on LUTs by modifying jt51_sh.v as follows. This is the original code:
module jt51_sh #(parameter width=5, stages=32, rstval=1'b0 ) (
input rst,
input clk,
input cen,
input [width-1:0] din,
output [width-1:0] drop
);
reg [stages-1:0] bits[width-1:0];
genvar i;
generate
for (i=0; i < width; i=i+1) begin: bit_shifter
always @(posedge clk, posedge rst) begin
if(rst)
bits[i] <= {stages{rstval}};
else if(cen)
bits[i] <= {bits[i][stages-2:0], din[i]};
end
assign drop[i] = bits[i][stages-1];
end
endgenerate
endmodule
It looks like the logic yosys synthesizes from this code is inefficient. I haven’t looked too much into it, but writing this code out (and removing one of the channels, etc.) causes yosys to synthesize more efficient code. As you can see, this code uses parameters that affect the way it is generated. I just picked one set of parameters that appeared multiple times, width=14 and stages=8, and that was enough to get the logic to just fit. I.e., I appended the following code inside the same file:
And adjusted jt51_op.v to use jt51_sh8 instead of jt51_sh for prev1_buffer, prevprev1_buffer, and prev2_buffer.
Original post follows:
Quick summary
I took JT51 (https://github.com/jotego/jt51) and shrunk it down a little. I got it down to just barely fit. There are some lookup tables that are processed down by a couple hundred LUT4s, I made the lookup tables contain the already processed values instead. We’re now using slightly more RAM.
How we got here
I am currently debugging a YM2151-based device, the Yamaha SFG-01 sound module for MSX PCs. There is… wonky audio when two notes are played at once on the attached keyboard. I started off by emulating the YM3012 DAC on a Raspberry Pi Pico. More on that in a future post. More on the whole repair in a future post, in fact. My plan was to run the original YM2151 and the FPGA version side-by-side (with the exact same inputs) and to compare the audio outputs. However, after I already did most things detailed in this post, I realized that plan probably wasn’t going to work, as (if I read the datasheet correctly) the YM2151 generates interrupts which probably have to be acknowledged, and the data bus is bidirectional, and actually does get read out by the CPU occasionally. So the original chip and the FPGA would have to work in 100% perfect sync, and who knows how achievable that is.
I have two FPGA boards, and they’re both exactly the same, UPduino v3.0. I bought these back in 2020 or so, expecting I’d maybe come up with a project at some point. They were cheaper back then! I paid 43.20 USD + 6 USD shipping for 2! So per device, in JPY at that time: 21.6 * 103 = 2225 JPY. Currently, the price is $30 per device, and USD/JPY is 133.8. 30 * 133.8 = 4014 JPY, so almost double. Yikes.
Only have an ICE40UP3K? Allegedly, if you use the open-source toolchain, it’ll have exactly the same amount of LUT4s available as an ICE40UP5K. Apparently it’s just the official IDE enforcing an artificial limit?
So all I’d done up to this point was: I installed the open-source toolchain, changed the speed of the LED blinking example, re-flashed, and got some satisfaction that it all worked. Let’s start from that point. I think the official tutorials should get you there (except for the speed change maybe).
Also: important: I haven’t tested my revised Verilog yet. That’s something for part 2 (not done/written yet).
Then, git clone https://github.com/jotego/jt51. Copy UPduino-v3.0/RTL/common from the toolchain to jt51/ and UPduino-v3.0/RTL/blink_led/Makefile to jt51/hdl/. Perhaps cd to jt51/hdl and modify the Makefile as follows.
Note: Makefiles consist of rules laying out how to build a certain file. Rule blocks start like this: “filename: dependencies”. The dependencies are filenames. There is only one rule in our Makefile that directly depends on .v files:
rgb_blink.json: rgb_blink.v
Instead of rgb_blink.v, we’ll replace that by all the jt51_….v files we have in jt51/hdl:
And finally, let’s change all names from “rgb_blink” to “jt51” using search and replace: “rgb_blink” -> “jt51”. You should end up with a Makefile like this:
# Makefile to build UPduino v3.0 rgb_blink.v with icestorm toolchain
# Original Makefile is taken from:
# https://github.com/tomverbeure/upduino/tree/master/blink
# On Linux, copy the included upduinov3.rules to /etc/udev/rules.d/ so that we don't have
# to use sudo to flash the bit file.
# Thanks to thanhtranhd for making changes to thsi makefile.
rgb_blink.bin: rgb_blink.asc
icepack rgb_blink.asc rgb_blink.bin
rgb_blink.asc: rgb_blink.json ../common/upduino.pcf
nextpnr-ice40 --up5k --package sg48 --json rgb_blink.json --pcf ../common/upduino.pcf --asc rgb_blink.asc # run place and route
rgb_blink.json: rgb_blink.v
yosys -q -p "synth_ice40 -json rgb_blink.json" rgb_blink.v
.PHONY: flash
flash:
iceprog -d i:0x0403:0x6014 rgb_blink.bin
.PHONY: clean
clean:
$(RM) -f rgb_blink.json rgb_blink.asc rgb_blink.bin
Make sure you have tab characters, not space characters in the rule block indentation. (Trap for young players.) Make sure you also copied the common/ directory as instructed above. Then, execute “make”. If you get the following error:
$ make
nextpnr-ice40 --up5k --package sg48 --json jt51.json --pcf ../common/upduino.pcf --asc jt51.asc # run place and route
/bin/sh: 1: nextpnr-ice40: not found
make: *** [Makefile:12: jt51.asc] Error 127
That means you need nextpnr-ice40 in your PATH. Figure out the path, and then execute:
Okay, first things first. How old is our toolchain?
$ yosys -V
Yosys 0.8 (git sha1 5706e90)
Let’s see, the newest version of yosys, at the time of this writing, is… 0.26. Wait what? Ah, it looks like a smaller number, but is probably intended to be a larger number. It appears that my version is from 2018. Likely, I’d just installed it from Debian’s repositories. Let’s try building yosys from Git so we can upgrade from 0.8 to 0.26. It would like to build using clang by default, but you can build using gcc too. You also need tcl8.6-dev (or probably other versions work fine too).
$ git clone https://github.com/YosysHQ/yosys
$ cd yosys
$ make
/bin/sh: 1: clang: not found
[ 0%] Building kernel/version_4c334b905.cc
[ 0%] Building kernel/version_4c334b905.o
/bin/sh: 1: clang: not found
make: *** [Makefile:754: kernel/version_4c334b905.o] Error 12
$ make config-gcc
...
In file included from kernel/calc.cc:24:
./kernel/yosys.h:81:12: fatal error: tcl.h: No such file or directory
# include <tcl.h>
...
$ sudo apt-get install tcl8.6-dev
...
$ make config-gcc
...
$ # success
And if we try synthesizing again now, we do get a significant improvement. (Also synthesis time is faster I think.) But we are not quite there yet:
Shrinking the footprint by changing yosys options (using DSP cells)
110% isn’t too far from where we need to be, so let’s investigate if we can do anything to reduce our FPGA footprint. First of all, there are three files that include the word ‘rom’, which may have a significant effect on our footprint. But it looks like our toolchain is clever — it actually uses ICESTORM_RAM to implement the ROM. (Replacing the entire case/endcase block in the rather large jt51_phinc_rom.v file with a single statement reduced the LC count by 2-3%, and ICESTORM_RAM from 10% to 0%.)
Next, we forget about yosys for a second, and attempt to synthesize this using the official toolchain from Lattice, IceCube2. You’ll need an account and follow a link to generate a license file. You need to enter a MAC address to bind the license to a certain computer. (Or maybe a computer with a certain network adapter.)
IceCube2’s synthesis finishes in a few seconds, and only uses 11 logic cells. Hmm, so efficient! Or more likely, something’s weird. And yes, indeed it’s getting confused and thinks that jt51_noise_lfsr.v is the main file. Apparently, this file’s modules aren’t actually used anywhere. So we get rid of that file (and also get rid of it in our Makefile above) and re-synthesize. Synthesis finishes successfully, and apparently uses 1698 LUTs. Hmm, really? (No, but let me go off a quick tangent first.)
Okay, let’s assume for a second that yosys is much, much worse than IceCube2. It’s time to google for something like ‘yosys vs icecube2’. A person on the EEVblog forums says, “The IceCube2 generates smaller and faster design (most visible with larger designs) than the IceStorm does, it can infer ie. multipliers with built-in DSP modules (UP5k) etc. The IceStorm is less effective, and infers ie. multipliers in fabric (you have to instantiate the modules/primitives manually).” Hmm, interesting. Well, it turns out you can enable the DSP modules in yosys using the -dsp option, so we modify the Makefile as follows:
That reduces our LUT count by ~2% percent. Every percent counts, but we’re not quite there yet. Looking at https://github.com/YosysHQ/yosys/blob/master/techlibs/ice40/synth_ice40.cc, we see a few more options we could try, e.g., -spram, -noabc, -abc2, -abc9 (experimental), -flowmap (experimental).
-noabc brings us back up to 120%. -flowmap also increases the number of logic cells to a similar number. -abc2 eliminates 19 logic cells vs. just -abc, but that’s not a lot, and our percentage doesn’t change. -abc9 doesn’t yield much of an improvement either. Hmm, looks like we’ve exhausted some of the lower hanging fruit. Anyway, let’s take another closer look at the official toolchain’s output. When your eyes get a little more used to its output you actually notice that it says:
Hey. 1698 LUTs, but 3825 DFFs, and the P&R Flow tool confirms this:
Number of LUTs : 1698
Number of DFFs : 3825
Number of Carrys : 366
These DFFs also use up LUTs, so the total number of LUTs used is 5523, which is actually extremely close to yosys, and also too much. (Note that I already edited the Verilog a little bit at this point, so the number on an unmodified repository would be a little higher.)
Let’s remove the -q option from yosynth’s synth_ice40 command in the Makefile, and take a look at the output close to the summary that we looked at before. Scrolling way past a lot of verbose output, we get a summary like the following, and can see that yosys is indeed very close.
Info: Packing constants..
Info: Packing IOs..
Info: Packing LUT-FFs..
Info: 1462 LCs used as LUT4 only
Info: 515 LCs used as LUT4 and DFF
Info: Packing non-LUT FFs..
Info: 3367 LCs used as DFF only
Info: Packing carries..
Info: 184 LCs used as CARRY only
Info: Packing indirect carry+LUT pairs...
Info: 63 LUTs merged into carry LCs
Shrinking the footprint by removing features
Next, we could try and cut down on features in order to reduce the required number of logic cells. First of all, I nuked the entire right channel (“right” and “xright”) by commenting out a couple lines in jt51.v and jt51_acc.v. That shaved off about 2%. I kept “xleft” but also got rid of the converted “left”. That means we no longer need to compile jt51_exp2lin.v, which seems to save 9 LUTs.
Shrinking the footprint by trading LUTs for RAM
A cursory (liar liar pants on fire) glance over the code revealed an opportunity to potentially save a more significant number of LUTs. In jt51_op.v, we refer to a sine table (which is in jt_phrom.v) and concatenate certain bits from this table. In the following snippet, the sine table is already in the sta_XI register:
If you are new to Verilog, numbers often look like this: <total bit width>'<letter indicating number format, e.g., b for binary><number>. The array indices refer to bit numbers. E.g., sta_XI[38] is bit 38 in sta_XI, counting from 0. “case” is like a switch statement in C. So up here, we do something like:
switch(bits 7 and 6 of phaselo_XI) {
case 0: ...;
case 1: ...;
case 2: ...;
case 3: ...;
default: ...;
}
(The “default” clause is extraneous, but doesn’t cause harm.)
The sine table is fairly large, at 32 entries of 46 bits. In the above code snippet, we pick (to me, super random) bits from the table and also insert constant 0s and 1s here and there. E.g., the first line reads in plain words: ten 0s, followed by sinetable[i][29], followed by sinetable[i][25], followed by two 0s, etc. The sine table isn’t used anywhere else.
Our opportunity is: instead of generating a circuit to combine bits from the sinetable together, we can just rewrite the sine lookup table to already contain what we call stb above. It doesn’t matter if our table ends up a little larger (it could be up to four times larger), because as mentioned above, RAM is used to store these tables. But our table isn’t that much larger, really. Before we had 32×46=1472 bits, now we have a three-dimensional array of dimensions 4x32x19=2432 bits, not even twice as large.
This optimization takes us to 5363/5280 (101%), which means we’re almost done! (If we use four two-dimensional arrays and a case block, the savings are much less pronounced, 104%.) Of course, there is no free lunch: we now use more RAM: ICESTORM_RAM 5/30 (16%). Before it was 3/30 (10%). But we still have a lot of RAM left.
Rewriting the table by hand presumably gets old quickly, so I wrote a short Perl script to do it. (Luckily, it can sometimes be very easy to transform Verilog source code to Perl using find and replace with regular expressions.)
We could actually go even further; looking a little further ahead, stb is only used to fill in stf and stg:
stf = { stb[18:15], stb[12:11], stb[8:7], stb[4:3], stb[0] };
// Gated value to sum; bit 14 is indeed used twice
if( phaselo_XI[0] )
stg = { 2'b0, stb[14], stb[14:13], stb[10:9], stb[6:5], stb[2:1] };
else
stg = 11'd0;
Which means we could change our lookup table once more and directly read out stf and stg. However, scrolling down a little further in the same file, we see the same kind of pattern in the code doing the post-processing for jt51_exprom, so let’s tackle that one instead. Changing jt51_exprom to directly return etf and etg gets us: 5196/ 5280 (98%). Yay!
Now, if we wanted to make a drop-in replacement for an actual YM2151 chip, we’d have to serialize sound output. JT51 outputs xleft/xright/left/right using 16 IO pins each. (We don’t even have enough IO pins on our FPGA.) But the actual YM2151 uses four pins: clock, SH1, SH2, and SO. SO is the serialized representation of left/right, synced with clock. SH1 is high if SO is currently outputting left, SH2 is high is if SO is currently outputting right. In order to implement that, we need a few more LUTs.
Anyway, that was a rather long-winded explanation. Below is the code. I also have it on https://github.com/qiqitori/jt51. Note that the code hasn’t been tested yet at the time of this writing.
Revised jt51_phrom.v (still GPLv3 or later but the copyright header is a little too big for this space):
The exprom code used [44:36], so we need to reverse that using Perl’s array-reversing function, reverse(). The notation used here (reverse(@{$exp_XII->[$i]}[36..44])) is probably one of the reasons why Perl has fallen out of favor. :)
Last year, I bought a faulty Hitachi MB-H2 (MSX) in order to gain electronics and repair experience. Using my oscilloscope and two simple 74-series (NOT and AND) logic ICs, I managed to figure out that one of the RAM chips was faulty. I replaced the RAM chip, but it still wouldn’t work. I did one more slightly less reliable oscilloscope-based test and replaced one more chip, and it still wouldn’t work. How many faults can this machine have? Well it turns out that probably only the first RAM chip was broken in the first place, and I just didn’t solder properly. I thought I had checked my connections, but I guess one was border-line. (I have more soldering experience now.)
So, suspecting that I had some kind of severe fault, and not having come up with the logic analyzer “idea” yet, and noticing that the CPU was socketed, I decided to take out the CPU and just generate the signals that the CPU would generate myself, using two Raspberry Pi Picos. (Because I needed a lot of pins, not necessarily performance.) One Pico is responsible for the address and control pins, the other for the data pins. As I noticed some time in, Pico 1 should have had the data and control pins, Pico 2 the address pins. Why? Timing matters with the data pins, but for address pins you can be super slow and it’ll be fine. It still worked out in the end.
Pico 1 controls Pico 2 via UART. A host computer (yes, you, Mr. ThinkPad) controls Pico 1 via serial. Then some idiot (yes, me) types in commands into a serial terminal, and Pico 1 does the idiot’s bidding. The following commands are recognized:
i, for IOREQ input
o, for IOREQ output
v, for VRAM manipulation, which I actually couldn’t get to work the way I expected, but it still does something
r, for RAM reads
w, for RAM writes (and a simple readback to make sure the RAM stores stuff)
W, for RAM writes with RAM refresh (and a readback after every refresh). You can specify the amount of writes between refreshes and stuff.
s, sync UART (flushes out all characters stuck in the UART read buffer)
0: ask Pico 2 to set data bus to 0
u: ask Pico 2 to unset data bus (i.e., to set bus direction from: GPIO_OUT to: GPIO_IN)
So, how does it work? How does the Z80 work? Let’s have a look at the Z80 pinout:
The A pins are the address pins. The D pins are the data pins. So if you want to write 0 to address 0, all those pins will be 0. In addition, RD will be high, and WR will be low, because we are writing. (Yes, 0 means “active” and 1 means “inactive”.) In addition, we are writing to memory, not to IO space. So IORQ is 1 and MREQ is 0. (Also M1 goes from 1 to 0 too, but I don’t remember the details there.) If we instead want to talk to hardware, we need to know the hardware address and set IORQ to 0 instead of MREQ. On the Z80, only A0 to A7 matter for IO addresses. Well, that’s the gist of it.
With a crude thing like this, we can:
Dump the main ROM and check that the contents are correct
Check if memory works
Check if the sound chip works
Check if the video chip works
Check if the IO controller works
We can turn the tape motor on and off
We can map memory
Etc.?
(Provided the connection from CPU to the above peripherals is working)
I was able to check all of the above. Note that in the highly unlikely event that you decide to run any of this on your MSX machine, note that memory mapping is a bit different from machine to machine. (Which is important, otherwise RAM expansions wouldn’t work, right?)
So here are some examples of commands I’d paste into my terminal:
# Turn off tape motor (which is on by default IIRC?), map memory, maybe some other stuff (I got these by running the MB-H2 in openmsx and checking the earliest 'in's and 'out's in openmsx-debugger, also see below screenshot)
# Execute this before executing anything else!
o00ab82o00aa50o00a800o00a850o00a8a0o00a8f0
# Read first 16 bytes of ROM
r0000rr0001rr0002rr0003rr0004rr0005rr0006rr0007rr0008rr0009rr000arr000brr000crr000drr000err000frr0010r
# Read bits 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, and 15 (counting bits from 0) (if you get the right result here you'll know that your connections are good)
r0001rr0002rr0004rr0008rr0010rr0020rr0040rr0080rr0100rr0200rr0400rr0800rr1000rr2000rr4000rr8000r
# Expected result of above command for MB-H2:
sed -n -e '2p' -e '3p' -e '5p' -e '9p' -e '17p' -e '33p' -e '65p' -e '129p' -e '257p' -e '513p' -e '1025p' -e '2049p' -e '4097p' -e '8193p' -e '16385p' 32k_v2.hex
c3
d7
bf
c3
c3
c3
13
06
ee
2a
e5
32
a4
00
e5
head -n 1 16k_v2.hex
41
# Set background colors:
o00990fo009987 # white background
o00990eo009987 # gray
o00990do009987 # magenta
o00990co009987 # dark green
o00990bo009987 # light yellow
o00990ao009987 # dark yellow
o009909o009987 # light red
o009908o009987 # medium red
o009907o009987 # cyan
o009906o009987 # dark red
o009905o009987 # light blue
o009904o009987 # dark blue
o009903o009987 # light green
o009902o009987 # medium green
o009901o009987 # black
# click sound test:
o00ab0fo00ab0eo00ab0fo00ab0eo00ab0fo00ab0e
# VRAM notes (worked partially, but I think you may need to change the video mode to something else in order to get full VRAM access like this? Never really got it to work as expected. IIRC, the values would stick for a bit, and then go back to 0f or something)
# To read from 0000 to ... (address is auto-incremented, so you only have to set it once):
o009900 # set lower byte of address
o009900 # set upper byte of address (bit 7 and 6 are low to indicate that we want to read)
i0098 # read from 0000
i0098 # read from 0001
i0098 # read from 0002
i0098 # read from 0003
...
# bunched into a single line:
o009900o009900i0098i0098i0098i0098
# To write ff to 0000-... (address is auto-incremented, so you only have to set it once):
o009900 # set lower byte of address
o009940 # set upper byte of address (bit 7 is low and bit 6 is high to indicate that we want to write)
o0098ff # set data register to ff to write to 0000
o0098ff # set data register to ff to write to 0001
o0098ff # set data register to ff to write to 0002
o0098ff # set data register to ff to write to 0003
...
# bunched into a single line:
o009900o009940o0098ffo0098ffo0098ff
What’s a good story without pictures?
openmsx-debugger early in the boot process (looking for RAM)Serial terminal for Pico 1 (left) and Pico 2 (right) (Pico 2’s output is just debug output, and doesn’t accept commands from this serial connection)I put a 40-pin socket in the existing 40-pin socket, and directly clipped in breadboard jumper wire. It worked, but wasn’t fun. I still stuck with this setup. Note: maybe half the wires pictured here are actually part of the computer. Yes, this computer has many, many wires inside. BTW, just one Pico here because I thought it’d be worth something with just a couple bits on the data bus. But yeah, that wasn’t very fun.Now running with two Raspberry Pi Picos. At first I tried using an automatic level shifter, but that didn’t work. Possibly because the data bus’ idle voltage (when everything is at high impedance) is at around 2V. I think I even saw a datasheet somewhere recommending doing that, maybe the 4164 RAM?And here’s a tiny minicom script cycling through the background colors (see below)
Danger: do not submit code to code beauty contests.
The code consists of two separate projects, in CMake terms. One is for Pico 1, the other is for Pico 2. First of all the CMakeLists.txt files are as follows:
Pico 1 (create a directory called e.g. inspect_system_interactively and in there, create a file called CMakeLists.txt with the following contents):
cmake_minimum_required(VERSION 3.12)
# Pull in SDK (must be before project)
include(pico_sdk_import.cmake)
project(pico_examples C CXX ASM)
set(CMAKE_C_STANDARD 11)
set(CMAKE_CXX_STANDARD 17)
if (PICO_SDK_VERSION_STRING VERSION_LESS "1.3.0")
message(FATAL_ERROR "Raspberry Pi Pico SDK version 1.3.0 (or later) required. Your version is ${PICO_SDK_VERSION_STRING}")
endif()
set(PICO_EXAMPLES_PATH ${PROJECT_SOURCE_DIR})
# Initialize the SDK
pico_sdk_init()
include(example_auto_set_url.cmake)
add_compile_options(-Wall -Wextra
-Wno-format # int != int32_t as far as the compiler is concerned because gcc has int32_t as long int
-Wno-unused-function # we have some for the docs that aren't called
-Wno-maybe-uninitialized
-O3
)
add_executable(inspect_system_interactively
inspect_system_interactively.c
)
# pull in common dependencies
target_link_libraries(inspect_system_interactively pico_stdlib)
# enable usb output, disable uart output
pico_enable_stdio_usb(inspect_system_interactively 1)
pico_enable_stdio_uart(inspect_system_interactively 0)
# create map/bin/hex file etc.
pico_add_extra_outputs(inspect_system_interactively)
# add url via pico_set_program_url
example_auto_set_url(inspect_system_interactively)
Pico 2 (my directory name is inspect_system_interactively_databus):
cmake_minimum_required(VERSION 3.12)
# Pull in SDK (must be before project)
include(pico_sdk_import.cmake)
project(pico_examples C CXX ASM)
set(CMAKE_C_STANDARD 11)
set(CMAKE_CXX_STANDARD 17)
if (PICO_SDK_VERSION_STRING VERSION_LESS "1.3.0")
message(FATAL_ERROR "Raspberry Pi Pico SDK version 1.3.0 (or later) required. Your version is ${PICO_SDK_VERSION_STRING}")
endif()
set(PICO_EXAMPLES_PATH ${PROJECT_SOURCE_DIR})
# Initialize the SDK
pico_sdk_init()
include(example_auto_set_url.cmake)
add_compile_options(-Wall -Wextra
-Wno-format # int != int32_t as far as the compiler is concerned because gcc has int32_t as long int
-Wno-unused-function # we have some for the docs that aren't called
-Wno-maybe-uninitialized
-O3
)
add_executable(inspect_system_interactively_databus
inspect_system_interactively_databus.c
)
# pull in common dependencies
target_link_libraries(inspect_system_interactively_databus pico_stdlib)
# enable usb output, disable uart output
pico_enable_stdio_usb(inspect_system_interactively_databus 1)
pico_enable_stdio_uart(inspect_system_interactively_databus 0)
# create map/bin/hex file etc.
pico_add_extra_outputs(inspect_system_interactively_databus)
# add url via pico_set_program_url
example_auto_set_url(inspect_system_interactively_databus)
Next, you need to place the C files into the corresponding directories. Then you just need to execute two commands, “cmake .” followed by “make”, in both directories.