All emulators included in the Common Source Code Project that I’ve tested work in Wine (so far: tk85.exe, pc8001.exe, smc777.exe)
ROMs are not included, but you can get many ROMs from various ROM sites
PC-8001
Search for e.g., ‘pc-8001 mame rom’. At the time of this writing the first result is a page from wowroms.com with the required files
In the binary/ directory, there is a file called pc8801.txt with a list of file names of ROM files that the software will look for. The wowroms.com zip file contains the following files (random-looking number in front of the file name is the MD5 sum): cbf25d28f7f23ea3313c82587f873cd1 ap2k.ic3c cd428f9ee8ff9f84c60beb7a8a0ef628 font.rom 2e47e5a78ad3c84ee4e782a1e2d887f9 it.em.ou.bin 37f6793f7f3e3af0b506a33283a89d92 lx800.ic3c 56e4e812c7a3240af96a474240610378 lx810l.ic3c f374db2869f7f44356ede51e94b4c5b6 n80v101.rom f1f6109541a89b626d4faf3f92ce5d75 n80v102.rom 36a73378118eb9a610d50a8b5098c404 n80v110.rom 324fb3d389cc0af5cc7df4a6f5c935d0 p72.2c 26f9ac2a43dc28df74fea101c5ee1979 pl80.pt6 ead508099bf31291543f22291703bba5 tiny.bin f9e396bd8385cc70a95b70510b80f7d0 w8_pe9.9b
We want “N80.ROM for N-BASIC mode“, this is n80v101.rom in the zip file
cp n80v101.rom binary/binay_win10/N80.ROM
You can now boot (by doing wine pc8001.exe), but the characters are all white blocks.
font.rom contains bitmaps for our characters, but just renaming font.rom to KANJI1.ROM doesn’t help. Instead, do cat font.rom font.rom font.rom > binary/binay_win10/KANJI1.ROM
You should now be able to boot
PC-8801
Again, look for the ROM (search for ‘pc-8801 rom’). For the fonts, follow the steps above. (The font.rom is the same as above. If you already did the “cat font.rom font.rom font.rom > KANJI1.ROM command” you don’t have to do it again. If you haven’t, see above notes for the PC-8001.
However, you need one more file, SUBCPU.60. I couldn’t find the original ROM, and was satisfied using the compatible implementation available at this link: http://000.la.coocan.jp/p6/basic.html But I’m sure the original is floating around somewhere. (It seemed to me like it wouldn’t matter too much what code the 8049 microcontroller is running.)
SMC-777
binary/smc777.txt indicates that the following files are needed:
SMCROM.DAT Shadow ROM KANJIROM.DAT Kanji ROM
However, only SMCROM.DAT is necessary. You should be able to find it by searching for ‘smc-777 rom’. The MD5 sum of the file is f6a34be914cd1b22e196c15e69cdd3ac. In my case it was called “smcrom.dat”, but you have to name it SMCROM.DAT and put it into the binay_win10/ directory. (Unless your OS can’t tell lower case from upper case, that is.) If you get a blinking cursor, you’re good. You can now insert floppy disks and the system will automatically boot from them.
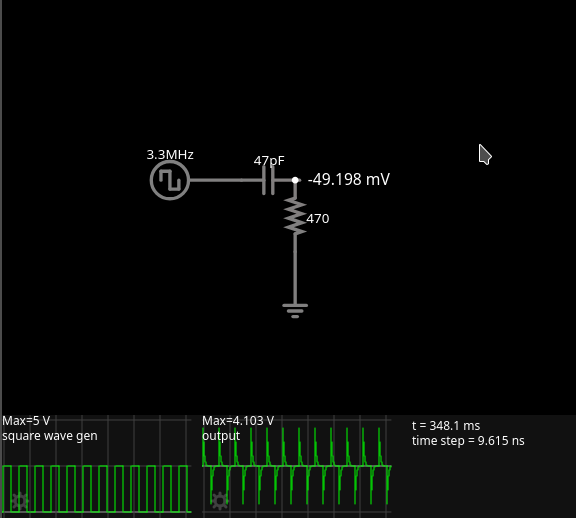
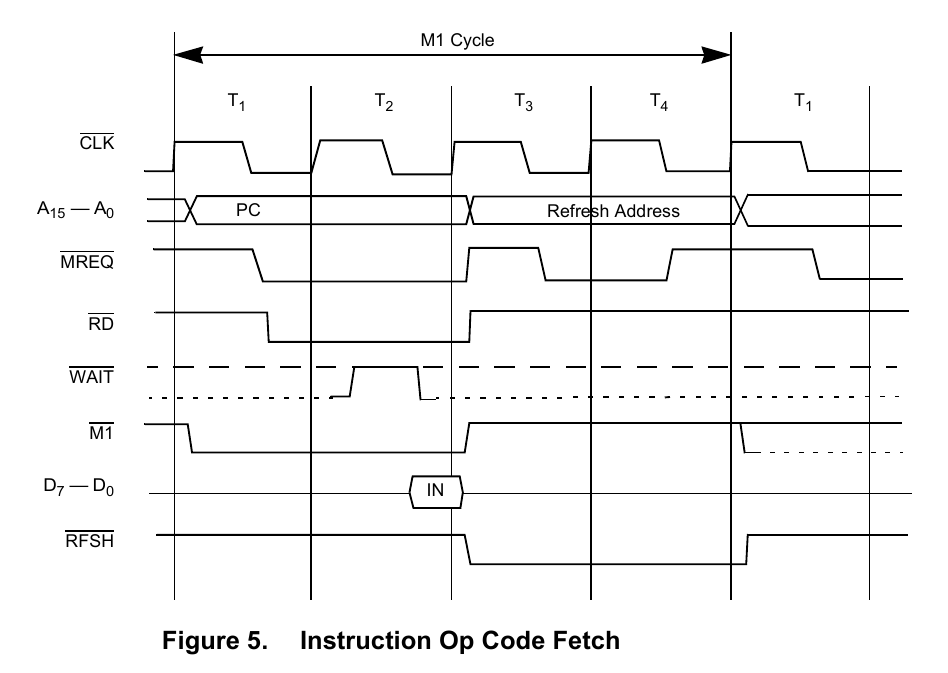
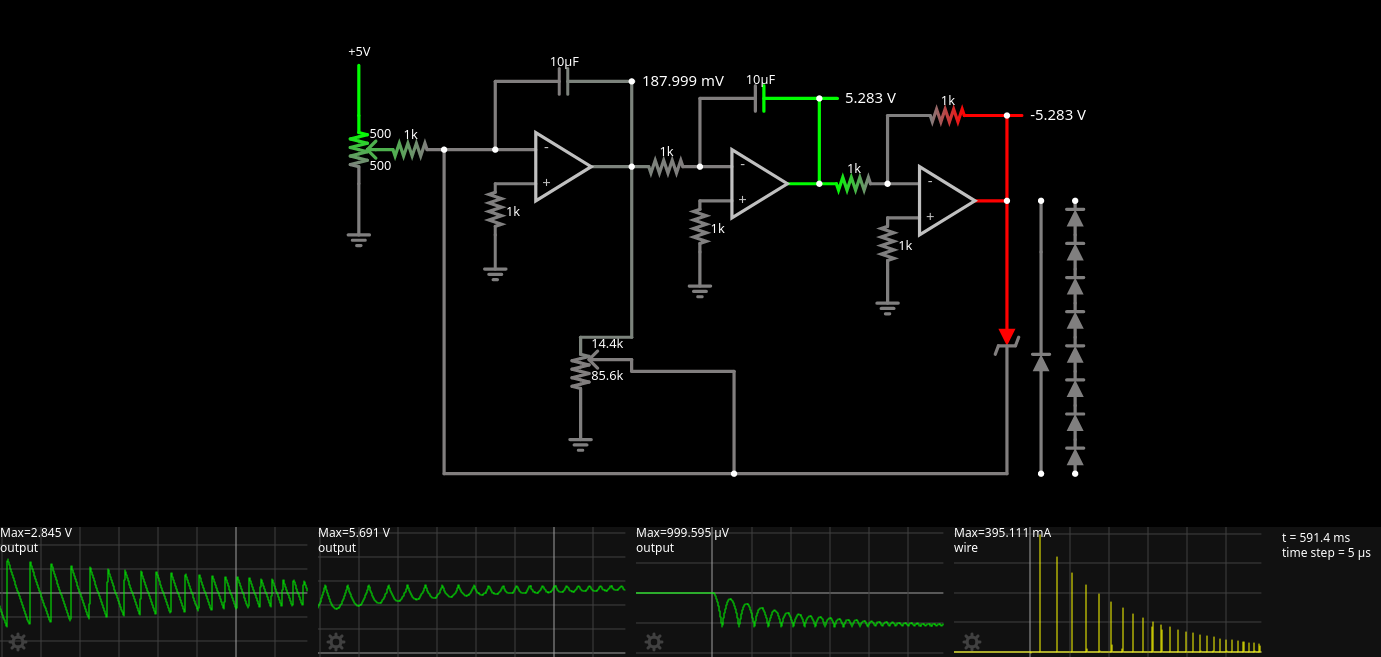
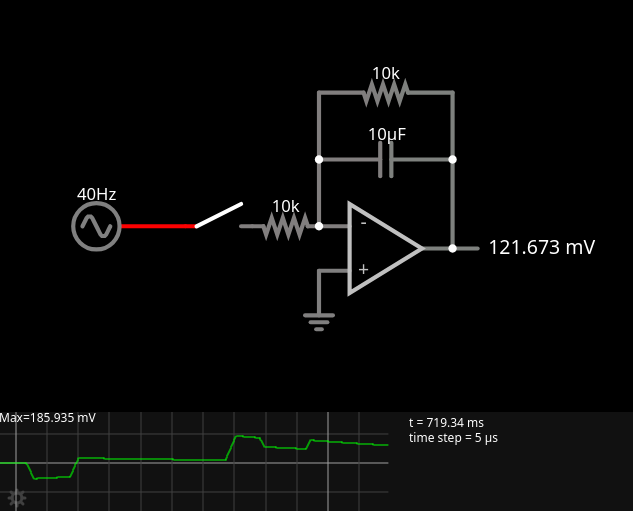
C11 is unusual in a digital circuit. Capacitors don’t pass DC. But digital circuits are DC, in a way. C11, together with R25, takes the clock signal (3.25 MHz) and mangles it.
In this simulation, we turn a nice 0V-5V square wave into a spiky thing with -4.103V lows and 4.103V highs. And we send this curious signal into two 74LS logic chips, IC11 (74LS00) and IC16 (74LS10). When we look at this signal on an oscilloscope, we see a very low signal (not anywhere near 4.103V), more like -1.4V to 1.4V. Reality is probably somewhere in between. I had Texas Instruments SN74LS00N (from 2019 I think) and SN74LS10N (older markings, not sure what year) chips, and the 74LS10 one was able to see the peaks and interpret them as a logic HIGH. The 74LS00, on the other hand, never interpreted the peaks as a logic HIGH. This produced a picture where inverted characters only had the first column inverted.
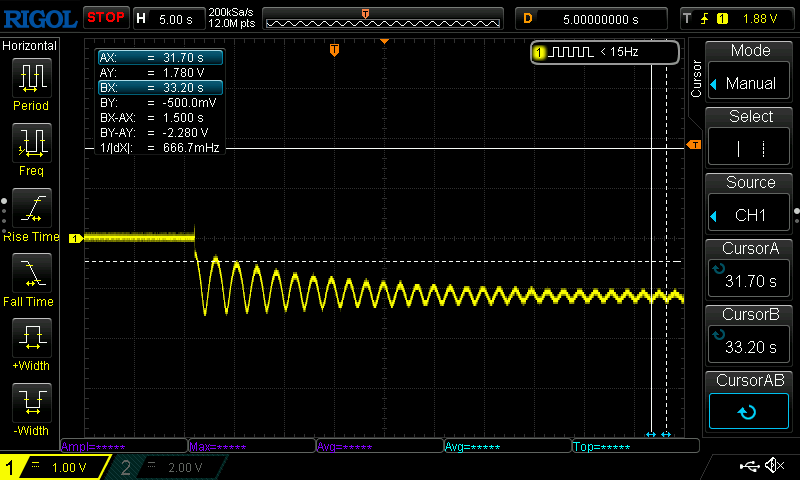
As you can see the “K” cursor has a thin vertical line in front of it. BTW, this code generates a screenful of inverted spaces.Lots of inverted spaces. Except they each consist of only a single vertical column.
I fixed this problem by buying another 74LS00. I bought one from Hitachi (now Renesas), called HD74LS00P.
Looking around the internet, some people change the capacitor, some change the resistor, some change both, some use different resistors/capacitors pairs on IC11 and IC16. I tried various things but unfortunately this didn’t work for my 74LS00. I believe the simplest solution would be to just get different 74LS00s and 74LS10s from several vendors and trying them out. And if that takes you nowhere, you could maybe try and use a couple transistors to rectify and amplify the signal. (It’s a rather fast signal so that may make it harder than just using a simple common-emitter configuration where the transistor is driven into saturation millions of times per second.)
So what is this RC filter good for anyway?
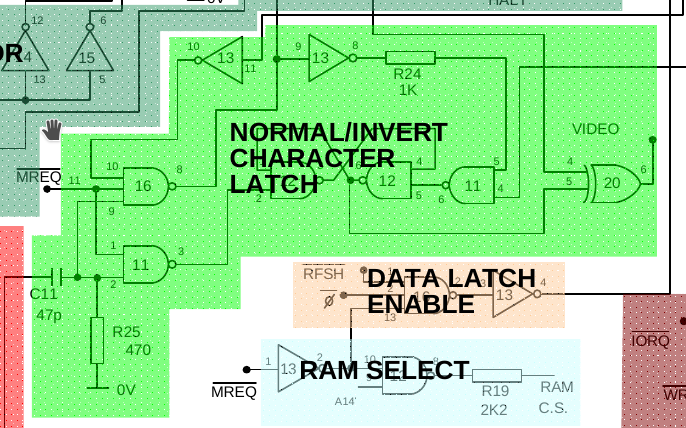
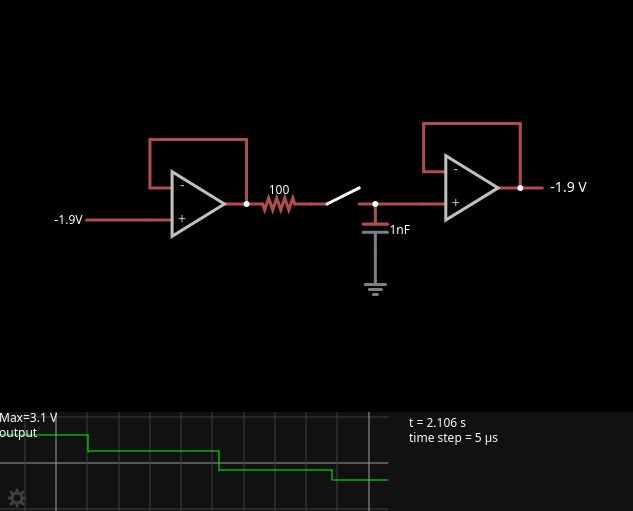
Let’s have a look at this simulation, which includes the entire “NORMAL/INVERT CHARACTER LATCH” logic:
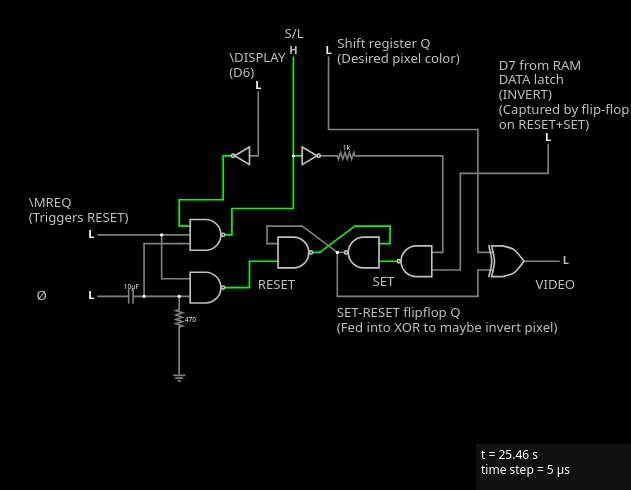
We have an S-R flipflop implemented using two NAND gates. This flip-flop’s job is to remember the state of D7 (which only briefly remains on the data bus) for 8 pixel clock (6.5 MHz) cycles (the abovementioned 3.25 MHz clock is half the pixel clock). If we didn’t do this, only the first column of each inverted character would be inverted.
How does it do this? For the most part, it’s explained on Grant Searle’s site. Have a look at this extract, though it’s mostly concerned with IC16’s job.
At the very end of the opcode execution (actually, the very start of the next opcode), the load pin on the register is very briefly (via a capacitor) pulsed low, to load whatever is being output on the data bus (from the ROM) into the shift register. The pulse is activated by a positive clock transition. This is only active when /MREQ is high. As you can see from the oscilloscope traces, the only time a positive transition occurs when /MREQ is high is at the start of the T1 state.A further blocking signal (into pin 10 of IC 16) ensures that the trigger pulses only occur when a character has been loaded (ie. when the NOP circuitry has been activated). This ensures that no data is loaded into the shift register at other times during the display.
The data that has been loaded is is then streamed one bit at a time (highest bit first) to the output (via the XOR IC 20, to invert if needed) and then passed directly to the TV modulator to convert the 0 and 1 levels into dark/light bits on the screen.
http://searle.x10host.com/zx80/zx80ScopePics.html
I think it might help to break things down a little further. First of all:
We want the S-R latch to be reset and set to the correct inversion state at the start of every character. On the ZX80 computer, one character is output by executing a NOP (while in \DISPLAY mode). On the Z80 CPU, a NOP is executed in 4 CPU cycles. The pixel clock is twice that speed, so we output 8 pixels in that time. Let’s look at the Z80 CPU’s NOP instruction timings:
We see our \MREQ in the third row. We see it’s already high when entering T1. It also goes high again in T3 and later in T4. But if our flip-flop is reset every time we get a high MREQ and a high clock, that would mean our flip-flop gets reset three times per character! Well, that’s where the RC circuit comes into play:
On one side of the capacitor, we have the CLK signal. On the other side of the capacitor, we see a really spiky signal that just goes up for a split microsecond and goes down again, and stays down (or goes down further than required, but that’s… okay). In other words, C11 and R25 implement this bit: “The pulse is activated by a positive clock transition.“
Heathkit EC-1 manual (PDF) (this manual itself lists a lot of references to books from the 1950s, most of which seem to be available on archive.org! If you’re into that kind of thing.) It looks like this manual already contains a bouncing ball circuit; a lot of people seem to be under the impression that Telefunken were the first to have such a circuit in their manual.
Analog computers were a thing, a long time ago. What do they do? They basically consist of a power supply, a breadboard-like area, a bunch of potentiometers to set input values, and a bunch of op amps in various configurations. The breadboard-like area would (for example) be color-coded and the user would attach jumper cables between different color-coded areas. However, back in the day, op amps weren’t tiny ICs that could be had for the price of a paper airplane folded out of old newspaper. They were discrete, and made of vacuum tubes (when they were invented in 1941), or, after transistors became available, discrete transistors.
Using analog computers (and op amps), you could, for example, sum voltages, invert voltages, and integrate and differentiate voltages over time. Let’s try and remember some calculus from high school or university and recall what differentiating and integrating means.
If you don’t have any basic knowledge of op amps yet, EEVBlog has a good video explaining the basics at https://www.youtube.com/watch?v=7FYHt5XviKc. It isn’t absolutely necessary to understand the basic concepts of op amps, you can just use them as “black box” integrators.
Some math
If you don’t remember much with regards to differentiation and integration, skip to the next paragraph. If you remember a bit more, here’s the ultra-condensed version of the below explanation: Differentiating a curve gets us a straight line, differentiating a straight line gets us a constant. Integration is the opposite of differentiation, so disregarding some lossy bits, integrating the constant gets us the straight line again. Integrating the straight line gets us the curve again. We can easily set a constant voltage using a potentiometer, and we can easily integrate using op amps.
Now, the less condensed version: here is a random list of facts that you may or may not remember:
Integrating is the opposite of differentiation (that’s the easy one)
Differentiation means getting the slope of a curve
Integration, being the opposite of differentiation, means that we get the curve from the slope (a slightly lossy operation, as there is more than one curve with the same slope)
You can differentiate things more than once. For example, from a quadratic curve (e.g., f(x)=x²) the first derivative yields a straight line (f'(x)=2x), from the straight line you get a constant (f”(x)=2). Integrating can be done more than once too, and as mentioned before, is the other way round, so from a constant you get a straight line, from the straight line you get a quadratic curve.
Now let’s say we have some acceleration, like… for example 9.8 m/s². (There is a planet called Earth in the Milky Way, named after the fact that some of its crust consists of earth. The same type of earth as you’d find in a potted plant. When you drop objects from a small height onto this planet, they accelerate, and the rate of acceleration is 9.8 m/s². 9.8 is very close to π² and this is not a coincidence. Also the people who live there are made of meat, but that’s a topic for another day.) So after 1 second the dropped object has a speed of 9.8 m/s, and after two seconds it’s 19.6 m/s, etc. Dropped objects get faster and faster. If you plot the speed of the object, you get a linear (i.e. straight) graph. However, if you plot the distance of the object from the point it was dropped, you get a curve, i.e., it gets steeper and steeper.
Let’s say, all we have at first is a constant, 9.8. In math terms, we could say that the function always producing this constant is f”(x)=9.8. (I added two apostrophes to “foreshadow” that we will be integrating this twice.) To get a linear function from the constant, we can integrate. The mathematical result of the integration is f'(x)=9.8x (+ some constant, which we will ignore here and below). Don’t remember enough about this to believe me? Try https://www.wolframalpha.com/input?i=integrate+9.8
This would draw a line with a rather steep gradient of 9.8. Implemented using op amps, the integrating op amp will have 9.8V on the input side, and a voltage linearly going up on the output. (Note: the op amp will invert the input, so in reality the voltage will go down, but that is not a major problem.)
To get a function that would plot as a curve from this linear function, we integrate again using a second op amp, and the result will be the function f(x)=4.9x² (ask Wolfram Alpha if you don’t remember how to do this (“integrate 9.8x”)). Now check out the formula to get the distance fallen after a time of t seconds at https://en.wikipedia.org/wiki/Equations_for_a_falling_body#Equations:
Hey, that’s exactly the same formula! (g is 9.8, 1/2*g is 4.9, and t is just a rename of x.)
(Done with the math, time to talk about some electronics)
On an oscilloscope, the Y axis is voltage and the X axis is just “time”. Oscilloscopes commonly offer another mode, the X-Y mode. In this mode, one channel’s voltage will be plotted on the X axis, and another channel’s voltage on the Y-axis. Using this mode, we can simulate the effects of gravity on the Y axis and the horizontal movement of a tennis ball on the X axis. (Of course, the X-Y mode won’t exactly make it easy to debug things, so for now we’ll mostly work in the regular mode.)
Just a few more notes and we’re ready to implement stuff on breadboards and start looking at the resulting signals on an oscilloscope!
The power supply needs to generate a negative voltage, 0V, and a positive voltage. I’m using an old ATX power supply that I bought at a thrift store and have -5V/5V as well as -12V/12V. I use -5/5V below, this makes it much easier to interface with other components. If you don’t have anything fancy, you can just use two 5V wall warts back-to-back, or a couple AA batteries in series and tapped in the middle, or whatever you want!
Constants are just arbitrary voltages input using potentiometers. We don’t have to use 9.8V, we’ll just use something that is convenient and looks okay.
To integrate an input signal using an op amp, all we need to do is put a capacitor between the input and the output of the op amp. We’ll also need a resistor to make the integration happen non-instantaneously. (Check https://en.wikipedia.org/wiki/Op_amp_integrator or similar to learn more)
The op amp’s output will be inverted
To make the integration slow enough, we need capacitors with a high capacitance. But preferably we don’t want to have to take capacitor polarization into account, so we won’t use electrolytic capacitors. I’ll be using a 1 μF ceramic capacitor, which is the highest non-polarized capacitor value I have and makes our calculations very easy. We’ll also need resistors with a high resistance in the MΩ range, as the RC delay when using a 1 MΩ resistor with a 1 μF capacitor is 1 second (1000000 x 0.000001 = 1).
To get started, here’s the setup with an op amp integrating our constant fed in using a potentiometer:
The wire on the left side goes to -5V (or -12V; currently I’m using -5V and 5V rails because that’s more compatible with the components I have on hand). The breadboard voltage rails are 5V (red) and GND (black).
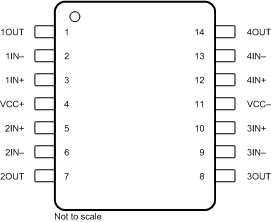
In this circuit, I’m using an LM324N quad op amp. The pinout looks like this:
(Note that the IC’s rotation isn’t the same in the above two pictures)
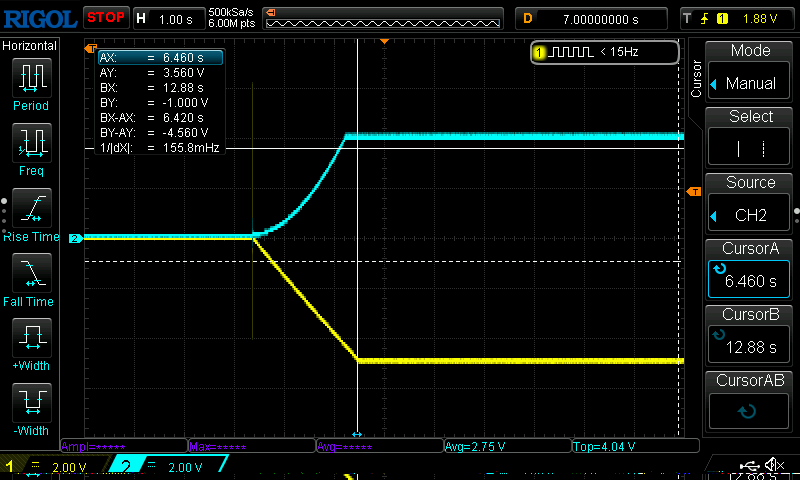
And here’s what we get on our oscilloscope:
Wow such straight lines!
Let’s integrate that straight line again. Here’s our setup:
And here’s what we see on the oscilloscope (probing the previous output stage and this output stage at the same time):
Is that all there is to the Y axis? Well, no. First of all, we are currently falling “up”. That’s easily fixed; we could just invert the signal again using another op amp. Or maybe we could simply input a negative voltage as our gravity, then we wouldn’t need to use an extra op amp circuit? Let’s not worry about that for now, we have some other things to take care of. Remember, this game/simulation is supposed to be tennis-like.
Tennis balls should bounce off the floor. Oh right, we don’t even have a “floor” yet, per se. We see that both signals reach “a floor” or “ceiling”, but they’re actually just reaching the op amp’s voltage rails (-5V and 5V) or the voltage set by the potentiometer, at which point they can’t go any further.
To make the ball bounce, we can “override” the gravity input and quickly feed in a negative voltage instead. (Of course, the gravity input is still there, just with a much higher resistance.) Conveniently, our floor is a negative voltage. (In the above pic, we’re still inverted of course. If we add another op amp, we can invert this signal.) We just need to “copy” this voltage to the – input of the very first op amp and we’ll produce a beautiful bounce. (“Cool so we just write some code and copy some variables, right.” “Wrong, sit down!”)
One immensely popular way to copy a voltage from one place to another is to use a wire to connect the two places! But in our case, we want a smart wire. This wire shouldn’t be active until we reach the floor (which is just a certain negative voltage of our choosing). Well, it may not be immediately obvious, but one of the most famous components in the world of electronics happens to have this property! We have surely heard of diodes before, right? A single standard diode doesn’t become active until we reach 0.7 V. If we use two diodes, it’s 1.4V, three diodes, 2.1V, etc. If we have negative voltages, we just flip the diode’s terminals around. Cool! But inconvenient. Here’s another type of diode though: the zener diode. Zener diodes are designed to be reverse-biased and become conductive (generally, very suddenly) at a certain voltage. So instead of (e.g.) stacking four regular diodes, we could use a single zener diode with a breakdown voltage of approximately 2.8V (and flip its poles because it’s reverse-biased).
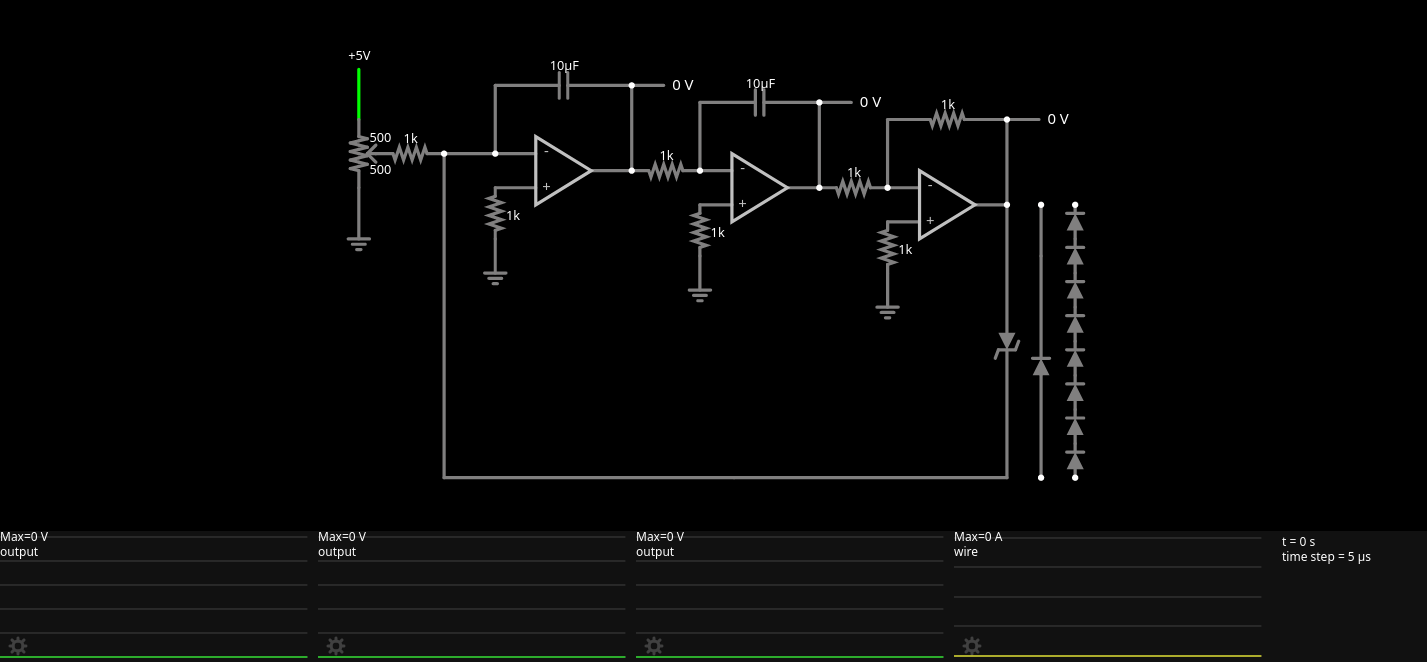
So we just connect the output of the third op amp back to the input of the first op amp, via a diode!
Here’s a simulation of this circuit. (Note 1: this circuit uses wildly different resistor/capacitor values from the ones we were using before; note 2: please press reset first) The third scope is the y output of this circuit. Feel free to experiment by taking out the zener diode at the right and plugging in the single diode (which is a hypothetical diode with a forward voltage of 10V or so) or series of (normal) diodes instead. Note that directly connecting a negative voltage to a place that already has a positive voltage will produce a large current. This current is visible in the fourth scope in the simulation.
Well, things don’t look too bad in this simulation! Currently, the ball just bounces back to its previous level, but we could easily add a little something to dampen the voltage, which I may or may not explain later:
Look at the third scope, that looks quite like what we are after, does it not?
Well, things don’t always play out the same in the real world. Here’s the output of the circuit without any damping applied. As we can see, there is some damping anyway. Furthermore, the floor voltage level moves up over time, which is something I hadn’t expected.
So instead of using a zener diode to set the floor, we might want to explore some other options.
Use an ideal diode or ideal zener diode.
Use some other type of diode.
Use a comparator to compare against a configurable floor voltage level.
Oh yeah, an ideal diode! Silly me, messing around with them non-ideal diodes. Let’s pay a couple cents more and buy some ideal ones, right?!
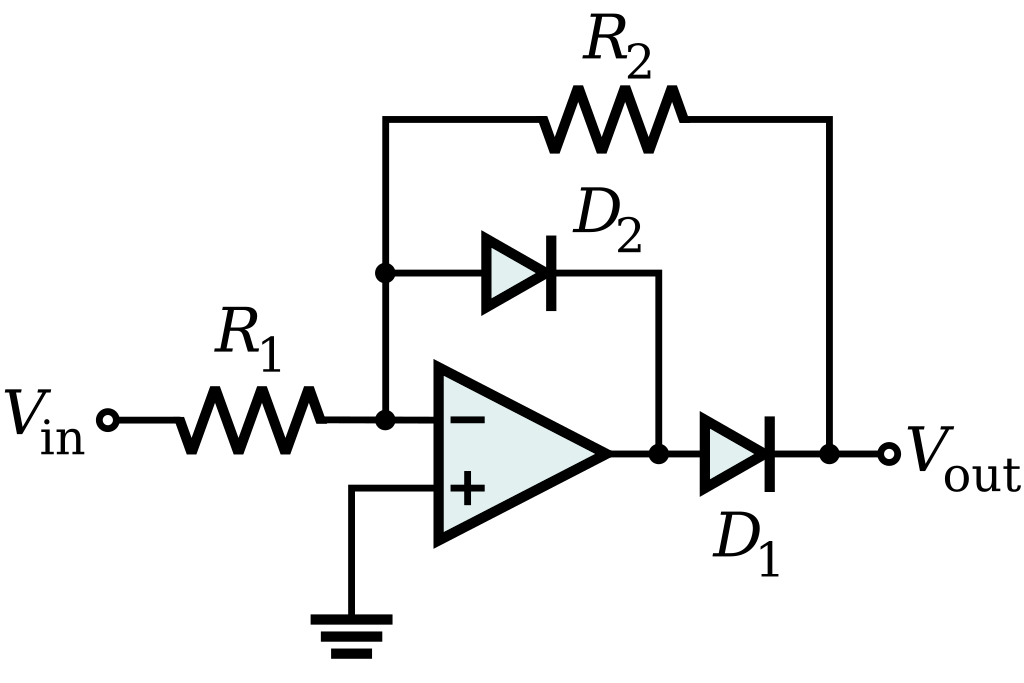
Enter the precision rectifier
Above, we described diodes and zener diodes as “smart wires” that become active at a certain voltage level. But that’s an “ELI5” explanation. Diodes are actually kind of devious; they do become active at a certain voltage, but when they do, they substract that voltage from the input voltage!
This sort of behaves like an ideal diode!And this one is even more ideal because I hear this one can be used with negative voltages.
These circuits behave like diodes that don’t have a voltage drop. な、何!? Op amps, is there any thing they can’t do? There are versions that do full wave rectification too.
By the way, we find something close to the basic version of the precision rectifier in Mubarik Mohamoud’s circuit (page 7 of the PDF):
To be honest, using these things won’t help us much on our quest to keep things simple. We don’t need a perfect circuit; let’s use some artistic license and check out some other diodes first!
Other diodes
There are other diodes out there that have a high forward voltage. For example, how about… a white LED?!
Using a white LED between the output of op amp 3 and input of op amp 1, we get automatic damping… and actually this looks pretty damn good, you’re hired!The LED blinks every time we reach its forward voltage. Kinda cool IMO! (Don’t stare too hard at the breadboard, it’s not in a clean state right now. Or the dangling jumper wire, which looks pretty close to shorting something to GND ^_^)
Of course, if we wanted to be exact and stuff, we should maybe look into using comparators instead! We’ll definitely need comparators at some point so why not check them out now.
Enter the comparator
We could also use a comparator, and yes, you guessed it, our good old omnipotent friend Op Amp can be used as a comparator, because of course he (or she) can! We’ll make an op amp compare our Y coordinate voltage with a low voltage set using a potentiometer. That’s our floor.
Op amps used as comparators always output their low voltage rail or their high voltage rail, depending on whether the input voltage is lower or higher than the reference voltage. Our above op amp had 5V and -5V rails, so the comparator would output 5V or -5V. -5V is not convenient for what we’ll do later, so we’ll convert -5V to 0V by feeding the output to a diode. The negative voltage won’t make it through, only the positive 5V. Because the negative voltage won’t make it through, it will be like the input is floating. We will add a pull-down resistor.
To make our comparators actually do stuff, we can use relays. (We could use many other things, the most simple/convenient of which might be a CD4016 or similar, but the original Tennis for Two used relays, so we will too!)
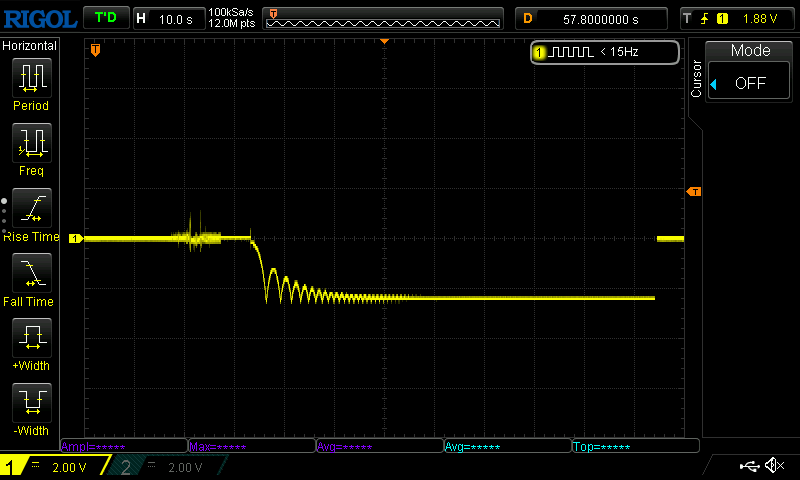
How do we connect our relay to an op amp output? Well, op amps don’t like to drive heavy loads, so we’ll use a transistor (commonly, S8050 or 2N2222), like in the following circuit. (I’m not sure if the op amps of old were able to drive relays.)
This first diode keeps away the negative voltage. I also added a pull-down to ground, because otherwise the input would be floating. E.g., on my multimeter it reads as 2V. No 0V! No, 3V! The diode in parallel with the relay is to take care of back EMF from the relay.
We’d like the ball to do something when the player presses a button. In the original(?) game (https://www.youtube.com/watch?v=s2E9iSQfGdg), the ball is able to bounce off the net in the middle, and can be hit at a configurable angle. I’d say we skip the net for now, but we should implement the button. More on that later!
For now, let’s just quickly think about what we need to make happen when a player hits the ball.
The “gravity capacitor” keeps doing its thing at all times
We just want to momentarily input a higher voltage into the first op amp’s input
This voltage can be controlled using a potentiometer
We’ll talk about these potentiometers and buttons later.
The X axis
In a nice “Tennis for Two” game, players have beautiful controllers that have a button. This button changes the current direction of the ball. (Let’s define that a little more precisely: player 1 can only invert the direction of a ball flying right-to-left, and player 2 can only invert the direction of a ball flying left-to-right.)
In addition, there should be some kind of potentiometer inside the controller, allowing players to hit the ball hard or less hard.
Before we dream of making an ergonomic controller (yes yes, it should incorporate glass and steel and Nixie tubes to display the current score), let’s think about what the X axis is even supposed to look like.
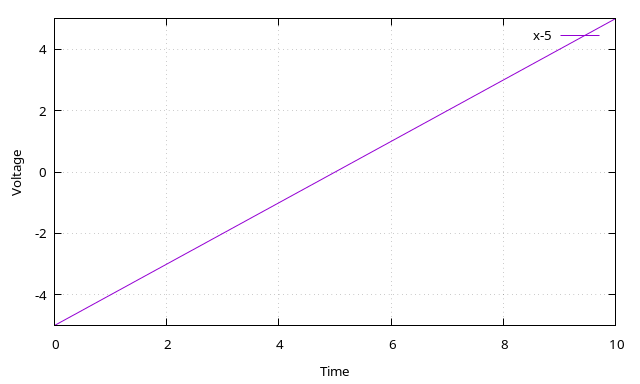
The “distance traveled” plot for the Y axis was a curve, but for the X axis, it’s a straight line. Conversely, the “velocity” plot for the Y axis was linear, but for the X axis, it’s a constant. (For illustration: in the plots below, the ball travels at a constant velocity of x volts/second.) (In reality the X axis velocity should slow down a little bit over time due to air resistance; we could model this by fudging in some kind of damping mechanism.)
The X axis circuit works like the Y axis circuit, in that it is built from op amps. However, we integrate only once. (So just a single op amp, actually.) In the Y axis, we integrated twice. (See above if you can’t remember how that worked.)
First of all, some definitions: player 1 is on the left side of the screen (where the X axis is negative), player 2 on the right side (where the X axis is positive). Here are some example graphs of the X axis:
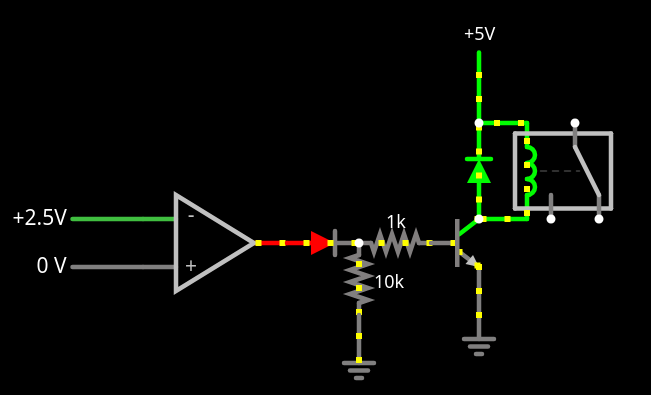
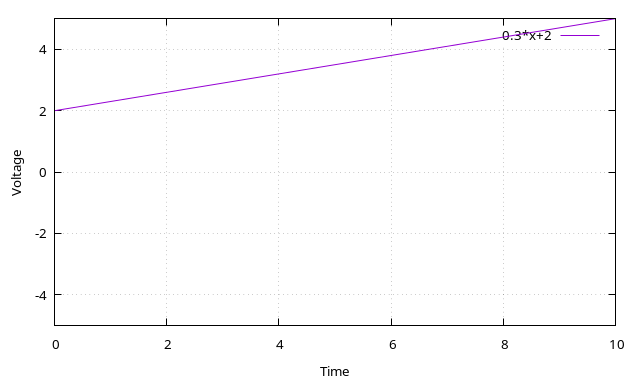
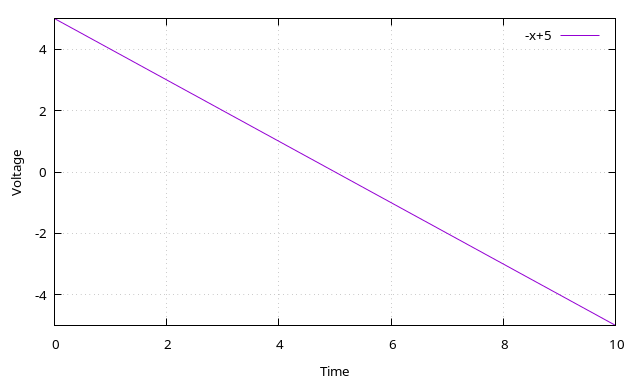
A negative voltage that is going down: ball is in left side of screen and moving farther left. Player 1 can hit the ball in this state. Player 2 can’t. Velocity is -0.3V/s.A negative voltage that is going up (like in the above picture): ball is in left side of screen and moving right. Player 1 can’t hit the ball in this state. (Most likely they already hit the ball.) Player 2 can’t hit it either. After we cross 0V (at the 5 second mark), player 2 can hit the ball, player 1 can’t. Velocity is 1V/s.A positive voltage that is going up: ball is in right side of screen and moving right. Player 2 can hit the ball. Player 1 can’t. Velocity is 0.3V/s.A positive voltage that is going down: ball is in right side of screen and moving left. Player 2 can’t hit the ball in this state (they probably already did). Player 1 can’t hit it either. (Once the voltage crosses 0V (at the 5 second mark in this graph) and goes negative, player 1 can hit the ball.) Velocity is -1V/s.
Players use a potentiometer to decide how hard the ball is hit. This potentiometer sets a voltage that represents the velocity. This voltage is connected to op amp 1.
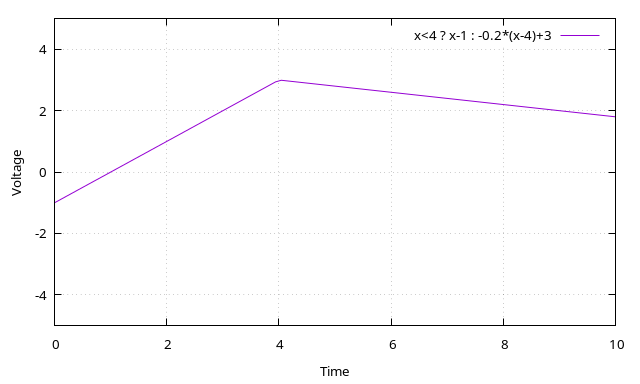
Here’s an example of the ball being hit:
Here player 2 (positive voltage, so on the right side) hits the ball relatively softly at the 4 second mark and the ball changes its direction.
(Hey, gnuplot, it’s been a while.)
There is one minor engineering problem: as the player sets the velocity with their controller, we have to make sure they can’t change the velocity after hitting the ball. If we just hooked up the potentiometer directly to the first stage op amp, the player could/would make the ball slower or faster in mid-air by fiddling with their potentiometer after hitting the ball. Not very tennis-like!
How can we do this? Well, there should be a momentary push button. If this button is pushed, there should be a check to see if we are on the correct half of the screen, and if the ball is traveling in the correct direction. This is implemented using comparators and AND circuits. If the checks pass, we apply the voltage set by the potentiometer to feed op amp 1.
We need to check conditions. We use op amps configured as comparators. We could easily use NPN transistors to form an AND gate but we’re lazy and will use 74-series AND logic chips. (Which weren’t quite around yet when this game was invented!)
Our comparators compare against the middle of the screen, which is 0V. This makes the wiring very easy: one input is the current voltage, and the other input is GND.
The other player has the inputs on the comparators swapped. (I.e., “one input is GND, the other input is the current voltage”)
One voltage is the current voltage as it is output by the X axis op amp (the absolute position of the ball on the screen), the other voltage is the voltage that is input into the op amp (i.e., the output of the sample and hold circuit mentioned below).
After checking the conditions, the new voltage is set. This immediately changes the ball’s direction, which means that the conditions are no longer true after a very short moment.
However, we need to keep applying the same voltage until the other player presses their button.
We can store the potentiometer voltage in a sample and hold circuit.
Sample and hold circuit
Well, apparently there are many ways to build a sample and hold circuit. I happen to have a (Japanese) book called 回路の素 101 that has a whole bunch of analog circuits, many of them using op amps, and among those, two circuits to do sample and hold.
If you like reading Japanese text, I recommend this book. I read it cover-to-cover a couple years back. I certainly don’t remember everything, and it doesn’t always explain everything, but I did (e.g.) remember reading about the precision rectifier (mentioned above) and that there was something similar to the hold and sample circuit.
Here are the two circuits in a simulator:
The (very) simple version (link to falstad simulation), circuit 53 in the book. (I’m using a different capacitor value.)
We can see that this circuit only holds the sampled value for a few milliseconds. The charging of the capacitor is slow, and it discharges itself pretty quickly.
The advanced version (link to falstad simulation), circuit 54 in the book. It holds the voltage rather nicely. The book uses a 220p capacitor.
In real life, I went for a 1 uF capacitor, for improved debuggability: when using an oscilloscope (or even multimeter) to make sure that your capacitor is holding the expected voltage, you will find that the voltage drops very quickly. This is due to the oscilloscope’s input impedance, which is likely 1 MΩ. Using a tiny capacitor, the voltage will be gone almost immediately. Using a 1 uF capacitor, you have a couple seconds.
“Controllers”
The controllers are conveniently placed on a hard to reach corner on the breadboard. We have two potentiometers and one button per player. When the button is pressed and the comparators’ outputs going to the AND chip look good, we drive an SPDT relay. SPDT means that the relay normally connects player 2’s potentiometer to the input of the sample and hold circuit. But when the relay is active, it instead connects player 1’s potentiometer to the input of the sample and hold circuit. (Or the other way round, it doesn’t matter much.)
The sample and hold circuit must hold a new value when either player 1 or player 2 presses their button (and the abovementioned conditions pass). This means that we need an OR circuit as well.
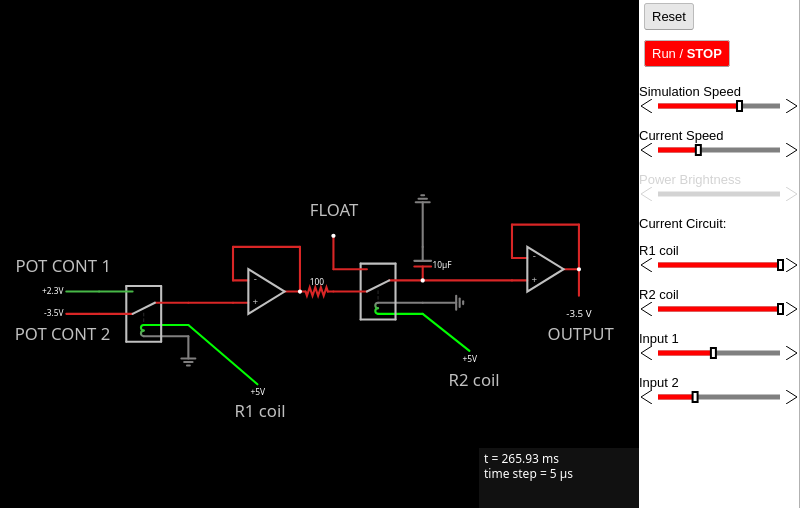
Outside the controller, we have a circuit that is inserted into the aforementioned sample and hold ciruit, as shown below. “Input 1” and “Input 2” are directly attached to the potentiometer outputs. The “R1 coil” (relay 1 coil) and “R2 coil” inputs are the binary signals mentioned above.
Here’s a schematic of this sub-circuit:
Circuit (Falstad simulation). AND circuit output is amplified using a transistor and goes to “R1 coil”. When this signal is 5V, the coil forces the relay to connect “POT CONT 1” to the output. When the signal is 0V “POT CONT 2” is connected. This goes into the input of our sample and hold circuit. The sample and hold circuit requires a switch in the middle. This switch is implemented using another relay that is controlled by the output of the OR circuit mentioned above. When the relay is off, it leaves the capacitor and op amp on the right floating. When the relay is turned on, we sample one of the potentiometers.
Other implementation notes
I used a 74LS08 chip for the AND gates. I’m using all four. I used a 74LS02 chip for the OR gate. This is a NOR chip, and I’m using two NOR gates to emulate one OR gate. The remaining two NOR gates are currently not used. These logic chips could be replaced with BJTs if you want to make the whole thing more era-appropriate, but you might find that the naive AND/OR gate implementations are a bit janky.
There is a lot of space between the “sample and hold” op amp and the “comparator” op amps. I added an op amp I didn’t need!
Putting it all together
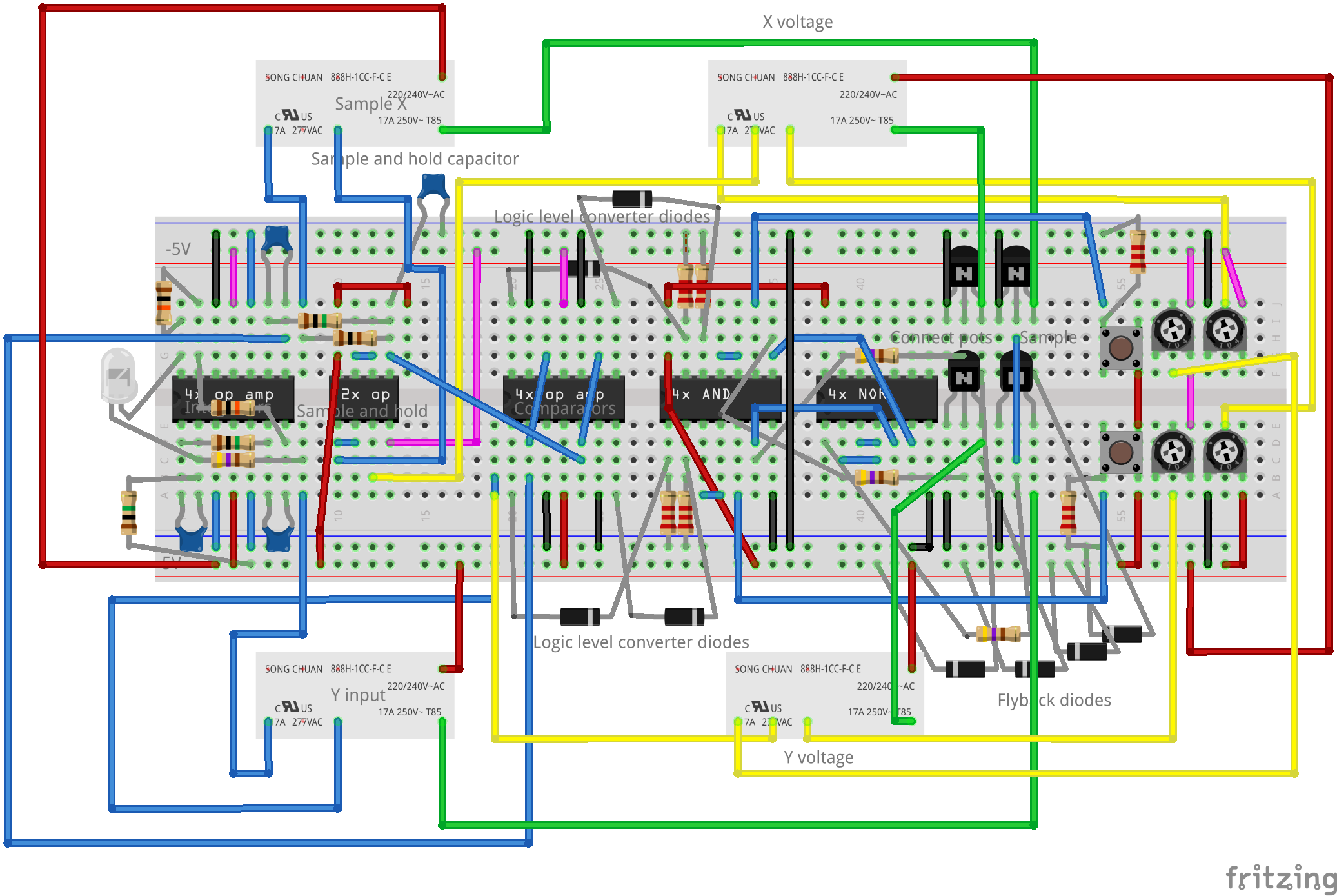
I decided to squeeze everything onto a single breadboard. To make this a little easier, I decided to build the circuit in Fritzing before building it in real life.
Change history: 2024-08-05 Initial upload (“v2”) Notes: The relays may not be connected correctly here — some things may not make sense (e.g. X and Y could be the wrong way round, or player 1’s potentiometer could be wired to player 2’s comparators, etc.) The relays shown in Fritzing (and thus the above image) aren’t the actual relays used. (Actual relays used are Omron G2R-1 5V relays. These don’t fit on breadboards, but we didn’t really have any space remaining on the breadboard anyway.) The real-life version (as seen in the picture/videos below) uses two dual op amps in the “sample and hold” region, though one is not required. There might be issues in this area. Red means a connection to +5V, purple means connection to -5V, black means connection to GND, green means connection from transistor to relay, yellow means connection from relay to somewhere on the breadboard, blue means “other connection” on the breadboard. I mostly tried to follow this rule when building the real thing, but 1) my connections from board to relay are random, 2) connections from power supply to board are all black, 3) the white wire sticking out to the right is GND and should be black. You don’t have to use LM324s and LM358s. It’s just that I had a bunch of these lying around, waiting to be used.
Pics/videos
In this video, I set the Y potentiometers to a rather low resistance. This causes the op amp’s capacitor to charge quickly. This means that the ball will be hit very high. Note: In the first shot, the ball goes above +4V, which is beyond the currently set voltage range (1V per division, oscilloscope is showing 4 divisions)In this video, I set player 1’s X potentiometer to hit the ball rather hard.
Taking things further
Here is a list of features that might be pleasant to have:
Proper controllers
A ceiling to bounce off of (I think this is just one extra diode). Should look better than a flat line when the ball hits the -5/+5V limits!
A nicer-looking ball
Some audio feedback (I thought the relays would provide this, but they’re relatively quiet, actually)
A net in the middle (both visually and functionally)
A way to detect if a player misses
Perform some game-like action when a player misses
A score counter
I think you’d need another breadboard to add all this!
Argh, I hate laptops that don’t have USB-A ports. Especially today, as I forgot my adapters at the office. Again!
I happened to have a micro USB connector with exposed conductors. I happened to have a micro USB to USB-C adapter. I have a (non-janky!) USB port with Dupont connectors. One of my best purchases from Hard Off ever. And of course I have plenty of test clips.
(I’m actually supposed to have a USB-C connector with exposed conductors, I just did a couple months ago. But I just can’t find it. Maybe haven’t seen it since moving house.)
Let’s tape it down for electrical safety
And because the power wires on this connector look rather anemic I used a powered hub. A USB 1.1 hub, BTW. Not sure if this is too janky for the blazing speeds of USB 2.0. (Also a great purchase from Hard Off, BTW.) Microcontrollers like the RP2040 and ESP32S3 only support USB 1.1 so these things are useful again these days. E.g. USB (UVC) cameras set a different descriptor when connected via USB 1.1 vs. USB 2.0. Note: my particular hub wouldn’t work until I connected the VCC wire. I don’t think this is required for all hubs.
Well, I finally had a chance to see a few of those infamous RIFA metallized paper capacitors first hand!
Yesterday, I had a look at two Apple IIe machines. One was from 1987. This computer works and is in really good condition and bears the signature of Steve Wozniak. I thought it would be a good idea to go and check for RIFA capacitors in there, but there weren’t any. Here’s a picture of its really clean power supply:
I am guessing that those two white things are the noise suppression caps.
The other Apple IIe doesn’t work. The person running this machine immediately switched off the mains line when smoke started coming out of its power supply. That’s good! The capacitor didn’t go short, and the fuse was still intact. Maybe it even reduced the amount of smoke and brown juice sprayed about its perimeter.
From the symptoms I’d correctly assumed that the owner had witnessed a RIFA capacitor explosion, so I came prepared by buying some replacement caps! I’d expected to have to bodge them due their size difference, but to my surprise, the PSU board had three holes for the noise suppression caps. The RIFA cap was using the outer holes (“holes 1 and 3”), and my smaller cap fit perfectly into holes 2 and 3! Cool beans.
Original RIFA cap (pin spacing of around 2 cm I believe) and replacement (1.5 cm). (The replacement cap has its X2-certification on the other side.)
The PSU had two RIFA caps. The one pictured above is “intact”, though it has a huge crack in its plastic case. Here are the pictures that we’ve all been waiting for, the exploded cap:
The ejected brown juice wasn’t too bad and cleaned up quite nicely.
Here is the computer put back together again, already performing advanced calculations.
The end.
Edit 2024-07-11: one more, an Apple II Plus
This guy’s power supply was riveted. What the actual? I think the screws used were some tamper-proof kind, too. The rivets were drilled out and the screws still wouldn’t come out, beyond a millimeter or so. So the screws were drilled out too. It was a bit of a nightmare. The label on the power supply said Astec AA1040. There were no RIFA caps in it.
A while ago an acquaintance asked me to build a power supply for his replica Apple 1 board. He had all parts on hand (in fact, they were the exact parts mentioned in the Apple 1 documentation and schematics, Stancor P-380 and Stancor P-8667). My acquaintance probably knows a lot more than me, so I basically just did what he asked: I drilled holes into a sufficiently nice piece of wood from the 100-yen shop, soldered connections to the transformers (I believe they were probably salvaged, but luckily still had wires attached), added a fuse, soldered an AC cable into the mix, and soldered the Apple 1 power connector. Doing all this took between 4 and 8 hours, I don’t really remember. Here’s a picture of the assembled power supply.
With multimeters hooked up to each of the voltage rails (-12V, -5V, 5V, 12V), I hid behind a big rock and pushed down on an ACME plunger detonator. The explosion… didn’t take place, and the voltages were all good. Phew! Next I hooked up a period-correct monochrome CRT, and saw an image! A very jumpy image. It was possible to adjust HSYNC on the back of the CRT, which stabilized the image, but it still didn’t look correct. Pressing RESET or any other key on the keyboard didn’t do anything.
Stable (i.e., not rolling) but incorrect image
(Note on fuses: my fuse is on the primary side, mains voltage here is about 100V. I blew a 0.3A fuse on power up, then a 0.5A fuse on power up, and am currently using a 2.5A fuse. Maybe I’ll try 1.0A or 1.5A. Or maybe I should go and look at slow blow fuses.)
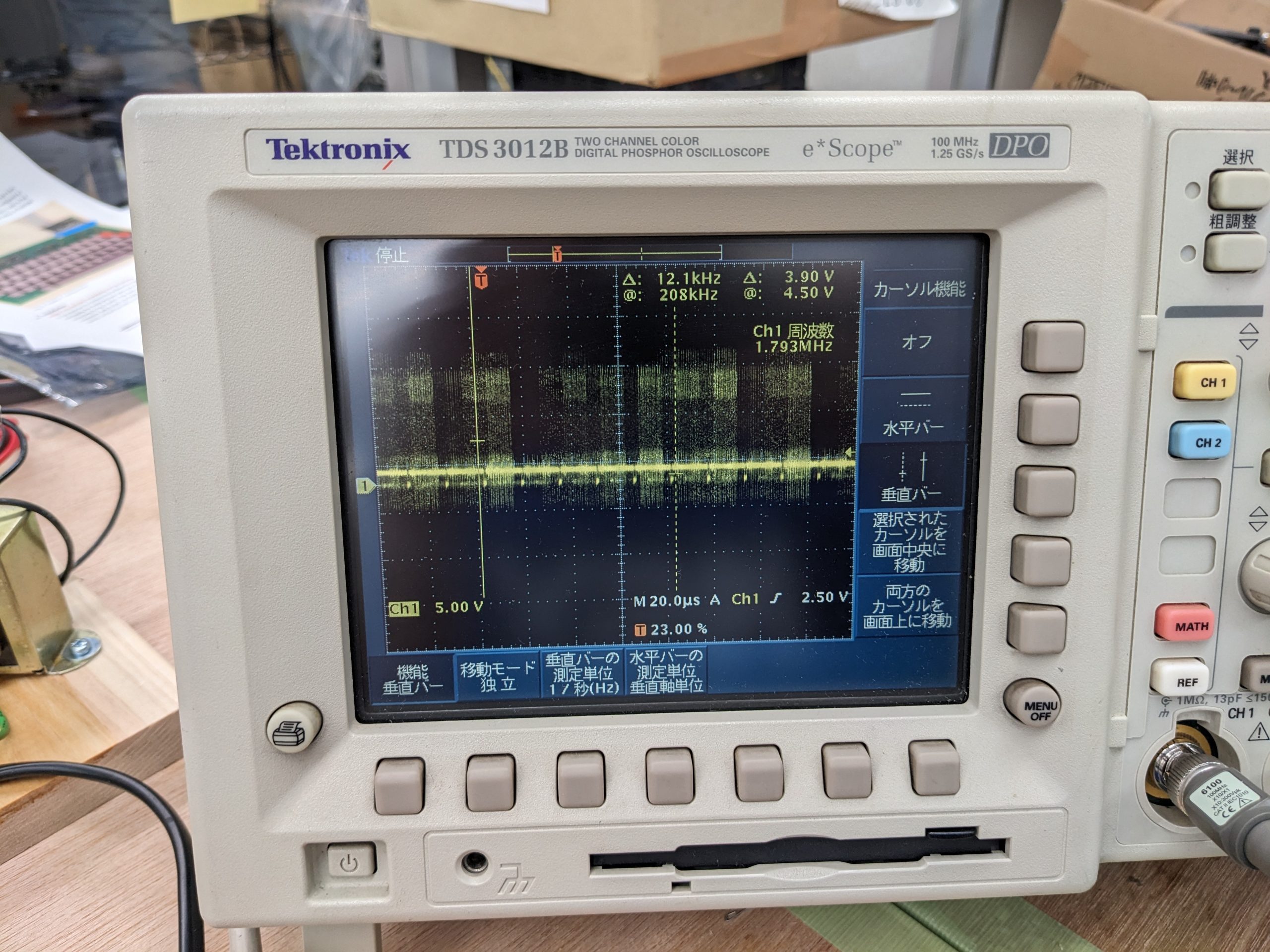
Before studying the schematics, I fired up an oscilloscope and had a look at the frequencies of the video signal. Here’s what I found:
Those small yellow blobs in regularly-spaced intervals close to the center line are the wannabe horizontal blank periods. They are supposed to have a frequency of 15.something KHz. In the above picture, I moved the oscilloscope’s vertical cursors further apart such that I get a frequency somewhat close to 15 (12.1 KHz), and as you can see we get 6 horizontal blanks in that period! This means the video signal is much too fast. I also looked for the vertical blank. It’s supposed to be 60 Hz and measured as 243 Hz. (Probably actually 240 Hz.) (At this point it’s worth worrying that we might be overclocking the CPU as well, but that wasn’t the case, it was running at a safe speed.)
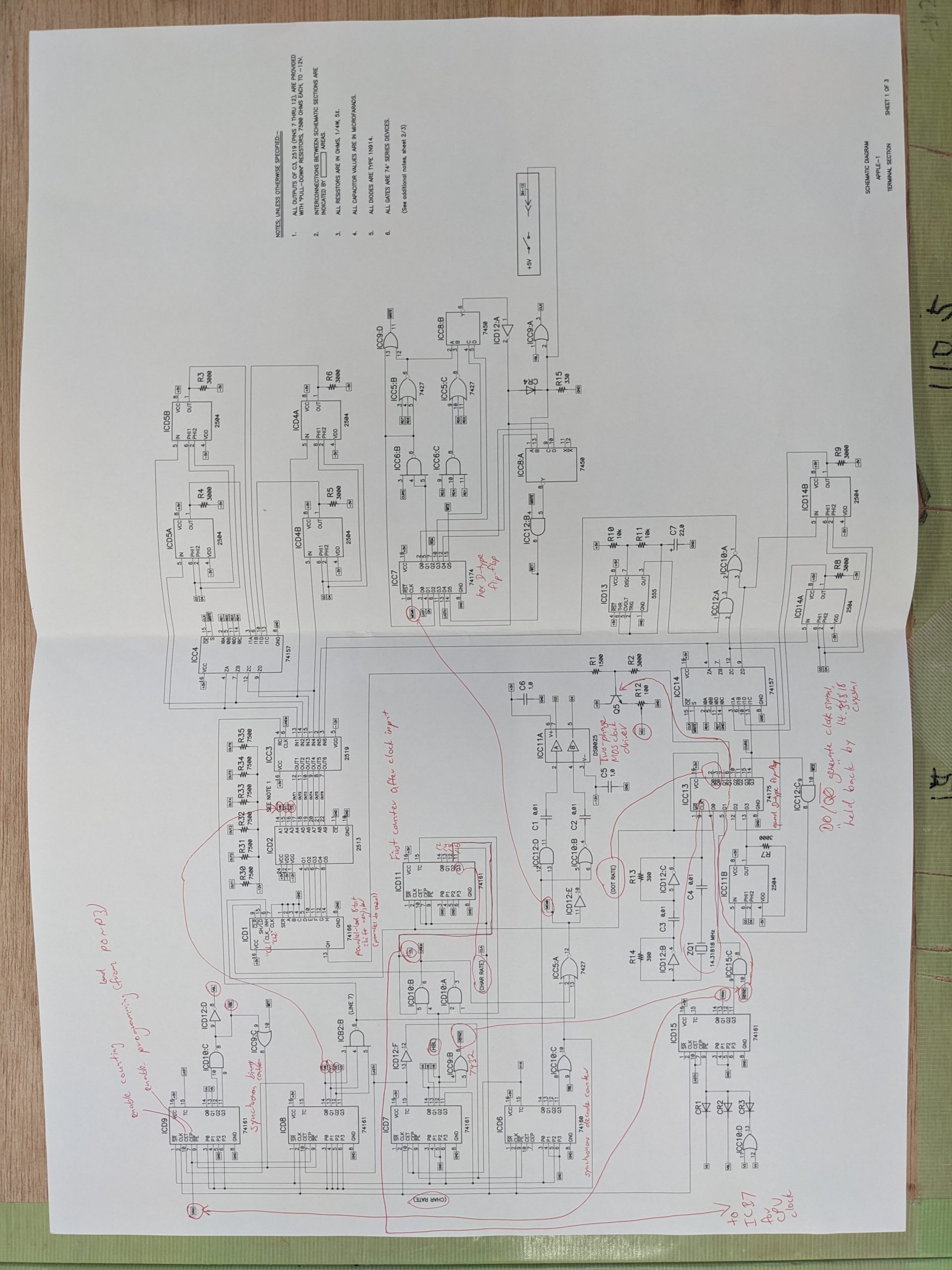
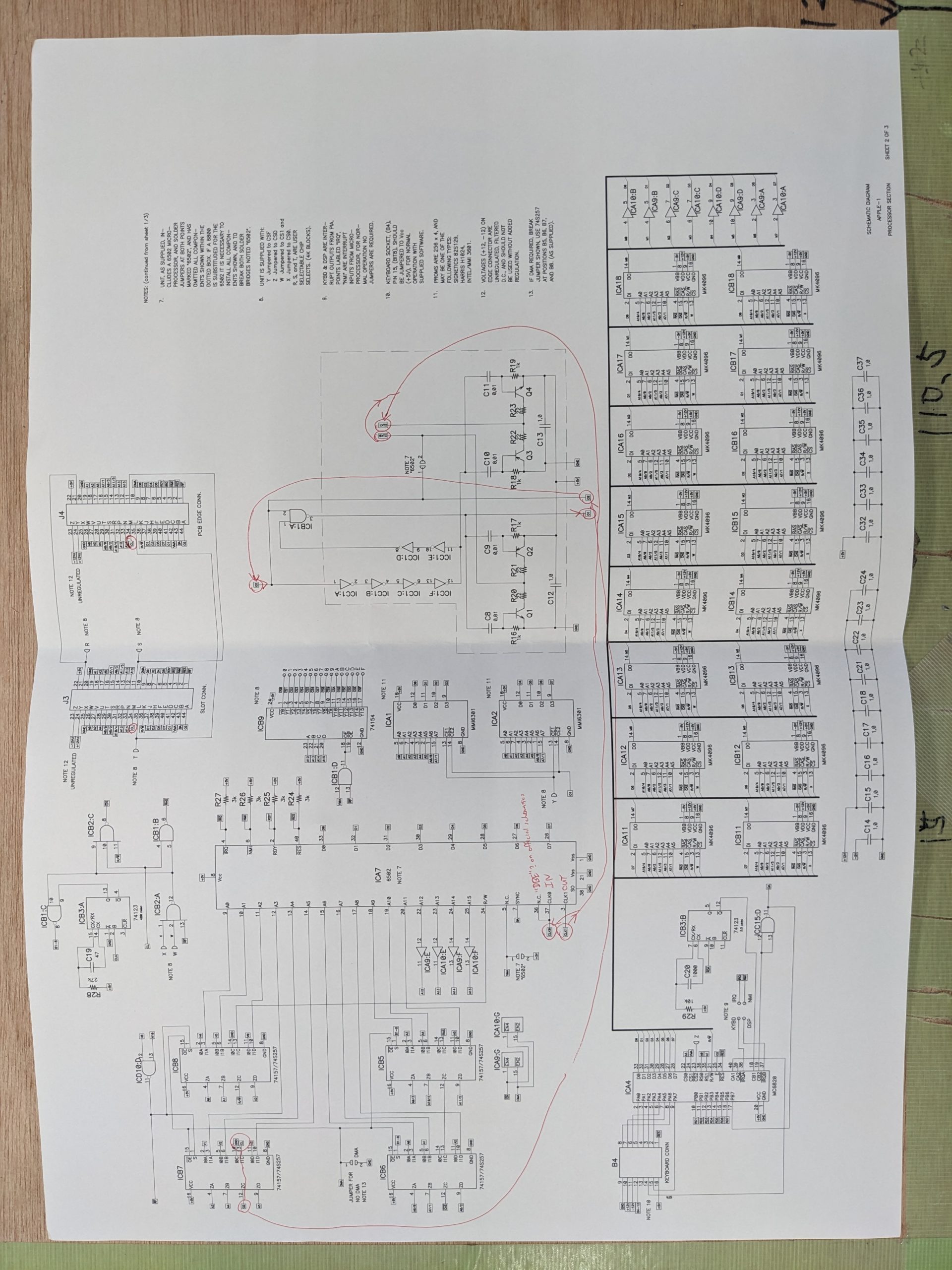
At this point it was time to print out the schematics and study them. Here’s a picture of my annotated Apple 1 schematics that I used to debug the problem:
Teletype section (Note that I cannot guarantee that all my annotations are 100% correct.)CPU section (nothing much annotated here)
Some repair guidelines
There isn’t all that much repair information on the Apple 1, but it’s not too complicated. The computer is basically two devices, a teletype that generates video, and a “computer” section that has the CPU, ROM, and memory. The two devices are linked through an MC6820 chip. There’s one more link; we also get the clock signal for the CPU from teletype section.
One more thing: when you turn on the Apple 1, the CPU isn’t live yet, because there is no reset circuit! (You have to reset the CPU manually using a special key on the keyboard.) So anything that looks too garbage-y right on power up isn’t likely to have much to do with the CPU.
Repair
After studying the schematics, I fired up an oscilloscope and traced the oscillator’s output, through the flip-flop, through various counter stages. At this point, a little luck, or a different strategy, would have helped me find the problem rather quickly, but it took at least an hour (probably more) of poking around until I found something obviously out of the ordinary: the “TC” output of the 74160 decade-counter IC was very low. Man, if it had been a Q output I’d have found it in minutes, heh.
74160’s TC output
I removed other chips the TC signal goes to, removed the 74160, checked for shorts to adjacent pins on the board, but couldn’t find anything. Which means the bad signal is produced by the 74160. Perhaps it would work with a slightly higher voltage, so maybe we’ll keep it. So we decided to see if we could get some replacement 74160 ICs (none of that Low-Power Schottky rubbish), and fortunately someone was selling them on Yahoo Auctions! We procured a few and the replacement 74160 made the problem go away!
(74LS160s or even modern HCTs/ACTs/whathaveyous would have likely worked too, but this replica board is proudly populated with original non-LS chips from mostly the 1970s. It’s all fun and games until they say good-bye!)
There were no more defects and we were able to boot into Wozmon and load BASIC from tape.
How to boot into BASIC
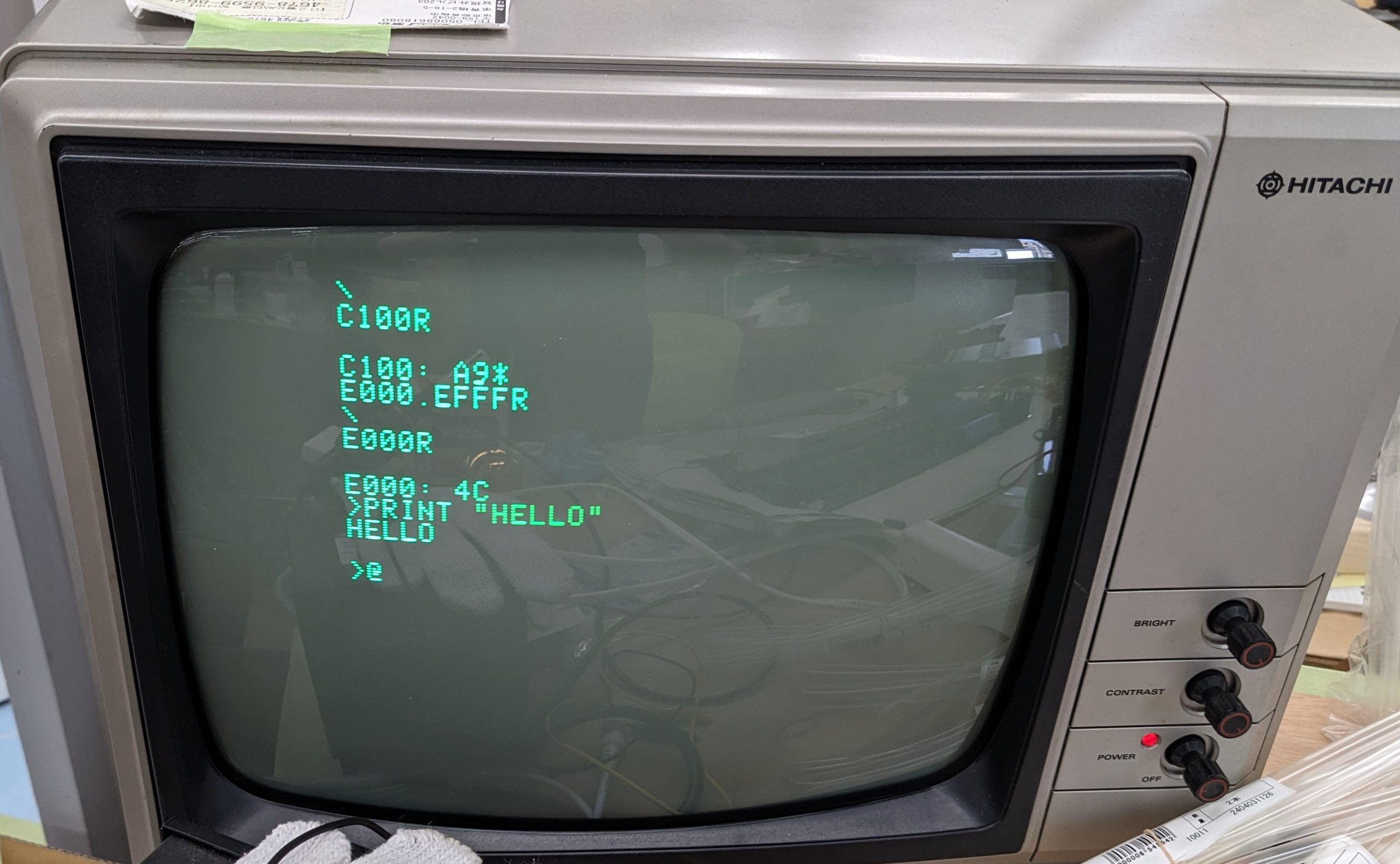
After powering up, clear the screen and reset the CPU using the dedicated keys. You should get a ‘\’ prompt. Type C100R and enter. This runs the cassette firmware. You should get “C100: A9*”. Then type in E000.EFFFR and at the same time you press enter, start playing the tape. (This loads the BASIC interpreter into memory at 0xE000 to 0xEFFF.) When the audio stops and you get ‘\’ you can start the BASIC interpreter by typing E000R and enter. The BASIC prompt is ‘>’.
The acrylic case
For some reason, the acrylic case that was purchased to put this system into didn’t have the screw holes in the right location, so I had the pleasure of adding more screw holes into the case. (Not just that, the lid needed some trimming in order to fit the cassette board, and we also decided to mod the air inlet/outlet a bit.) And though I didn’t have any experience drilling holes into acrylic (or even a lot of experience drilling anything, really), it actually went really well, using these drill bits specially made for use with acrylic: https://www.amazon.co.jp/dp/B00A630ZRE: Acrysunday アクリル板専用ビット.
It all worked out, mostly. When I did the four holes for the fan I unfortunately didn’t take into account that when screwing the nuts onto the bolts, the nut will obviously add a millimeter (or so) of height vs. just a naked bolt. (The case isn’t that high, so I just had a couple of millimeters I could move the holes up or down.) Putting the nuts on the two top bolts will prevent the lid (the one pictured above) from fitting properly, it would rest on the nuts instead of on the bottom case.
We added some heatsinks on all of the counter ICs, all of which were running rather hot (about 65 degrees after 10 minutes of operation), a powerful fan to blow air on the main voltage regulator (which sucks air through a filter so we don’t end up with a bunch of dust inside), and made a make-shift connector for the video port (J2).
Makeshift video connector using screw terminals: general ideaMakeshift video connector: placed on J2 and connected to TV input
I’ve been developing software for the ESP32 and ESP32S3 “professionally” for about one year now. I still like the Raspberry Pi Pico better, but the ESP32 line of microcontrollers is cool too. And if you need wireless and don’t really care too much about power consumption, the ESP32 (or -S3 or what have you) is a nice thing to have around.
The examples in IDF (the name of the ESP32 SDK) are really great, and you can do a bunch of stuff just by taking an example and changing a couple lines.
I’m a huge fan of the Raspberry Pi Pico’s PIO, and the ESP32 has something that is slightly similar, as-in “programmable IO”. It’s called “RMT”, and in examples/peripherals/rmt, we have a few examples that make use of this bit of silicon. The examples/peripherals/rmt/ir_nec_transceiver example is the one we look at in this article.
Basically, all you have to do is flash this to your dev board and connect an IR receiver module’s output pin to GPIO19 (and its VCC and GND to VCC and GND. Be sure to hook it up to 3.3V, not 5V.) If you want to do what this example is supposed to do (output the same signal back through an infrared LED on GPIO18), feel free. But if you just want to sniff codes, leave the infrared LED disconnected and look at the UART output.
Note that the output of the IR receiver is expected to be inverted compared to the actually sent signal. I think most IR receivers invert the signal, so you’ll most likely be fine.
Build steps
If your dev board isn’t a standard ESP32, but e.g. an ESP32S3, you first have to do:
idf.py set-target esp32s3
Then you do:
idf.py flash monitor
This will build the example, flash it to the dev board, and start a monitor.
Then you’ll see a bunch of output like this:
NEC frame start--- {0:218},{1:0} ---NEC frame end: Unknown NEC frame
But if you press a key on a remote control, you may see something like this:
And there you have the address and the command! Note that by default, extended NEC codes are allowed. (However, the remote control I used here generates a non-extended NEC code, where the second byte in the address (and command) is the first byte but inverted. I.e., 0xFF == ^0x00, 0xCE == ^0x31.)
And that’s all! If you output this using an IR LED (make sure you use a resistor), you will be able to control the device in question using your microcontroller. Note that you will probably have to move the LED rather close to the device you’re trying to control (depending on your resistor value). Note that you shouldn’t really exceed 30 mA per GPIO. I understand that most IR LEDs are good up to 100 mA, but the ESP32’s GPIO pins aren’t. You’ll need to amplify the signal if you want to go higher than 30 mA.
Sniffing IR (NEC) codes on the Raspberry Pi Pico
The Pico has a very similar demo, pico-examples/pio/ir_nec/ir_loopback/ir_loopback.c. If all you want to do is sniffing, it may work a little nicer if you comment out the sending stuff (everything from “// create a 32-bit frame and add it to the transmit FIFO” to “sleep_ms(100);”), as well as the sleep_ms(900) at the bottom. (Otherwise you’ll have to wait a little bit until your IR code shows up.) Also, it won’t do extended NEC codes. You’d have to modify nec_receive.c a little bit.
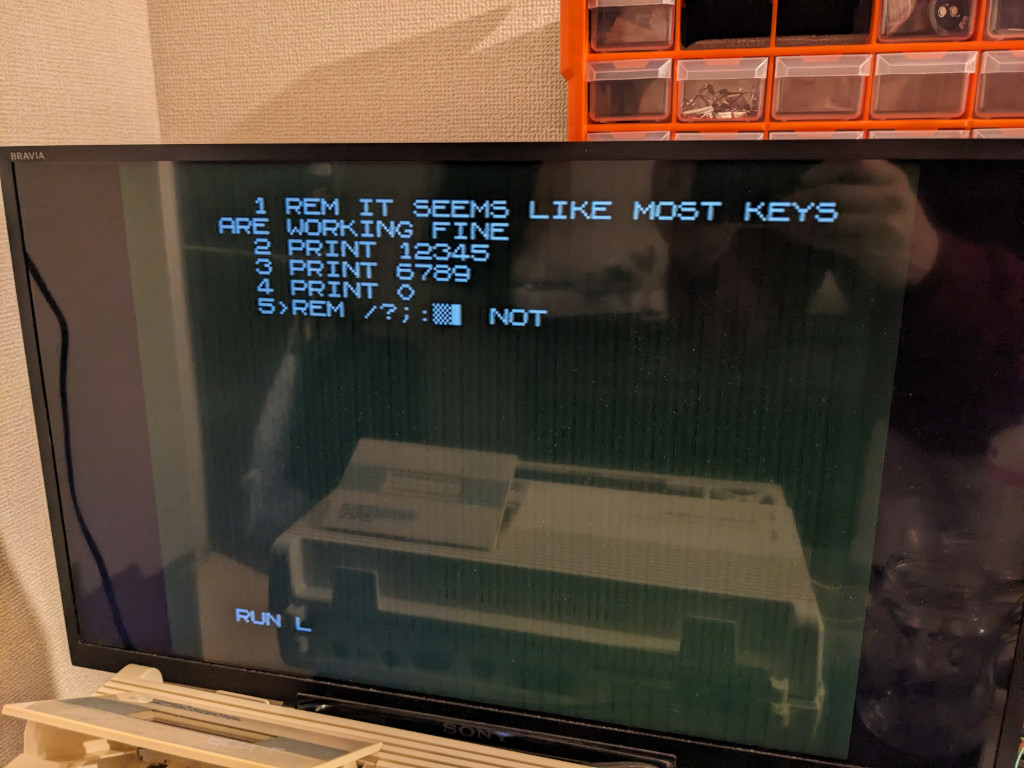
A while ago, I watched a series of videos by DrMattRegan on the ZX80 and was very impressed with the uber-hacks the designers put in there. I’m not going to go into much detail here, but here is a set of facts that may pique your interest:
The CPU’s A6 pin is permanently shorted to its \INT pin
The ZX80 has only 1 KB of RAM
The RAM is SRAM but the CPU’s internal DRAM refresh counter is not wasted
Additionally, the ZX81 was one of the first retro computers I ever repaired (article 1, article 2), which made the prospects of getting a ZX80 of my own even more attractive to me.
You have a lot of options if you want to build a ZX80 yourself. First of all, all the ICs (except the 2114 SRAM) can be bought new. There are multiple PCB designs that you can download for free, some electrically equivalent, some using chips that are a little more common than the ones on the original PCB. (For example, apart from the 2114 RAM, the 74LS93 is pretty rare because it is essentially useless nowadays. It was probably cheaper than the other 74-series counter ICs about 50 years ago, because a lot of “maybe nice to have” features were removed. It can easily be replaced using a different 74-series counter IC, and these days there really is no price difference.)
One thing that I really liked about the ZX81 that I worked on was the curved traces and the absence of solder mask on the traces. On this page by Grant Searle, you can find instructions to re-create the original PCB. There is a PDF that contains high-res images that look like this:
These can be printed out and turned into PCBs. I’m not much of a chemist, and even if the etching and tinning processes went well, I’d still need to do a bunch of drilling and then plate the newly drilled vias. Nowadays, there are companies such as PCBWay and JLCPCB that can do all this for you, and in an automated fashion, and for very attractive prices! (I do not intend to steer you away from etching PCBs yourself, in fact it always impresses me when people make PCBs themselves!)
However, these companies (currently?) do not accept bitmaps (as far as I know), they want Gerber files. So I traced the (600 dpi) bitmaps in Grant Searle’s PDF file and sent them out. I chose JLCPCB after some research because I found a pic of a board manufactured by JLCPCB that didn’t have any solder mask applied, and it looked pretty much the way I wanted it! However, I’m sure that PCBWay could do the same.
In order to get a board without solder mask, you have to get rid of the solder mask layer in the SVG or Gerber file, and you probably should also add a comment stating that this is intentional. I added this in my order, no guarantees the Chinese is correct: “The Gerber files don’t have a solder mask. This is intentional. Please do not apply a solder mask. Gerber文件没有焊膜。这是有意的。请不要应用焊膜。 我们有会说中文的人,所以如果你有什么问题,可以说中文。” I ordered 5 boards (which is the minimum order), lead-free HASL, white silkscreen (“ink-jet/screen printing silkscreen”), no gold fingers (not present on the original PCB either), regular PCB thickness (1.6 mm), regular outer copper weight (1 oz), regular via covering (tented), no castellated holes. JLCPCB’s customer service recommended I switch to ENIG, but it worked out fine with regular lead-free HASL. The price was $18.02 plus $11.70 shipping, minus the first time discount ($5).
When exporting the Gerber files in KiCad, you should follow the PCB manufacturer’s recommended settings. JLCPCB and probably most other places have a support page for this, this is JLCPCB’s.
A glimpse of the outcome
Tracing bitmapped PCB foils
I used Inkscape to trace the PCBs in the PDF. Tracing is easy, you just load a bitmap and then go to “Path” -> “Trace Bitmap…”. But how do you convert that into Gerber files? Well, there is an extension that converts SVG files to KiCad files, svg2shenzhen.
It still took me many, many hours though. Why?
Converting traced holes to actual drill holes
svg2shenzhen expects “circle” shapes in a layer called “Drill”. If that layer doesn’t exist and/or it doesn’t contain circles, there won’t be any drill holes in your Gerber file. I wrote a very simple Inkscape extension to do this: Converting paths to circles in Inkscape
But first, we need to separate out the holes into a single layer. To do this, we first break apart the path containing all the traces (“Path” -> “Break Apart”). Then everything that isn’t connected together, and everything overlapping other things will exist as separate paths. Holes overlap other things and thus will be separate paths. And they will be obscured by the outer path. Now you just click on the surrounding path and remove it, perhaps like this:
One more consideration is hole size. Though the details are a little hazy now, selecting multiple circles and changing their size all at once didn’t work very well for me in Inkscape, so I just edited the SVG file directly.
The traced circles are paths that more or less look like circles, sure. But they’re often slightly oval or otherwise unshapely and not all the same size. So when you (after using the extension) crack open the SVG in a text editor, you may see that the radii are slightly different everywhere:
I just did a find and replace operation here and used holes sizes that seemed good to me (after JLCPCB support telling me that my holes were rather small). And damn, by sheer dumb luck, I chose the best hole sizes ever (0.4 mm) and my jumper wires fit right into them without using clips; they make almost perfect contact. Maybe 0.375 mm or so would have been even better? (The other hole sizes I chose were 0.8 mm and 1 mm.) (Note: PCB manufacturers don’t have every drill bit in the universe, so 0.4 mm and 0.375 mm may just end up being the same drill bit.)
Excellent hole size.
Update 2024-04-19: the holes for the headphone/microphone/power connectors are too tight though. :(
Adhering to minimum spacing constraints
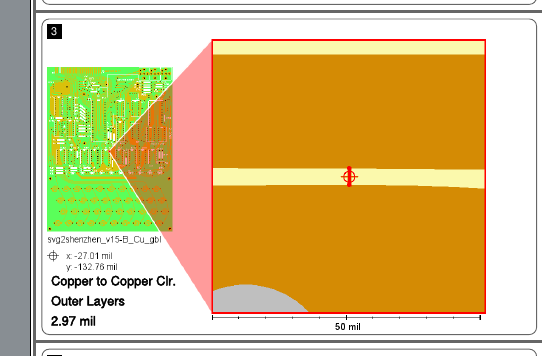
PCB manufacturers require that certain spacing constraints are observed. For example, traces may need to be 0.125 mm apart. The original bitmap you have may or may not adhere to the spacing constraints. I don’t know whether the bitmap in the PDF adheres to them! But I certainly do know that my order was rejected because the traces in my Gerber file weren’t quite up to snuff.
How would I even find out what my minimum spacing is? Well, I found this page by yet another company that makes PCBs: https://instantdfm.bayareacircuits.com/. This page analyzes your Gerber file and sends you a snazzy PDF with close-ups of your horrible transgressions. This is a screenshot from an early version of my Gerber files:
2.97 mil… that’s 0.075438 mm. Less than 0.125 mm!
So I manually fixed this location and re-submitted, and sure enough, there were plenty of other similar narrow gaps. So I decided there must be a way to get Inkscape to find these critical regions, and this is what I came up with:
I just gave every object a 0.125/2 mm = 0.0625 mm border, and then zoomed in a bunch to look for objects that were touching each other. (Actually I probably added some to that value, but a couple months have passed and I don’t remember.)
Border color is set to red here. Lots of… intimate traces!
Mistakes
As mentioned earlier, in Inkscape, when you break apart a path that contains “holes”, you’ll end up with a large mass obscuring the holes. Here’s a video of exactly that:
Look at the large black regions with holes, especially near the top left. The holes will “disappear” (they will be obscured) after breaking apart the path.
Well, I failed to notice that a number of holes within these black regions had been obscured. And thus they came out like this on the PCB:
IC3 and IC14 have their left pins all sewn together. There were a couple similar spots elsewhere, but you get the idea.
While annoying, I was able to fix this using a utility knife. Boy, that utility knife’s blades went dull quick. (Luckily, my utility knife is one where you can just snap off consumed blade chunks. Having done this for the first time in my life, it was quite scary, to be honest. I did it behind a glass window.)
Very beautiful, I know. However, once you have soldered the IC sockets, all this is mostly hidden underneath the sockets.
Procurement and assembly
After taking care of these mishaps, it was time to do a bunch of other stuff, such as celebrating Christmas and the New Year, and at some point bite the bullet and solder sockets and resistors and capacitors. I soldered everything using lead-free solder, and most or maybe even all of the components I put on the PCB are lead-free too, including the Z80! So maybe this is the first RoHS-compatible ZX81?! (Except the 2114 SRAM chips most likely aren’t RoHS-compatible. We’ll talk about those in a later section, BTW.)
I had half of the 74-series logic chips in stock. (From when I got Ben Eater’s DIY 8-bit computer, which I never assembled. I used the breadboards and some of the other components for a host of other things though!) The other half came from a small electronics shop right next to my office in Machida, サトー電気. I wanted a RoHS Z80 (print on chip ends in -PEG rather than -PEC), and bought it off Amazon.
Update 2024-04-19: Zilog/Littelfuse are reportedly discontinuing the original Z80 CPUs after almost 50 years of production! Maybe get them while they’re still available. Only source so far: https://www.mouser.com/PCN/Littelfuse_PCN_Z84C00.pdf (zilog.com still seems to list everything as “active” at the time of this writing)
For the ROM I’m just using my EEPROM that I’ve been using in other projects. Since it’s huge and has a slightly different pinout, I’m currently using a breadboard as an adapter.
Putting jumper wires in IC sockets permanently damages the sockets. Here I am plugging the jumper wires into a sacrificial socket that I plug into the soldered socket. This way the soldered socket doesn’t get damaged.
The only thing I couldn’t get anywhere, including Akihabara, is the 6.5 MHz oscillator. Many people use a 6.5536 MHz crystal in their ZX80 builds (hmm, I’ve seen a number like that before!) because the 6.5 MHz ones are pretty rare. But even those didn’t seem to exact in my neck of the woods. I ordered a 6.5 MHz oscillator off Digikey (through Marutsu) and will probably have it in a few days. (By the way, the original ZX80 used a 6.5 MHz ceramic resonator, but these seem to be just as unavailable. But who knows, maybe I could have gotten a 6 MHz one and filed it down a bit to get it to 6.5 MHz? But crystals work even better, and are probably a little better for the environment because ceramic resonators are made of lead zirconate titanate. Note that they are exempted from RoHS regulations and can be labeled RoHS3-compliant as long as their leads do not contain lead, I guess.) So I’m using a Raspberry Pi Pico to generate the clock signal for now.
I had some problems with the clock though:
I forgot to solder on R20. This resistor is needed in the clock circuit. Fixed using jumper wires.
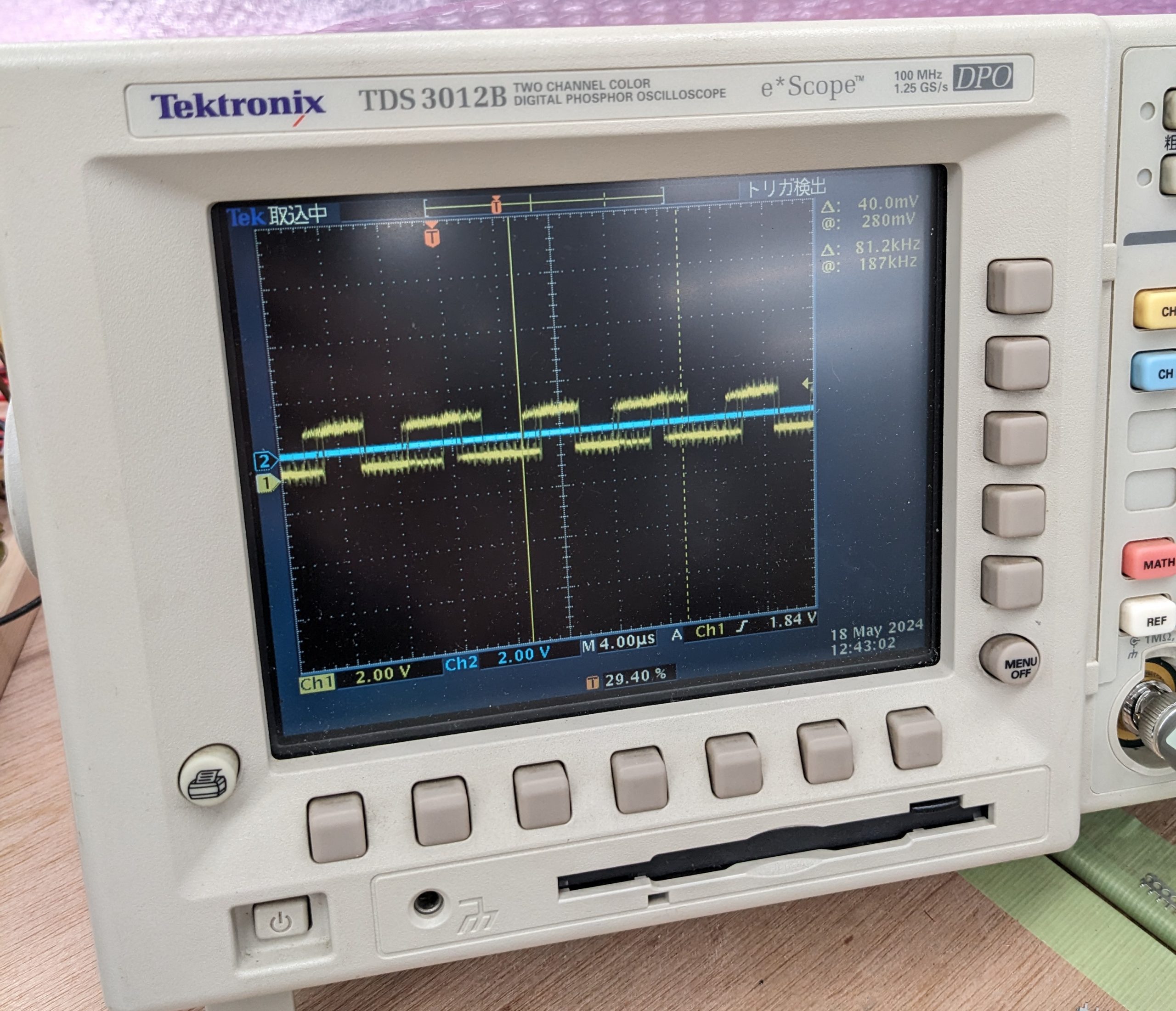
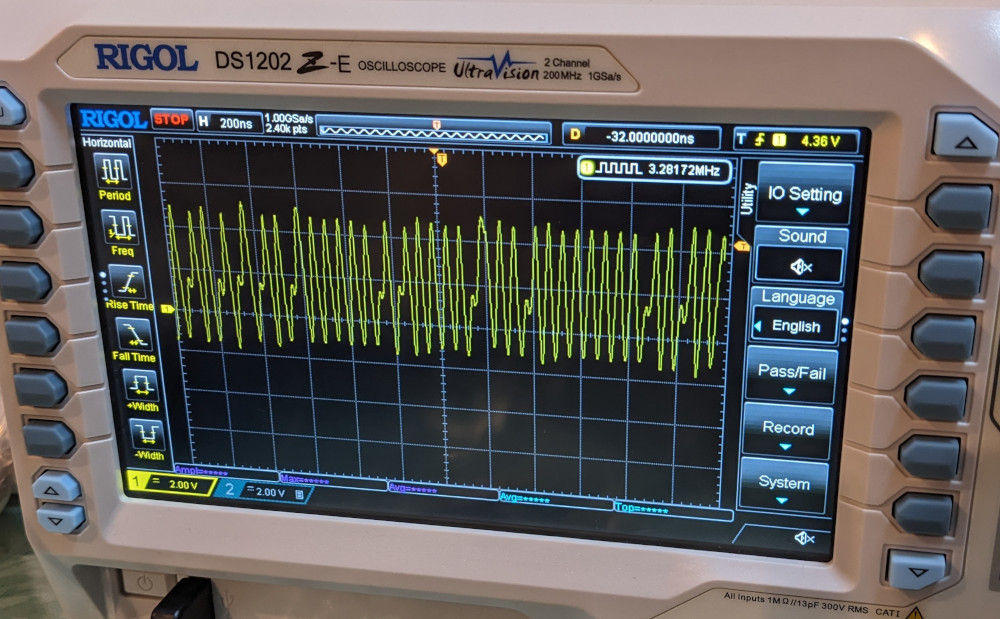
I changed the Pico’s output pin from GPIO0 to GPIO2 and failed to re-wire. I then suspected the Z80 was bad and tested it on a breadboard with the data pins tied to ground to emulate NOPs. Eventually figured out the problem (dur). It was difficult to figure out at first because the circuitry on the PCB picked up the output from GPIO2 as noise, and amplified it to produce something like a clock signal. Except that this was a very dirty clock signal (see image below)! It is interesting that the Z80 seems to detect that the clock is a little cuckoo, and while it works for a split second, it quickly calls it quits and the address bus freezes in a random state. That seems like a useful thing to be aware of! (Could of course be that this is not an intentional feature, or that it’s just seeing a HALT instruction or something.)
While testing the Z80 on the breadboard, I set the Pico’s clock output to 3.25 MHz. I then forgot to change it back to 6.5 MHz.
Temporary R20 fixDirty clock that quickly made the Z80 seize up.
RAM problem
The 2114 RAM chips originally came out of the Commodore PET that I fixed two years ago. I removed them from the PET because they were a little faulty, but kept them because they still mostly worked. Lucky! I had three, and hoped two of them would work well enough to at least get the ZX80 booted. Well, I picked a lucky one and an unlucky one. I didn’t see anything on the composite output. (Which at the time of writing is just a hole in the PCB. The ZX80 and early versions of the ZX81 don’t produce a back porch, but that problem is somehow fixed or alleviated or otherwise rendered irrelevant inside the modulator. The problem just manifests itself when you decide that the wire leading into the modulator is now going to be composite output. Back when I was looking at the ZX81 at the computer museum in Oume, I used a 555-based circuit that I got from here to fix the problem.)
Not knowing whether it’s a RAM problem or a serious problem with the PCB, I broke out my Pico-based logic analyzer. This time I didn’t bother adding resistor dividers because all Picos I have (I think I have four) turned out to be a least a little 5V-tolerant, and I wouldn’t be using the logic analyzer for a long time.
I needed to make some minor modifications to the logic analyzer code: the reset circuit in the ZX80 uses a 220K pull-up resistor (it’s very high value because it is also a 1 second (or so) RC delay circuit), and the Pico by default has pull downs active on its input GPIOs. These pull downs are much lower in value than 220K, effectively keeping reset asserted forever. (They are surprisingly low!) So the init code now looks like this:
stdio_init_all();
gpio_init_mask(ALL_REGULAR_GPIO_PINS);
gpio_set_dir_masked(ALL_REGULAR_GPIO_PINS, GPIO_IN);
gpio_disable_pulls(TRIGGER_PIN); // default is pull down; this pull down is much higher in value the the zx80's reset circuit's pull-up and therefore holds the cpu in reset
Of course, it would probably be even better if we disabled all pulls on all GPIOs. Anyway, running the logic analyzer, I quickly found a RAM problem with bit 4.
Here is the logic analyzer output with the problematic signals:
The first number is just the line number, the second number is the number of times the third and fourth numbers are repeated in the logic analyzer output (which is not in sync with the clock, but much faster). You can ignore everything that is less than around 10. In the above output, we are fetching and then executing the instruction at 0x0283~0x0285. Here is the relevant assembly source:
So we can see that we are putting 0x4028 into hl, and then incrementing hl, which means that hl should now be 0x4029. The instruction at 0x280~0x282 puts hl into 0x400a, and the instruction at 0x0283~0x0285 reads it back from the same address. So we should be putting 0x4029 in there (though not shown above, we are) and should be reading 0x4029 back. But the relevant parts of the logic analyzer output are like this:
124 25 000a 21
126 25 000b 40
Don’t worry about this showing 000a and 000b rather than 400a and 400b. I just don’t have the higher address lines connected to the logic analyzer. We’re reading back 0x4021! That’s missing the fourth bit. So I put in the other RAM chip and bam! I see a lovely 15.something KHz signal on the through hole that would normally be occupied by one of the modulator’s leads! (Well, actually I saw a 7.65 KHz signal because I forgot to change the Pico’s clock output back to 6.5 MHz, but while that was very puzzling for a bit, it was very easy to fix.)
The computer resting on top of that old laptop is the newer one!It’s working! Never mind the Hitachi MB-H2 in the reflection.
I’m currently using two of these smartphone stylus…es to operate the keyboard on the PCB (one for shift and the other for every other key).
There’s a problem though: I’m not able to press keys like ” and many other shifted keys. I haven’t properly looked into that problem yet. However, I did do a quick internet search and found someone with the same problem:
For example, all of 1 to 0 keys work but shifted, only 1 and 0 work. Some other shifted keys don’t work but there doesn’t seem to be a consistent pattern on each row. The display still flickers when say shift 2 or shift 9 (or other combinations) is pressed, just nothing else happens.
But their problem was apparently caused by using super long wires on their keyboard. I’m not doing that as far as I know?!
As my EEPROM is currently mounted on a breadboard and my EEPROM is 512 KB while the ZX80’s ROM is just 4 KB, I have plenty of space left. So I put the ZX81 ROM image at address 0x10000, which means I just need to change the wire on the EEPROM’s A16 pin from 0V to 5V to change to that ROM. And it works too! Plus, the keyboard layout is different, which means I’m able to access the ” key and print out a proper message rather than just numbers:
To do
Solder crystal oscillator (when I get it) and R20, and maybe headphone/microphone jacks, etc.
Backporch generator
Make a proper ROM adapter?
Get all shifted keys to work
RAM expansion
Try to load some software
Make the keyboard more ergonomic
Maybe get some kind of case
KiCad / Gerber files
Here are the SVG and KiCad files, with the above mentioned shorting issues most likely fixed. Some important notes:
I do not have permission from Grant Searle nor from the copyright holders of the original ZX80 PCB to post anything like this, and if either of these parties asks me to take my files down, I intend to comply swiftly. (I’d just need to be sure that you are who you claim to be. I apologize in advance for any grievance caused and will apologize again if grievance is actually caused.)
I used Grant Searle’s replica foils as a base and traced them in Inkscape. I performed some manual and some automated tweaks. This version of the board is likely a less faithful replica of the original board than Grant Searle’s foils. (I don’t think anything’s shifted more than even 1 mm though. Though maybe the holes are quite different. I didn’t encounter any problems with the drill holes while soldering though.)
I haven’t tested (i.e. manufactured) this version of the KiCad files, I have only ordered one set of the ZX80 boards, with the shorted pins. This issue should be fixed now, and I hope I didn’t add any new issues.
I haven’t updated this post in a while; in the meantime the above TODO list has changed as follows:
Solder crystal oscillator (when I get it) and R20, and maybe headphone/microphone jacks, etc. Very low-hanging fruit, done. The headphone/microphone jacks I got had thicker pins that I had expected, and I had to widen the holes in the PCB a little bit.
Get all shifted keys to work ← While it’s already almost one year ago, I had a good look at what’s going on. I’m betting that it’s my breadboard-based ROM adapter that is adding capacitance into the circuit. Together with the resistors (the ones positioned between the ICs and the keyboard), I observed a long RC delay that prevents signals from the key press to rise/fall (can’t remember which) in time. I used lower value for the aforementioned resistors but couldn’t get all keys to work while using the 4 KB (ZX80) ROM. However, using the ZX81 ROM, it looks like the programmers gave us more time and everything just works (I already replaced the resistors so not sure if it worked with the original ones). Thus I’m usually using the ZX81 ROM.
A happy Pico enjoying a round of Mario Kart. (This particular Pico is doing something else, but it’s content watching its brother play.)
Well, it’s time to put 2 and 2 together and get that silly PS3 controller to work on the Switch! (Or on other devices supported by GP2040-CE, which as I understand includes the Xbox and PS4/PS5?) To do this, we just have to realize that the PS3 controller works on Linux. So we just need to figure out how Linux does it. And a quick Google query (though I can’t remember the words I chose) surfaced up an old patch from 2007 introducing PS3 support to the Linux kernel:
Add the USB HID quirk HID_QUIRK_SONY_PS3_CONTROLLER. This sends an HID_REQ_GET_REPORT to the the PS3 controller to put the device into ‘operational mode’.
So, how could we do this in 1) our code that we used for the MSX, and 2) in GP2040-CE?
Modifying Pico-PIO-USB to work with the PS3 controller
Pico-PIO-USB isn’t very over-engineered yet(?!), and we can just modify the enumerate_device function in pio_usb_host.c to check if we’re seeing a PS3 controller, and send the request. Near the bottom of this function, we send the “get_hid_report_descrpitor_request” to the USB device. Immediately after we add our own code, as below:
diff --git a/src/pio_usb_host.c b/src/pio_usb_host.c
index 864d048..0efc567 100644
--- a/src/pio_usb_host.c
+++ b/src/pio_usb_host.c
@@ -1018,6 +1018,21 @@ static int enumerate_device(usb_device_t *device, uint8_t address) {
printf("\n");
stdio_flush();
+ // We need to send a special HID request otherwise the contoller won't do anything
+ if ((device->vid == 0x054c) && (device->pid == 0x0268)) {
+ usb_setup_packet_t get_hid_report_ps3_controller_request =
+ GET_HID_REPORT_PS3_CONTROLLER;
+ control_in_protocol(
+ device, (uint8_t *)&get_hid_report_ps3_controller_request,
+ sizeof(get_hid_report_ps3_controller_request), rx_buffer, LINUX__SIXAXIS_REPORT_0xF2_SIZE);
+ printf("\t\tPS3 controller response:");
+ for (int i = 0; i < LINUX__SIXAXIS_REPORT_0xF2_SIZE; i++) {
+ printf("%02x ", device->control_pipe.rx_buffer[i]);
+ }
+ printf("\n");
+ stdio_flush();
+ }
+
} break;
default:
break;
This requires the following definitions to be added in usb_definitions.h. I just used the same names used in Linux (not the ancient 2007 version, but something recent):
So, will the same modifications work in GP2040-CE too? No, while GP2040-CE uses Pico-PIO-USB to get USB host functionality to work at all while the Pico is busy being a USB device, protocol-y stuff is handled by TinyUSB, which by the way is included in the Pico SDK. Looking at pspassthrough.cpp for inspiration, I found that if we just add the following code to our previously modified version of src/addons/keyboard_host.cpp, our PS3 controller wakes up from its daze and starts sending our inputs!
Before Commodore made computers, they made typewriters, and later calculators. I scored one such calculator, one that was listed as “non-functional”. The repair itself was very quick, as I had expected.
Repair
Honestly, it was just the power adapter. And some gunk in the keys. I’ll spare you the details on the gunk for today. Let’s see what’s wrong with the plug. Here’s the picture from the listing:
The pic from the listing.
Why would you bother to take a picture with the AC adapter cord connected to the calculator but the AC adapter not plugged in? Well, while I didn’t really think too much of it when I saw the listing, I quickly found the answer after it arrived here: it’s damn near impossible to get out of there!
Until I got out some pliers and turned it left and right while pulling a little bit for a while. The cable was really sticky, and I believe (though this is half a year ago already) pretty much glued the connector to the device.
So, did they use a bit of an unusual plug shape? Yes, they did! It looks a bit like a mono headphone connector, maybe a bit thicker? (That reminds me, the ZX81’s power connector probably uses something similar.) But anyway, my trusty 28 in 1 “28 in 3” plug set (https://www.amazon.co.jp/gp/product/B01NCN3P3B/) contained something that fit beautifully, and applying power at about 9V, the calculator sprang to life.
Original connector (top) and replacement connectorGlorious LED displayDevice’s innards. I didn’t take it apart any further than this, but cleaned up the gunk. Apparently didn’t take an “after” picture though, so you’ll just have to trust me that it looked as clean as a whistle afterwards. Maybe.
Review
So you are thinking of buying a calculator, and hey, you’ve always wanted to show off how cool retro tech can be. Someone nearby is selling a retro calculator with an LED display. It looks fantastic! But will it be useful?
The Commodore SR-37 does pack a lot of functions, maybe not quite as many as a modern scientific calculator, but it’s not far away. (For example, you can’t easily convert degrees to radians.)
So let’s see how useful this thing is. I’ve thought of some expectations the modern calculator user may have that aren’t quite fulfilled by this device:
Expectation
True: ✓ False: ✗
Doesn’t use power when turned off using power switch on device.
✗
Doesn’t use a lot of power. So for example not 1.4 W even when you make it display 8888888888888888888888.8.
✗
Doesn’t turn off the display to conserve power after a short while.
✗
Doesn’t take a long time to compute, e.g., exponentials or roots. Definitely not like 2 seconds!
✗
Comes with a boring LCD rather than a beautiful LED display.
✗
Table 1.1: table of broken expectations
The main problem in my opinion is that it uses a lot of power. Even if you turn it off, it’ll use some power (100 mA or so). At least my model didn’t come with a place to put in batteries so it’s external power only. The fact that this device is basically slightly on all the time (unless you unplug the cord or have a switch nearby), I’m a bit concerned for its longevity. So I don’t think I’ll use it much. :(
Besides, what I really need is a calculator that is really good at converting between bases, like kcalc. I’m not sure such a device even exists!






































{kind=link}