Many websites lack useful features, many websites go to great lengths to prevent you from downloading images, etc.
When things get too annoying I sometimes open the developer tools and write a short piece of JavaScript to help me out. Okay, but isn’t it annoying to open developer tools every time? Yes! So right-click your bookmarks toolbar, press the button to add a bookmark, give it an appropriate title, and in the URL, put “javascript:” followed by the JavaScript code. (Most of the following examples already have javascript: prepended to the one-liner.)
Note that you have to encapsulate most of these snippets in an anonymous function, i.e. (function() { … })(). Otherwise your browser might open a page containing whatever value your code snippet returns.
(It is my belief that all of the following code snippets aren’t copyrightable with a clear conscience, as they may constitute the most obvious way to do something. The code snippets can therefore be regarded as public domain, or alternatively, at your option, as published under the WTFPL.)
Note that these snippets are only tested on Firefox. (They should work in Chrome too, though.)
Hacker News: scroll to next top-level comment
Q: How likely is this to stop working if the site gets re-designed?
A: Would probably stop working.
This is a one-liner to jump to the first/second/third/… top-level comment. (Because often the first few threads get very monotonous after a while?) If you don’t see anything happening, maybe there is no other top-level comment on the current page.
document.querySelectorAll("img[src='s.gif'][width='0']")[0].scrollIntoView(true)
document.querySelectorAll("img[src='s.gif'][width='0']")[1].scrollIntoView(true)
document.querySelectorAll("img[src='s.gif'][width='0']")[2].scrollIntoView(true)
javascript:document.querySelectorAll("img[src='s.gif'][width='0']")[1].scrollIntoView(true) # Bookmarklet version. Basically just javascript: added at the beginning.
The “true” parameter in scrollIntoView(true) means that the comment will appear at the top (if possible). Giving false will cause the comment to be scrolled to to appear at the bottom of your screen. Not that the scrolling isn’t perfect; the comment will be half-visible.
It would be useful to be able to remember where we last jumped to, and then jump to that + 1. We can add a global variable for that, and to be reasonably sure it doesn’t clash with an existing variable we’ll give it a name like ‘pkqcbcnll’. If the variable isn’t defined yet, we’ll get an error, so to avoid errors, we’ll use typeof to determine if we need to define the variable or not.
javascript:if (typeof pkqcbcnll == 'undefined') { pkqcbcnll = 0 }; document.querySelectorAll("img[src='s.gif'][width='0']")[pkqcbcnll++].scrollIntoView(true);
Wikipedia (and any other site): remove images on page
Q: How likely is this to stop working if the site gets re-designed?
A: Unlikely to stop working, ever.
Sometimes Wikipedia images aren’t so nice to look at, here’s a quick one-liner to get rid of them:
document.querySelectorAll("img").forEach(function(i) { i.remove() });
Instagram (and e.g. Amazon and other sites): open main image in new tab
Q: How likely is this to stop working if the site gets re-designed?
A: Not too likely to stop working.
When you search for images or look at an author’s images in the grid layout, right-click one of the images and press “open in new tab”, then use the following script to open just the image in a new tab. I.e., it works on pages like this: https://www.instagram.com/p/CSSx_E3pmId/ (random cat picture, no endorsement intended.)
Or on Amazon product pages, you’ll often get a large image overlaid on the page when you hover your cursor over a thumbnail. When you execute this one-liner in that state, you’ll get that image in a new tab for easy saving/copying/sharing. E.g., on this page: https://www.amazon.co.jp/dp/B084H7ZYTT you will get this image in a new tab if you hover over that thumbnail. (Random product on Amazon, no endorsement intended.)
{kind=link}
This script works by going through all image tags on the page and finding the source URL of the largest image. As of this writing, I believe this is the highest resolution you can get without guessing keys or reverse-engineering.
javascript:var imgs=document.getElementsByTagName("img");var height;var max_height=0;var i_for_max_height=0;for(var i=0;i<imgs.length;i++){height=parseInt(getComputedStyle(imgs[i]).getPropertyValue("height"));
if(height>max_height){max_height=height;i_for_max_height=i;}}open(imgs[i_for_max_height].getAttribute("src"));
xkcd: Add title text underneath image (useful for mouse-less browsing)
Q: How likely is this to stop working if the site gets re-designed?
A: May or may not survive site designs.
Useful for mouseless comic reading. There’s just one <img> with title text, so we’ll take the super-simple approach. Alternatively we could for example use #comic > img or we could select the largest image on the page as above.
javascript:document.querySelectorAll("img[title]").forEach(function(img) { document.getElementById("comic").innerHTML += "<br />
" + img.getAttribute("title"); })
Instagram: Remove login screen that appears after a while in the search results
To do this, we have to get rid of something layered on top of the page, and then remove the “overflow: hidden;” style attribute on the body tag.
A lot of pages put “overflow: hidden” on the body tags when displaying nag screens, so maybe it’s useful to have this as a separate bookmarklet. Anyway, in the following example we do both at once.
javascript:document.querySelector("div[role=presentation]").remove() ; document.body.removeAttribute("style");
Sites that block copy/paste on input elements
This snippet will present a modal prompt without any restrictions, and put that into the text input element. This example doesn’t work in iframes, and doesn’t check that we’re actually on an input element:
javascript:(function(){ document.activeElement.value = prompt("Please enter value")})()
The following snippet also handles iframes (e.g. on https://www.w3schools.com/tags/tryit.asp?filename=tryhtml_input_test) and should even handle nested iframes (untested). The problem is that the <iframe> element becomes the activeElement when an input element is in an <iframe>. So we’ll loop until we find an activeElement that doesn’t have a contentDocument object. And then blindly assume that we’re on an input element:
javascript:(function(){var el = document.activeElement; while (el.contentDocument) { el = el.contentDocument; } el.activeElement.value = prompt("Please enter value")})()
Removing <iframe>s to get rid of a lot of ads
Many ads on the internet use <iframe> tags. Getting rid of all of these at once may clean up pages quite a bit — but some pages actually use <iframe>s for legitimate purposes.
javascript:(function(){document.querySelectorAll("iframe").forEach(function(i) { i.remove() });})();
Amazon Music: Get list of songs in your library
I.e., songs for which you have clicked the “+” icon. Maybe you want to get a list of your songs so you can move to a different service, or maybe you just want the list. The code presented here isn’t too likely to survive a redesign, but could probably be adjusted if necessary. Some JavaScript knowledge might come in handy if you want to get this script to work.
Amazon Music makes this process rather difficult because the UI unloads and reloads elements dynamically when it thinks you have too many on the page at once.
We are talking about this page (using the default, alphabetically ordered setting), BTW:
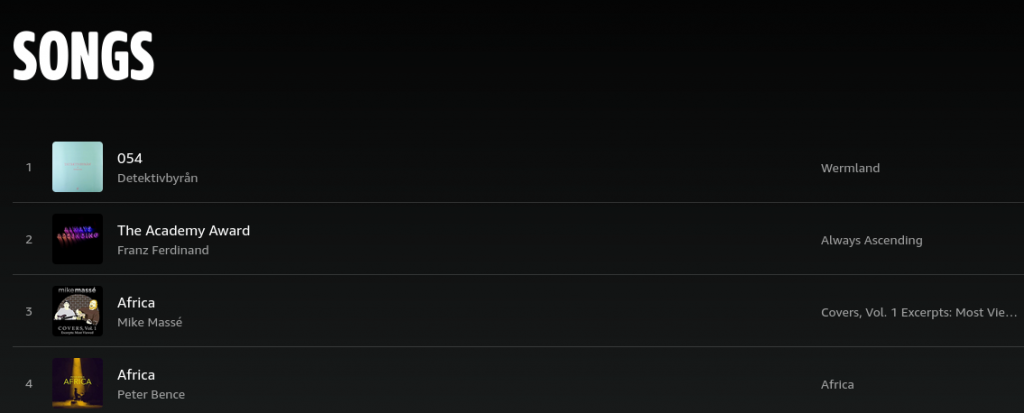
Ideally, you would just press Ctrl+A and paste the result into an editor, or select all table cells using, e.g., Ctrl+click.
However, you’ll only get around 15 items in that case. (The previous design let you copy everything at once and was superior in other respects too, IMO.)
Anyway, we’ll use the MutationObserver to get the list. Using the MutationObserver, we’ll get notified when elements are added to the page. Then we just need to scroll all the way down and output the collected list. We may get duplicates, depending on how the page is implemented, but we’ll ignore those for now — we may have duplicates anyway if we have the same song added more than once. So I recommend you get rid of the duplicates yourself, by using e.g. sort/uniq or by loading the list into Excel or LibreOffice Calc or Google Sheets, or whatever you want.
On Amazon Music’s page, the <music-image-rows> elements that are dynamically added to the page contain four <div> elements classed col1, col2, col3, and col4. (This could of course change any time.) These <div>s contain the song name, artist name, album name, and song length, respectively, which is all we want (well, all I want). We’ll just use querySelectorAll on the newly added element to select .col1, .col2, .col3, and .col4 and output the textContent to the console. Occasionally, a parent element pops up that contains all the previous .col* <div> elements. We’ll ignore that by only evaluating selections that have exactly four elements.
- Scroll to top of page
- Execute code (e.g., by opening console and pasting in the code)
- Slowly scroll to the end of the page
- Execute observer.disconnect() in the console (otherwise text will keep popping up if you scroll)
- Select and copy all text in the console (or use right-click → Export Visible Messages To), paste in an editor or (e.g.) Excel. There are some Find&Replace regular expressions below that you could use to post-process the output.
- Note that the first few entries in the list (I think sometimes it’s just the first one, sometimes it’s the first four) are never going to be newly added to the document, so you will have to copy them into your text file yourself.
The code’s output is rather spreadsheet-friendly, tab-deliminated and one line per entry. You can just paste that into your favorite spreadsheet software.
The code cannot really be called a one-liner at this point, but feel free to re-format it and package it as a bookmarklet, if you want.
observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
if (mutation.type === "childList") {
if (mutation.target && mutation.addedNodes.length) {
var string = "";
selector = mutation.target.querySelectorAll(".col1, .col2, .col3, .col4");
if (selector.length == 4) {
selector.forEach(function(e) { if (e.textContent) string += e.textContent + "\t" });
string += "----------\n"
console.log(string);
}
}
}
});
});
observer.observe(document, { childList: true, subtree: true });
Post-processing regular expressions (the “debugger eval code” one may be Firefox-specific):
Find: [0-9 ]*debugger eval code.*\n
Replace: (leave empty)
Find: \n----------\n
Replace: \n
(Do this until there are no more instances of the "Find" expression)
Find: \t----------
Replace: (leave empty)
There are a lot of duplicates. You can get rid of them either by writing your list to a file and then executing, e.g.: sort -n amazon_music.txt | uniq > amazon_music_uniq.txt
Or you can get Excel to do the work for you.
Make sure that you have the correct number of lines. (The Amazon Music UI enumerates all entries in the list. You would want the same number of lines in your text file.)