Summary
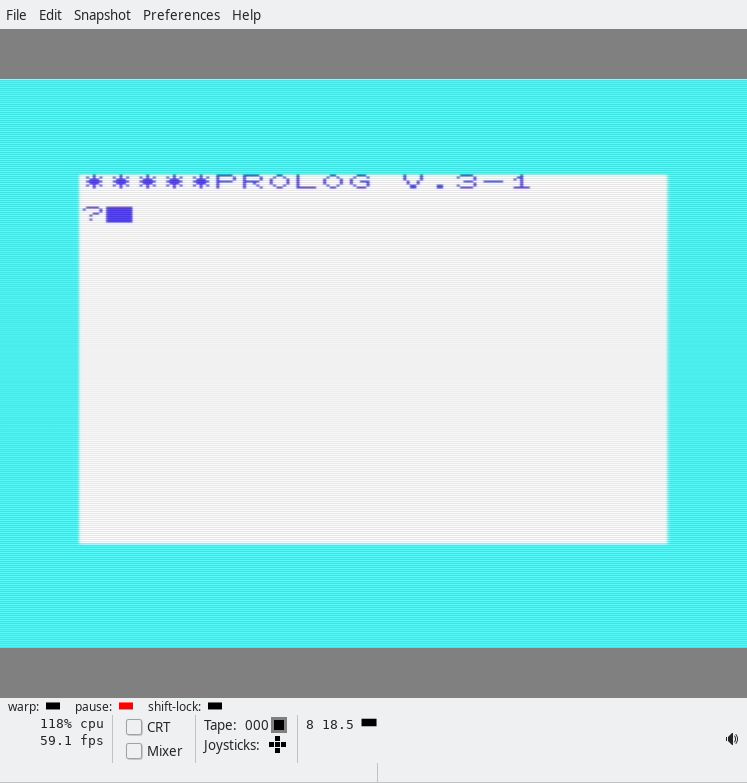
I have a Yamaha MSX1 (YS-503) with 64 32 KB of RAM and an SFG-01, which has a YM2151 on it. I do not have a floppy drive, but I have a way to easily “make cartridges” that are up to 48 KB in size. This blog post explores the source code of vgmplay-msx and ports portions of the program to work off a cartridge. Here’s how the result looks in openMSX:
Here are ROM files that work in OpenMSX, one with the SFG-01 inserted into slot 2, and the other with the SFG-01 inserted into slot 3, both playing the first ~20 seconds of track 2 on https://vgmrips.net/packs/pack/fantasy-zone-ii-dx-sega-system-16c, “10 Years After ~ Cama-Ternya [Demo]”.
vgmplay-msx deep dive
VGM files have a 128 or 256-byte header followed by the actual song data. The song data entirely consists of 1-byte commands possibly followed by a couple bytes of arguments to the command. The only commands we are interested in are “YM2151 register write” and the “wait” commands, of which there are a few. (And maybe the end of song/loop commands.) Everything else is irrelevant for our setup and what we want to do.
We only have 48 KB of ROM space, which means that it’s a bit of a tight fit for the program and the song data. The stock vgmplay.com file is about 32 KB, but it includes code (src/drivers/) for a lot of chips. We only need src/drivers/SFG.asm. There are also vast regions of 0s. We also don’t need any code to make song data fit into more than 64 KB of RAM (src/MappedReader.asm). We don’t need support for compressed .vgm files. And we don’t need any MSX-DOS-specific code, nor do we need code to handle reading from the floppy drive. Song data tends to be relatively large too: the song I used in Raspberry Pi Pico implementation of the YM3012 DAC (mono) was around 1 minute and is 68 KB in size. We’ll have to either truncate it, or find something shorter or simpler.
vgmplay-msx is written in a rather unusual assembly dialect. The assembler supports scoping, and there appears to be a bit of a “class” hierarchy. For example, MappedReader (src/MappedReader.asm) extends Reader (lib/neonlib/src/Reader.asm).
After putting the MSXDOS22.ROM into .openMSX/share/systemroms and booting from MSXDOS22.dsk, and adding the Yamaha SFG-01 extension (Hardware -> Extensions), and executing ‘make’ in the vgmplay-msx source directory, I was able to execute ‘vgmplay foo.vgm’ in MSX-DOS and hear the VGM file being played back in openMSX. After reading the code for a little bit, I opened and connected the debugger. In System -> Symbol manager, we can read the symbols generated by the assembler, vgmplay.sym, which are quite convenient.
Note: openMSX debugger fails to show the correct disassembly when there is a label in the middle of an instruction. Below, 427F 26 db #26 and 4280 79 ld a,c are actually a single instruction, which you can manually decode using something like this:
$ echo -n -e '\x26\x79' > foobar
$ z80dasm foobar
; z80dasm 1.1.5
; command line: z80dasm foobar
org 00100h
ld h,079h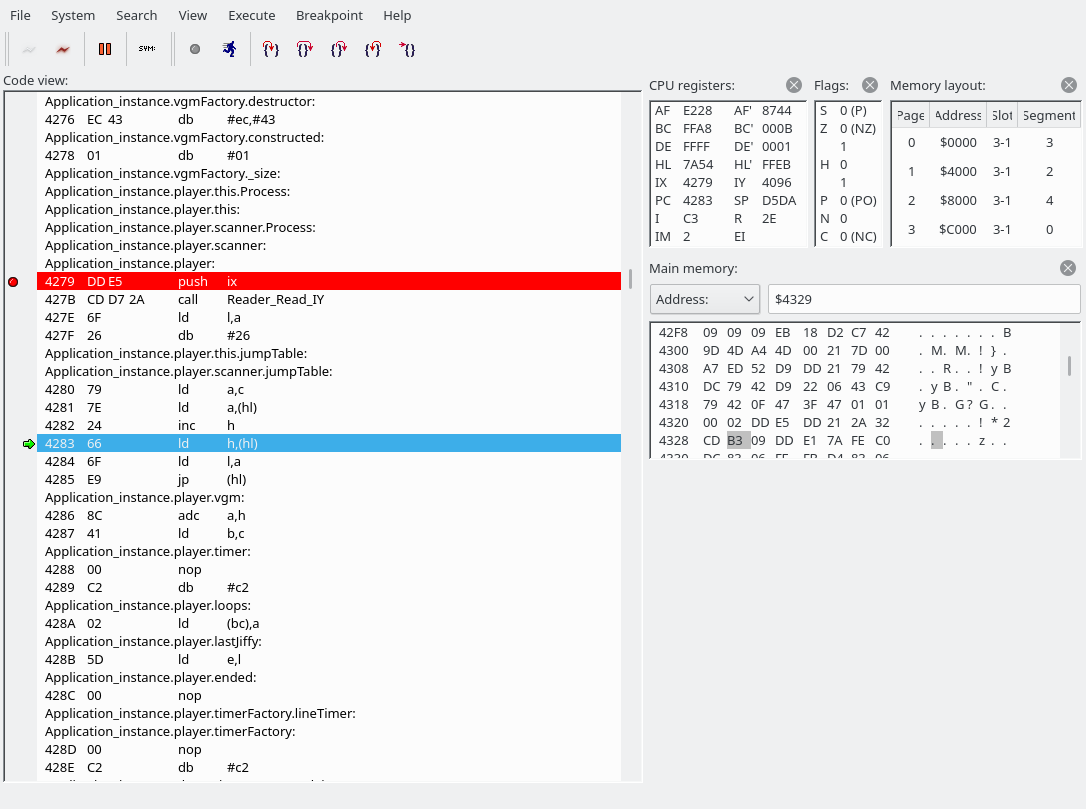
The jump table is defined in src/Player.asm, and for efficiency reasons is separated into two in Player_InitCommandsJumpTable in the same file.
; Shuffles the commands jump table so that the LSB and MSB are separated.
; This allows faster table value lookups.
Player_InitCommandsJumpTable: PROC
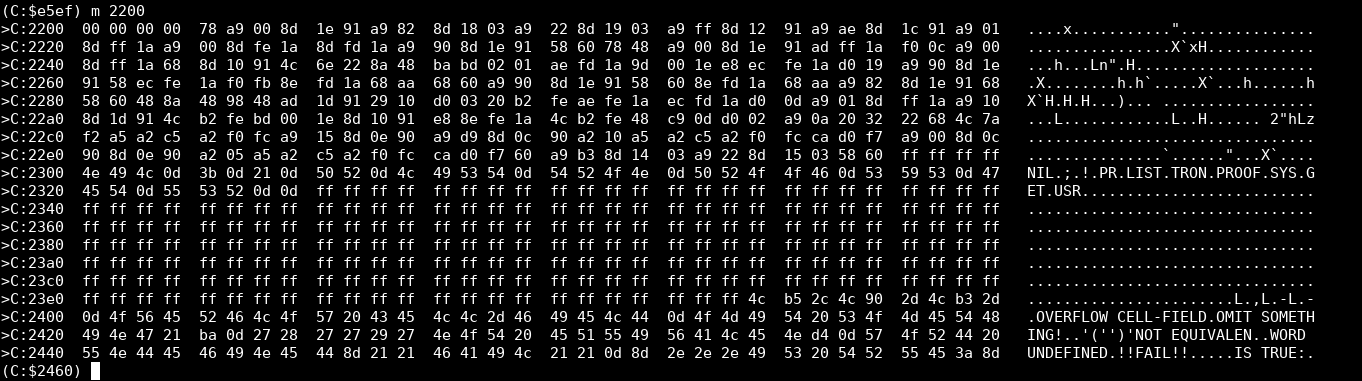
...The byte we read was a 0x54, which indicates that we are going to write to the YM2151. This is where we have jumped:
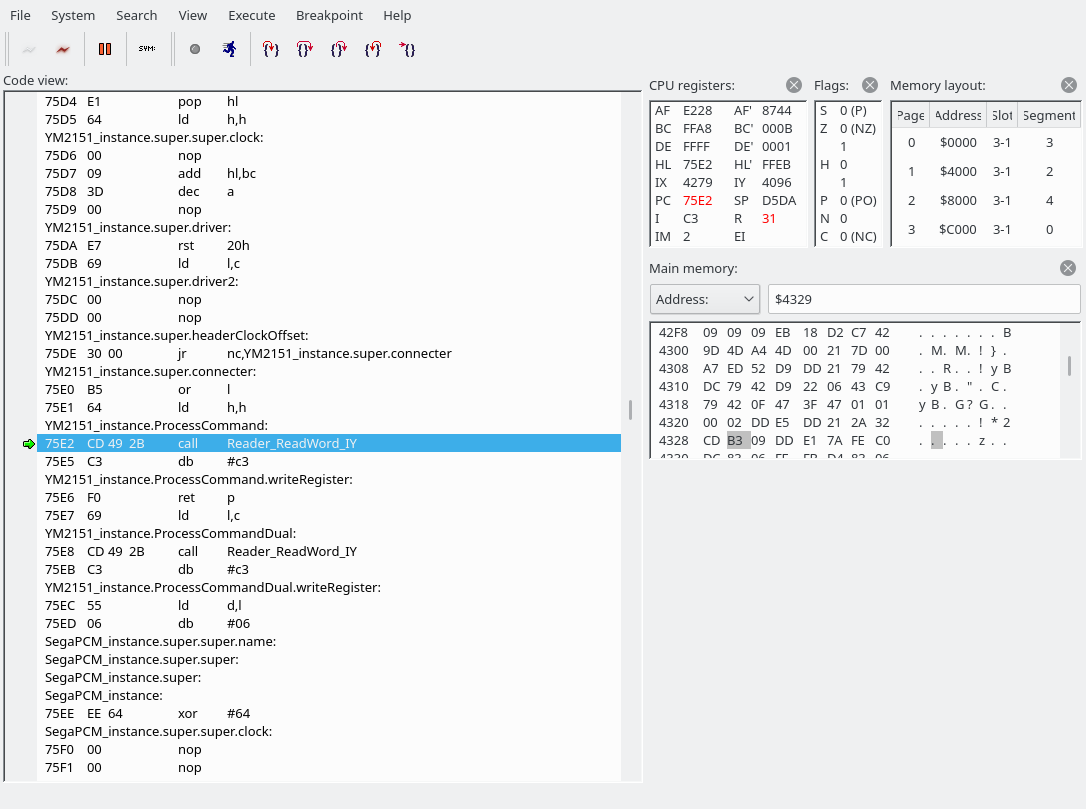
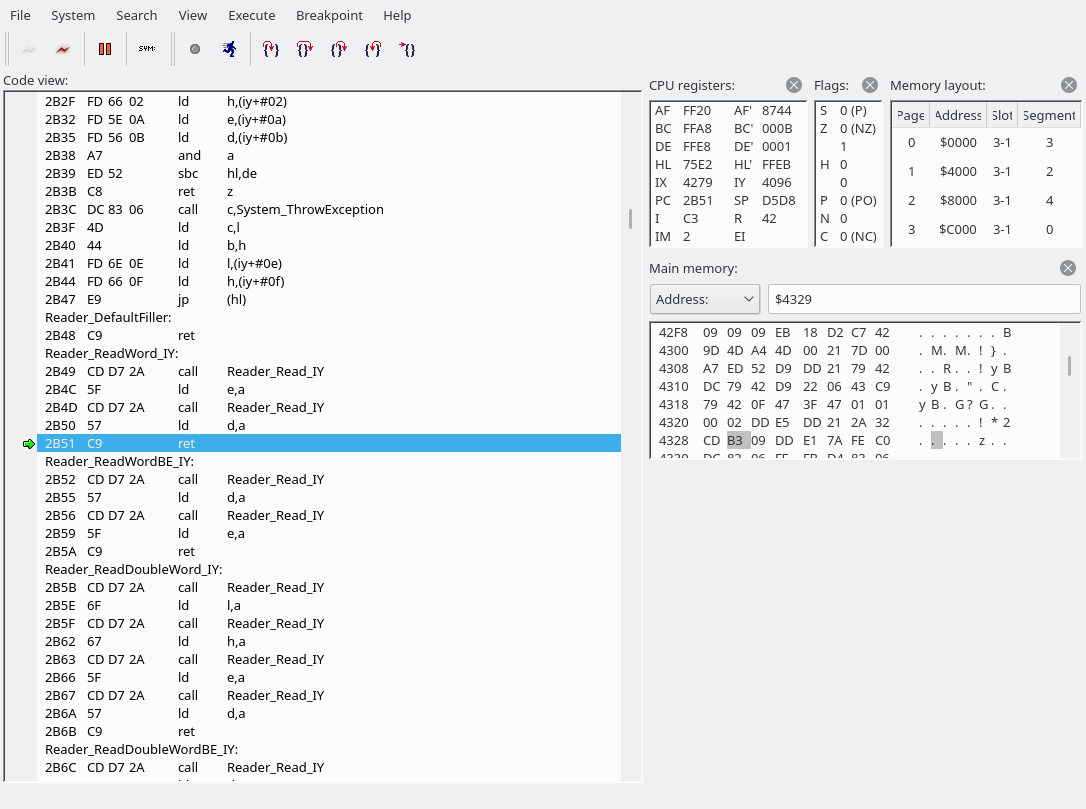
We have now jumped to 69F0. The source file is src/drivers/SFG.asm.
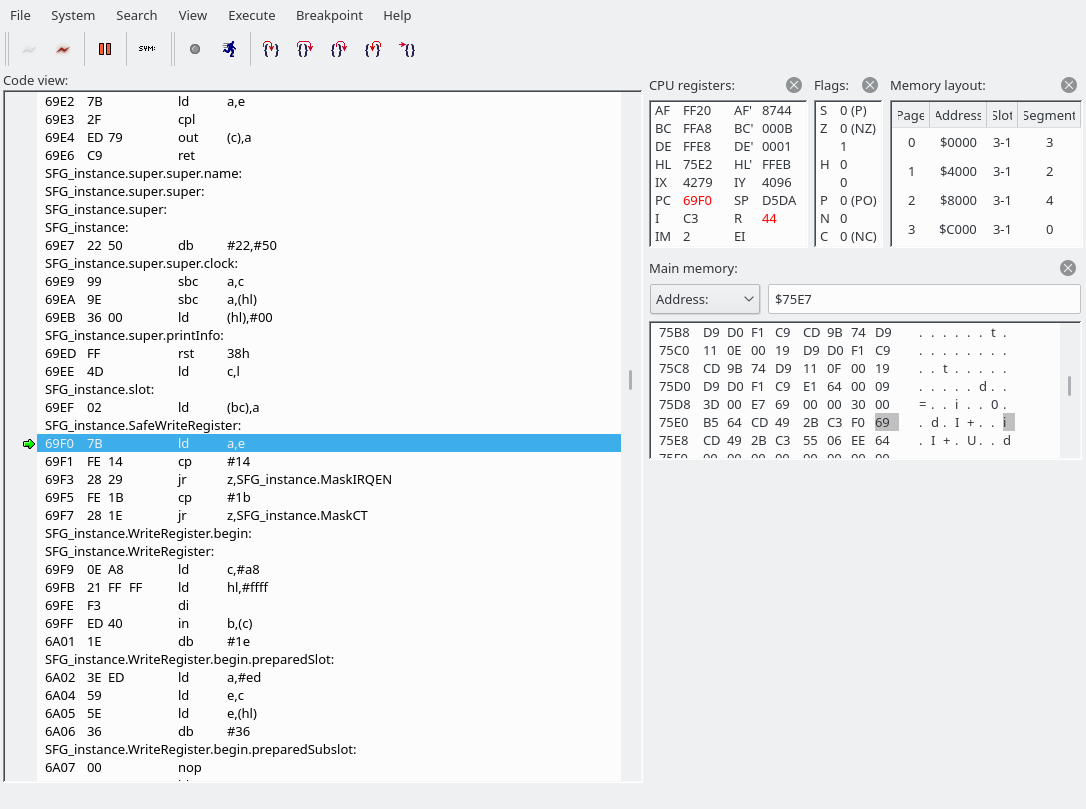
First of all, we look into the address value and may jump to MaskIRQEN or MaskCT if the address is exactly 0x14 or 0x1b, respectively. Our E is set to E8, so that doesn’t apply here, so we fall right through into SFG_instance.WriteRegister. I am going to guess that the MaskIRQEN and MaskCT sections modify some bits in the address register to perhaps turn off a feature in the YM2151 that would trigger output on the interrupt or one of the CT pins, but I don’t know for sure. Here’s a pinout of the YM2151 BTW:
Next, let’s edit the symbol file to work around the debugger’s inability to disassemble instructions that have labels in the middle… Search for ‘6a02’ and ‘6a07’ in the symbol file, remove the symbol file from the debugger, and add it back in again. Then our WriteRegister function becomes a little clearer:
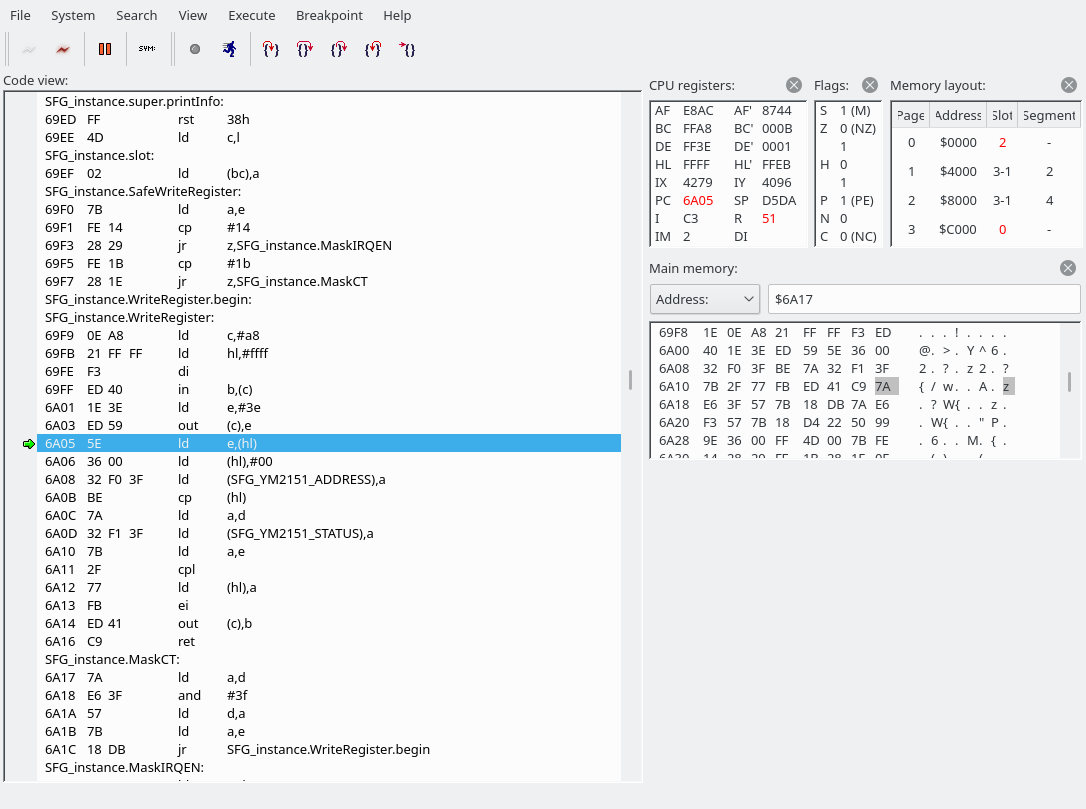
The SFG’s YM2151 registers are memory-mapped(!) at the following addresses:
SFG_YM2151_STATUS: equ 3FF1H
SFG_YM2151_ADDRESS: equ 3FF0H
SFG_YM2151_DATA: equ 3FF1H
SFG_ID_ADDRESS: equ 80H
SFG_CLOCK: equ 3579545If you know quite a bit about how the MSX works, you may know that the MSX in general doesn’t use memory-mapped I/O, and you may also know that 0000-3FFF is where the system ROM is usually located (mapped; it can be unmapped and something else can be mapped instead). In the screenshot above, you can see that there’s an “in b,(c)” instruction at 69FF, where C holds #A8. This is the I/O register that allows you to remap stuff. See this link if you want to know more about how this register works: http://map.grauw.nl/resources/msx_io_ports.php#ppi. (BTW, this page is probably authored by the same person who wrote vgmplay-msx.) So “in b,(c)” saves the contents of the #A8 into B.
In order to perform memory-mapped I/O, we have to unmap any ROM or RAM currently mapped in. And when we’re done, we obviously have to map it back in. (Oh, good that we saved the #A8 contents into B.) ROM and RAM mappings vary between MSX models, which means the OUT part of the code is probably generated dynamically somewhere in the init code. (Hence the labels in the middle of our instructions.) The next instructions (6A05 and 6A06) save the contents of the subslot register (FFFF) into E (so we can change it back later) and set the subslot register to 0. (Note that at this point our register address has already been moved into register A, while data is still in register D.)
After the OUT is done, we just write our address to SFG_YM2151_ADDRESS and our data to SFG_YM2151_STATUS (which is an alias of SFG_YM2151_DATA, the address is 100% the same). The “cp (hl)” instruction in the middle is just to wait a short moment according to the comment in the source code: “; R800 wait: ~4 bus cycles”. When we’re done, we set the slot and subslot registers back to what they were.
So that’s how we perform a register write. We also need to know how to wait a specific number of cycles. VGM files are full of wait commands, and if the amount of waiting we do is too imprecise, that will definitely be audible. The wait commands in VGM files assume an output sample rate of 44100 Hz, which is different from the actual sample rate on real hardware. The number specifies the number of samples to just leave the YM2151 alone to do its thing. In reality, the YM2151 in the SFG-01 outputs at 3579545/2/32 = 55930.390… Hz. The Z80 runs at 3579545 Hz. So we get 64 Z80 cycles per sample, but because the VGM file wait cycles assume a different sample rate, just adding NOPs would end up being rather imprecise. What’s more, some VGMs are for machines where the YM2151 is clocked at 4000000 Hz, which results in an output rate of 4000000/2/32 = 62500 Hz.
So let’s… jump back to our jump table to see what happens when a wait instruction is encountered!
dw Player_WaitNSamples ; 61H
dw Player_Wait735Samples ; 62H
dw Player_Wait882Samples ; 63H
...
dw Player_Wait1Samples ; 70H
dw Player_Wait2Samples ; 71H
dw Player_Wait3Samples ; 72H
dw Player_Wait4Samples ; 73H
dw Player_Wait5Samples ; 74H
dw Player_Wait6Samples ; 75H
dw Player_Wait7Samples ; 76H
dw Player_Wait8Samples ; 77H
dw Player_Wait9Samples ; 78H
dw Player_Wait10Samples ; 79H
dw Player_Wait11Samples ; 7AH
dw Player_Wait12Samples ; 7BH
dw Player_Wait13Samples ; 7CH
dw Player_Wait14Samples ; 7DH
dw Player_Wait15Samples ; 7EH
dw Player_Wait16Samples ; 7FH
dw Player_Skip1 ; 80H
dw Player_Wait1Samples ; 81H
dw Player_Wait2Samples ; 82H
dw Player_Wait3Samples ; 83H
dw Player_Wait4Samples ; 84H
dw Player_Wait5Samples ; 85H
dw Player_Wait6Samples ; 86H
dw Player_Wait7Samples ; 87H
dw Player_Wait8Samples ; 88H
dw Player_Wait9Samples ; 89H
dw Player_Wait10Samples ; 8AH
dw Player_Wait11Samples ; 8BH
dw Player_Wait12Samples ; 8CH
dw Player_Wait13Samples ; 8DH
dw Player_Wait14Samples ; 8EH
dw Player_Wait15Samples ; 8FHAs we can see, there are a lot of commands that perform waits. For Player_Wait1Samples, we jump to 492F:
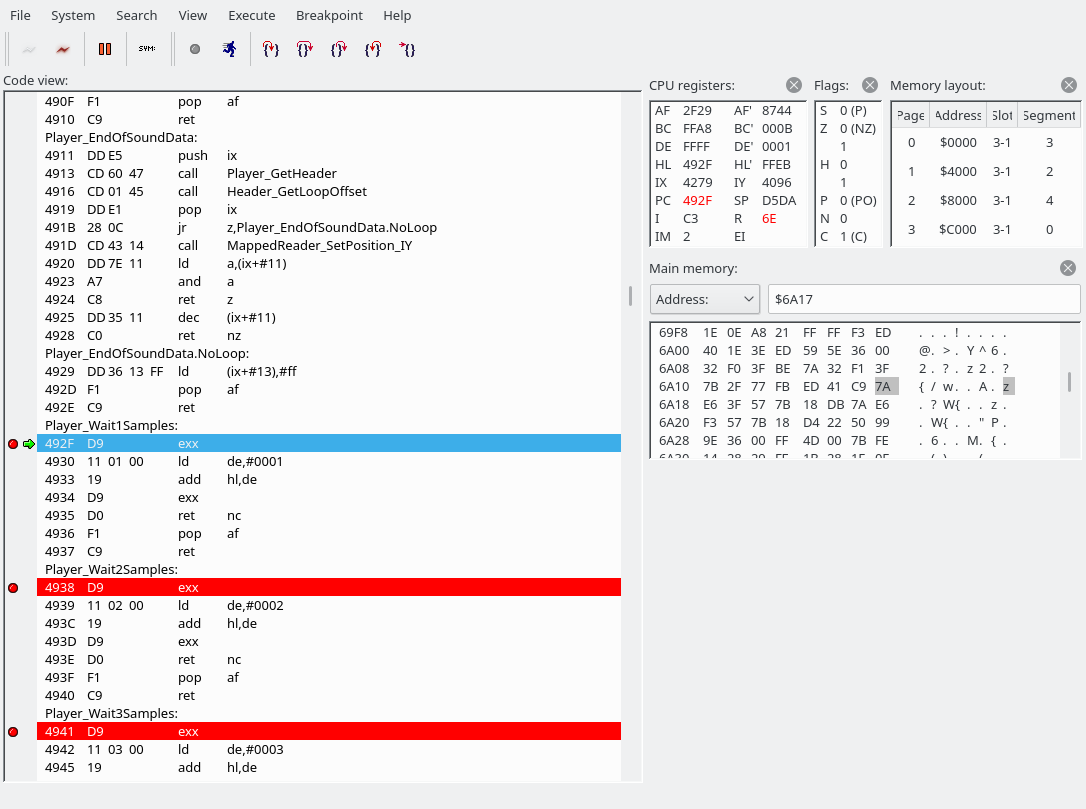
The “exx” instruction switches between the directly usable registers and the shadow registers. (“EXX exchanges BC, DE, and HL with shadow registers BC’, DE’, and HL’.”) Wow, the Z80 has so many registers. All we do here is add 1 to hl’. In a special case, we pop AF from the stack, but we have no choice but to ignore that for now. And basically, Player_Wait2Samples, Player_Wait3Samples, …, Player_Wait16Samples, Player_Wait735Samples, Player_Wait882Samples, all work the same. Player_WaitNSamples grabs its argument, and apart from that also works the same as the others. Here’s a screenshot of the stack, and it’s always the same for all Player_Wait* sections:
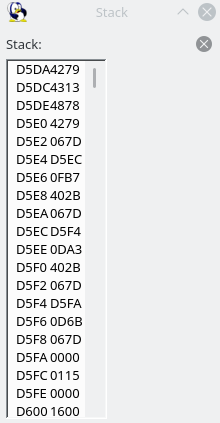
That is, we are going to jump back to 4279, and we have already seen the code at 4279. Scroll up to see it again. It’s our main loop body, where we grab a command and use the jump table to jump somewhere. (What I hadn’t noticed or mentioned above was that it begins with a “push ix” command, which seemingly puts 4279 back on the top of the stack each time.)
Well, this is a good time to think about that “ret nc pop af ret” bit again, right? If the carry flag is set, we do not return. Instead, we grab 4279 off the stack and shove it into the AF register. Then we return, and this time we should return to 4313, according to the above stack screenshot. The carry flag is set if shadow HL overflows. Currently, it’s FF71. Hmm, just a few F9 presses maybe.
Intermission, sort of
But let’s take a step back and think about what we have seen so far. Perhaps the MSX is just way too slow to play VGMs in real time with perfect timing, and it just makes sense to skip all wait commands and just sync whenever the carry flag is set?
There’s a lot of timing code, and it’s all a bit complicated because the code seems very un-assembly-like. (But as this piece of software supports many different configurations, the somewhat object-oriented patterns may maybe make sense.) Looking back at the projects homepage, it appears that on the MSX2, the timing is 300 Hz, so perhaps that means the waits are ignored as they are encountered, but everything is put in sync (up to?) 300 times a second. It looks like on the MSX1 the timing is either 50 or 60 Hz.
The timing resolution is 50 or 60 Hz on MSX1 machines with a TMS9918 VDP, 300 Hz on machines with a V9938 or V9958 VDP, 1130 Hz if a MoonSound or OPL3 is present, and 4000 Hz on MSX turboR.
https://www.grauw.nl/projects/vgmplay-msx/
While the site says that vgmplay-msx works on MSX1 machines, I’m not entirely sure what kind of hardware configuration in e.g. openMSX would allow us to do that, because vgmplay-msx needs 128 KB of RAM, and MSX-DOS2. As far as I know you also can’t give an existing MSX2 machine an MSX1-class TMS9928A VDP, because the MSX2 logo requires the V9938. (Maybe you could try to give it an MSX1 BIOS too, but I think I’m outta here.)
(End of intermission)
So what we’re going to do is: recompile without LineTimer support by commenting out in src/timers/TimerFactory.asm:
TimerFactory_Create:
; call TimerFactory_CreateTurboRTimer ; this line and
; call nc,TimerFactory_CreateOPLTimer ; this line and
; call nc,TimerFactory_CreateLineTimer ; this line.
call nc,TimerFactory_CreateVBlankTimer ; this line is left as-is
retSo anyway, we’re now running using the VBlankTimer and added breaks like this:
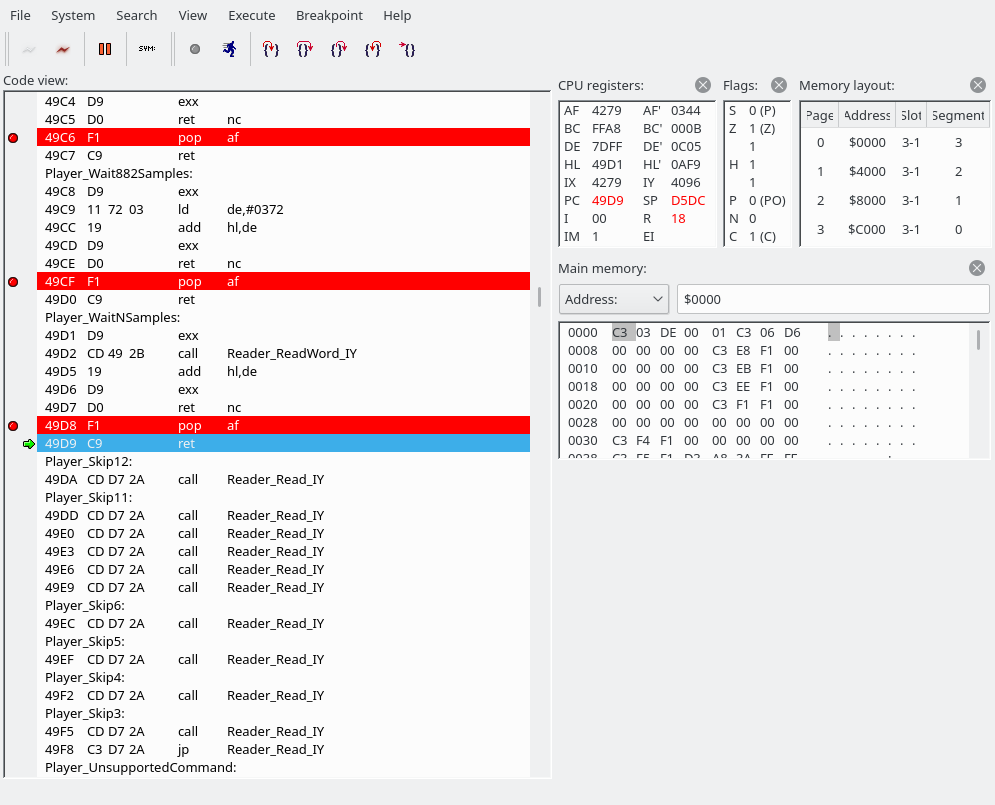
And after the ret we end up here:
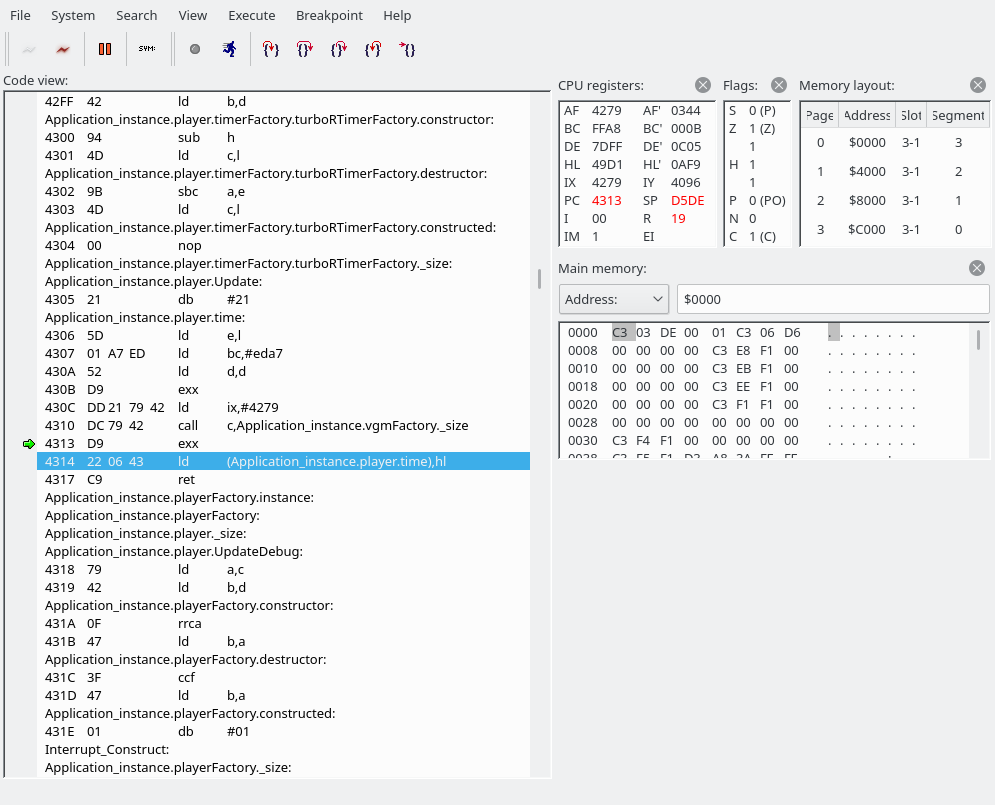
So what we do here: we save our shadow HL (which has gone past FFFF; it’s currently 0AF9) to a variable called Application_instance.player.time. And after the next ret we’re here:
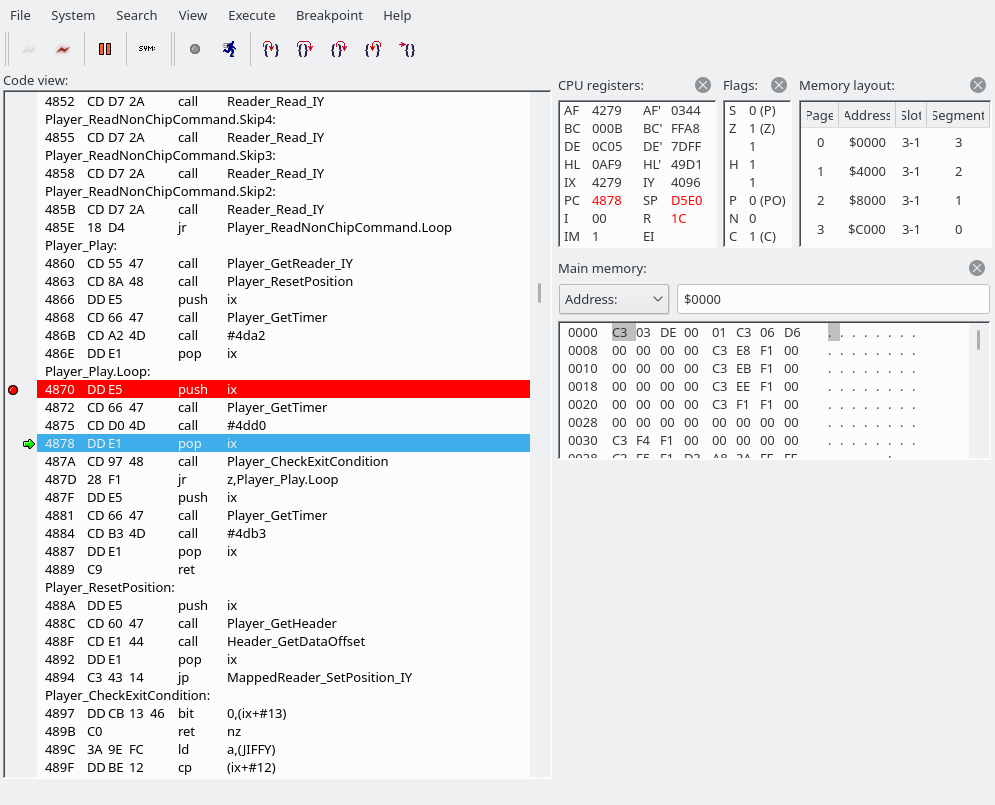
At some point, we get to “Application_instance.player.timerFactory.vBlankTimer.Update”. Wait, what language is this again?
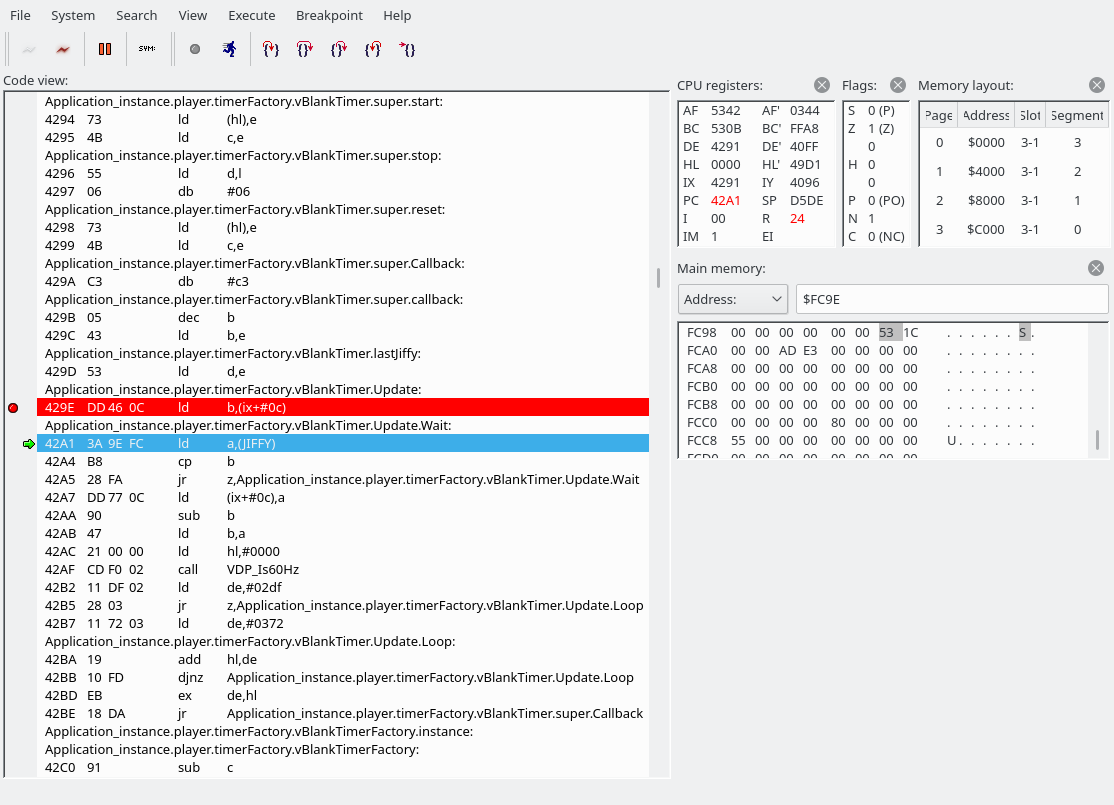
Here’s the code with more symbols:
Update: PROC
ld b,(ix + VBlankTimer.lastJiffy)
Wait:
ld a,(JIFFY)
cp b
jr z,Wait
Wait, what’s JIFFY? It’s actually a system variable:
Address: FC9Eh
Name: JIFFY
Length: 2Contains value of the software clock, each interrupt of the VDP it is increased by 1. The contents can be read or changed by the function ‘TIME’ or instruction ‘TIME’
https://www.msx.org/wiki/System_variables_and_work_area
After the tight loop is finished, we update lastJiffy with the new JIFFY. Then we set a value for our shadow HL. We either initialize DE with 0x2DF or 0x372 depending on whether we’re on 60 Hz or 50 Hz. (Update: I don’t think this routine works on the MSX1!) Then, we jump to a callback that was set way back when our Timer was first created (i.e., during program initialization), in src/Player.asm:
Player_Construct:
ld (ix + Player.vgm),e
ld (ix + Player.vgm + 1),d
call Player_SetLoops
ld hl,Player_commandsJumpTable
call Scanner_Construct
push ix
ld e,ixl
ld d,ixh
ld hl,DEBUG ? Player.UpdateDebug : Player.Update
add hl,de
call Player_GetTimerFactory
call TimerFactory_Create
call nc,System_ThrowException
ld e,ixl
ld d,ixh
pop ix
ld (ix + Player.timer),e
ld (ix + Player.timer + 1),d
jr Player_ConnectPCMWriteActually executing the code we see that we end up in Application_instance.player.Update:
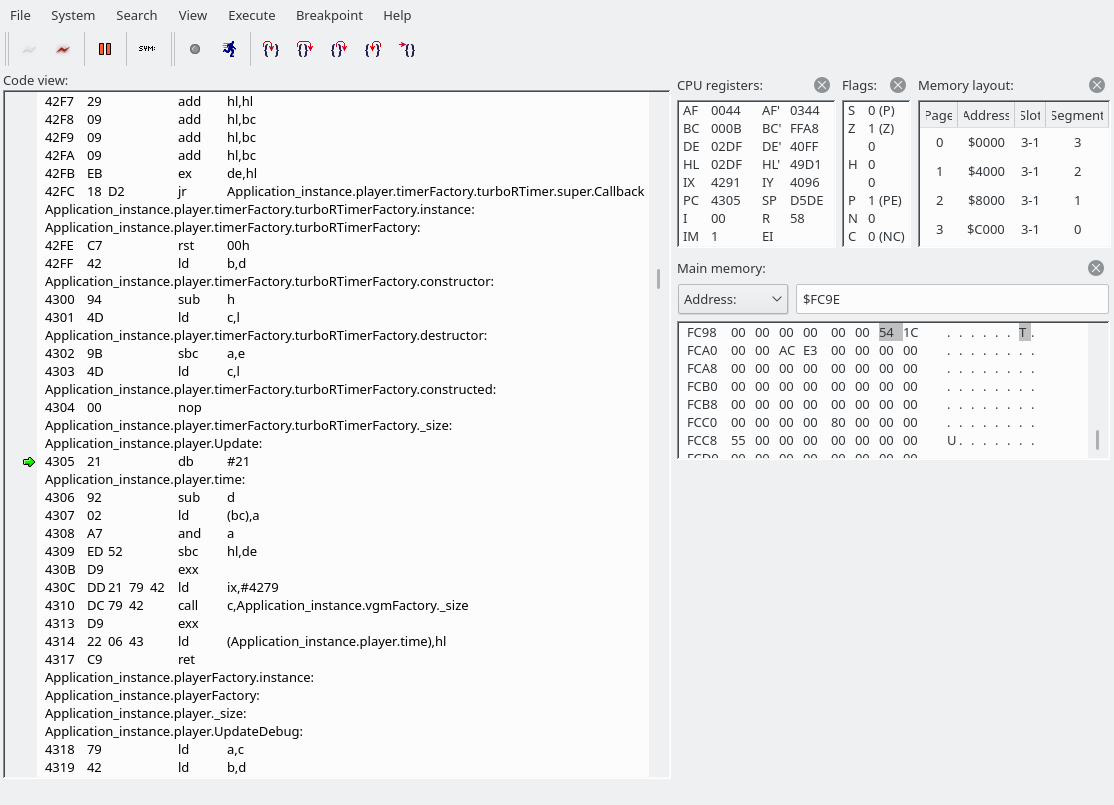
We are about to do “sbc hl,de”. The HL register has 0292, DE contains 02DF or 0372, depending on whether the system is 60 Hz or 50 Hz. Note: I don’t think the routine to figure out whether the system is 50 or 60 Hz works on MSX1s.
Address: FFE8h
Name: RG09SAV
Length: 1System saves the byte written to the register R#09 here, Used by VDP(10). (MSX2~)
https://www.msx.org/wiki/System_variables_and_work_area#VDP_Registers
Anyway, I don’t really know where the carry flag that SBC is supposed to take into account comes into play (it’s not set in the code visible in the above screenshot). But anyway, 0292 – 02DF = FFB3. And this is the value we will add numbers to again in the Wait* procedures. Or let’s use our brains just one more time:
- There are 0x02DF samples per 60 Hz VSYNC (or 0x0372 samples per 50 Hz VSYNC)
- We already “overshot” our previous target by 0x0292 samples in the previous run
- We have 0x02DF-0x0292=0x4D samples left until we should wait for VSYNC again
- Note: 0x10000-0xFFB3=0x4D
We have now seen enough to take just the parts we need.
What parts do we need?
- Jump table
- We’ll edit it to remove support for anything but the YM2151 though
- We’ll also need the remaining jump locations of course (loop, end of song, wait, etc.)
- (Also code to make jump table more efficient)
- SFG register writing code
- (If possible, also init code to figure out correct slot selection register values.)
- Timing code
- VSYNC-based timer only
- The song data will be directly on the cartridge, so
Let’s do it
For convenience/compatibility with the existing code we will be using the same assembler, Glass, though I don’t think we’ll be using any of its unique features. We won’t be using constructors or a heap, even, but we will use the stack in the same way the existing code is using it.
Cartridge contents are mapped to 4000-7FFF, or if no cartridge was detected at 4000-, then 8000-BFFF. (The MSX BIOS maps in the candidate addresses (starting with 4000-7FFF) and checks for the presence of a header at the beginning of this address space to see check if a cartridge is inserted.) Thus, programs must start like this (I added some useless code in the entry_point that makes it easier to test that this thing is working):
org 4000h ; hex number syntax may differ from assembler to assembler
db "AB" ; all cartridges have this
dw entry_point ; 16-bit absolute pointer
db 00,00,00,00,00,00 ; can be anything probably
entry_point:
nop
jp entry_pointCompilation example if saved as foo.asm:
$ z80asm -o foo.rom foo.asm
$ dd if=/dev/zero of=foo.rom bs=16384 seek=1 count=0 # actually creates a sparse file but that's fine for all intents and purposes
$ hexdump -C foo.rom
00000000 41 42 aa 0f 00 00 00 00 00 00 00 18 fd 00 00 00 |AB..............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001000
However, we only got our cartridge mapped up to 7FFF, but if we want its whole 48 KB mapped, we need to set port #A8. #A8 of course holds an 8-bit number, but you should interpret it as four 2-bit numbers. “00 00 00 00” (0x00) would mean that everything is on slot 0. “01 01 01 01” (0x55) would mean that everything is on slot 1. You can choose any combination your hardware likes.
All MSXs have Main-ROM in primary slot 0 or in secondary slot 0-0 (see variable EXPTBL below for more details). Cartridge slot that is on top of computer is typically slot 1. If there is another expansion port then this is often slot 2. Although the internal RAM should preferably be in slot 3, this is often not the case for MSX1s.
https://www.msx.org/wiki/Slots
The cartridge slot is “typically slot 1”. I don’t know if there are any computers that have a different number, but it’s easy to determine the number in software: we’re running off 4000-7FFF, so the slot is already set correctly here. We just need to set the page we want to the same number.
Now, if we want to set 4000-FFFF to the cartridge, we won’t have any RAM. And therefore, no stack. vgmplay uses the stack (as seen earlier). vgmplay also uses the BIOS (mapped into 0000-3FFF) because we need the VSYNC interrupt handler, and this interrupt handler writes to a system variable called JIFFY, which is located at FC9E, as mentioned above. We could decide to leave the last slot for RAM, limiting the amount of song data we can play to less than 32 KB. But the amount of RAM we need isn’t exactly very much. In addition, as we have seen, some parts of the vgmplay code are self-modifying.
So what we’ll do instead is: copy the entire cartridge to RAM. Then we’ll be able to use self-modifying code, and we’ll be able to have a stack too. Sounds easy? Well, let’s say we have our copying routine at ROM address 4100. What happens if we try to copy the ROM at 4000-7FFF to RAM? We’ll execute instructions at 4100, and these instructions say to switch 4000-7FFF to RAM, which we do, and then what? We’ll have pulled the carpet from under our feet! One way to avoid this problem is by having two (or more) copies of the copying code.
So first we could copy 8000-BFFF to RAM, which doesn’t require any precautions. For the page starting at C000, we probably shouldn’t copy past F000, which is where the stack and some system variables appear to be located. (Not that the stack holds anything.) But otherwise no precautions are required. Then, we jump to (e.g.) 8100, where we have another copy of our copy routine, and copy 4000-7FFF. (We’ll choose a different location for the second copy because we’d expect the song data to start before 8100. Perhaps F200 or so.) If we copy byte-by-byte (or word-by-word), switching between ROM and RAM every time, we can use a single register to hold the read value and won’t need any buffer memory (which would complicate things a bit). (It finishes in less than 1 second per 16 KB, so no issues here as this is init code.)
One more annoyance is that since we do not have a stack, it doesn’t make a lot of sense to ‘call’ the copy code. Jumping to the code isn’t exactly fun either because we’d have to know where to jump back, and the register dance becomes a little annoying. So we’ll just copy and paste the code. Here’s the first-draft code to copy 4000-F000 from ROM to RAM. This code assumes that the BIOS ROM is in slot 0, the cartridge ROM in slot 1, all RAM in slot 3, and that there are no subslots. This assumption doesn’t hold on many systems. This code can be compiled using z80asm using the following command line:
z80asm -o foo.rom foo.asmorg 4000h
db "AB"
dw entry_point
db 00,00,00,00,00,00
entry_point:
ld a,01010100b ; set rom - cart - cart - cart
out (0a8h),a
; copy 8000-bfff
copy_8000_bfff:
ld hl,08000h ; start at 8000
copy_8000_bfff_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
or 000110000b ; set bits 5-4 to 11 (RAM) (actual value depends on machine)
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 0c0h
jp z,copy_c000_f000 ; done with this copy
jp copy_8000_bfff_loop
copy_c000_f000:
ld hl,0c000h ; start at c000
copy_c000_f000_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
or 011000000b ; set bits 5-4 to 11 (RAM) (actual value depends on machine)
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 0f0h
jp z,copy_4000_7fff ; done with this copy
jp copy_c000_f000_loop
done_copying:
ld a,011111100b ; switch to 4000-ffff to RAM
out (0a8h),a
nop:
nop
jr nop ; infinite loop
seek 0b000h ; b000+4000 = f000
org 0f000h
copy_4000_7fff:
ld hl,04000h ; start at c000
copy_4000_7fff_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
or 000001100b ; set bits 5-4 to 11 (RAM) (actual value depends on machine)
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 080h
jp z,done_copying ; done with this copy
jp copy_4000_7fff_loopThis is pretty almost all that we need to code ourselves, everything else will be copy and pasted from vgmplay-msx! Note: the above doesn’t actually assemble in Glass because Glass requires that reserved words like “org” are indented, and “seek” isn’t supported. The final code will therefore look a bit different.
Putting all the necessary bits together (and throwing out everything else)
I got it to work on an emulated version of my Hitachi H2. (My apologies to the original author of vgmplay. I completely butchered their code.) And right when I start looking at the slot map of the computer I actually intended to run this one (Yamaha YIS-503), I noticed that the silly machine only has 32 KB of RAM, har har har. And (this was expected though not quite to this extent) the slot map is different, so the #a8 port settings will have to adjusted. With 64 KB we could load the whole 48 KB ROM into RAM, but with 32 KB, arranged the way it is, we’ll boot from 8000 and ignore 4000-7FFF. (We could rewrite the self-modifying code to refer to variables in RAM space instead, but unfortunately I’m running out of steam on this project. I’d planned two days and it’s about three days already! :p)
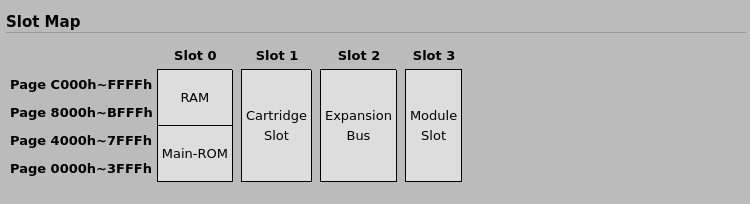
It ended up working on this machine too, of course. Except, I think that openMSX might be putting the SFG-01 into a different slot (2), rather than slot 3 as sort of indicated in the above screenshot. Due to the limited amount of RAM, our music gets truncated even earlier than before. Feel free @ anyone wanting to fix this. TBH, I just want to be able to hear if the music sounds okay or not. (Edit 2023/04/08: I checked on a real YIS-503 and the SFG-01 was indeed in slot 3, so the above screenshot is correct.)
Code is at https://github.com/qiqitori/vgmplay-msx-cartridge.