I bought another Hitachi H2 MSX last year, mostly because I wanted the manual, which I’ve scanned. Unfortunately for my free time but fortunately for my, um, education in retro computing, this computer had issues with its video RAM. Often, the computer would boot up with a garbled screen. Resetting after a couple minutes would usually fix the issue. The video RAM is made by Toshiba, and is called TMM416P-2 (also marked 4116-2). If you have this memory, I’d recommend you look out for issues, because all eight ICs had the same issue, namely: crazy-ass noise on the -5V line. (How much noise is “crazy-ass” noise? In this case, it’s +-3V.) The noise sort of comes and goes, or at least gets stronger and weaker, randomly, which made it too hard for me to find a combination of capacitors to tame it. (Though it’s more likely to be present after turning the computer on after a long while.) I ended up socketing them all, replacing one that unfortunately died during the very professional desoldering process, and added 103 ceramic capacitors to (almost) every one, between the -5 and GND pins, which seems to have a slight positive effect. (The bottom part of the case has a hook that requires some clearance and prevents two of the chips from getting their capacitor.) I also replaced the zener diode with a 7905, which fit perfectly after bending the legs a little bit.
Details
The -5V rail for the 4116 VRAM chips is generated using a zener diode. Replacing this, or the capacitor on the rail, unfortunately didn’t have any effect. Hmm, odd!
Next, I decided to desolder the -5V pin on the first 4116 IC, and drive it using my own known good -5V supply (using a standard 7905 regulator). Result: noise both on the first chip and all the others. Hmm, odd!
Next, I did this for the rest of the 4116 ICs, and was able to see that each and every one generates noise.
Next, I decided to desolder all of them and individually test them on my 4116 tester. (They still produced the noise while in the tester.) I decided to desolder all of them because the H2 seemed to support 4416 ICs for the video RAM, and I happened to have some of those that were waiting to be put to use. I.e., there are holes of the right size, right next to the VDP, and the silkscreen on those holes says “TMS4416”. ;)
Well, today’s lesson is, do not necessarily trust the silkscreen. The TMS9928A doesn’t even support 4416 VRAM! The holes where the data pins go didn’t even have any traces on them. The TMS9928A can be made to support 4416 RAM using a custom circuit, though. Maybe I should have implemented this circuit. I even bought the two required parts! But then decided against it for complexity management reasons.
Unfortunately, expecting to be able to use the 4416 slots, I had desoldered the original VRAM ICs in a rather brutish manner, losing vias and traces in the process, which meant that I needed to add a bunch of bodge wires to get them to work again. At least the bodge wires aren’t too complex to figure out, if at some point one of them decides to become loose again. I ended up keeping the original, noisy, RAM chips. But since they’re now all socketed, it shouldn’t be too hard to replace them at some point, if necessary.
Pictures
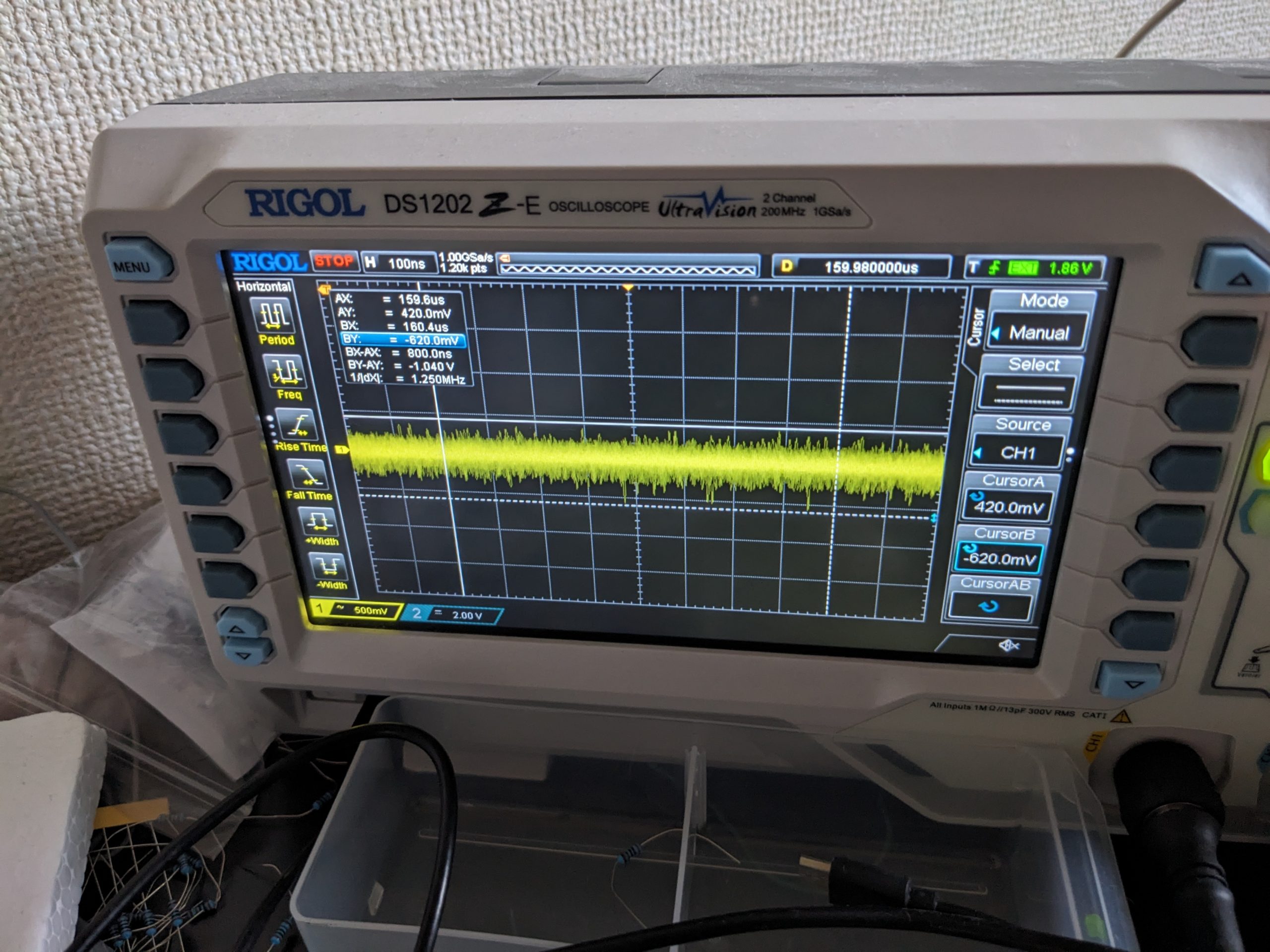
Garbled screenHitachi MB-H2 logic board from above. The misleading silkscreen is in the top left, above the TMS9928ANL VDP.Example with a lot of noiseAnd an example with a lot less. (This picture is from six months ago. It’s entirely possible that I had extra capacitors for this shot.)TMM416P-2 noise closeup. Intensity varies. Here it’s about 3V peak-to-peak.TMM416P-2 noise closeup, one more example.
After
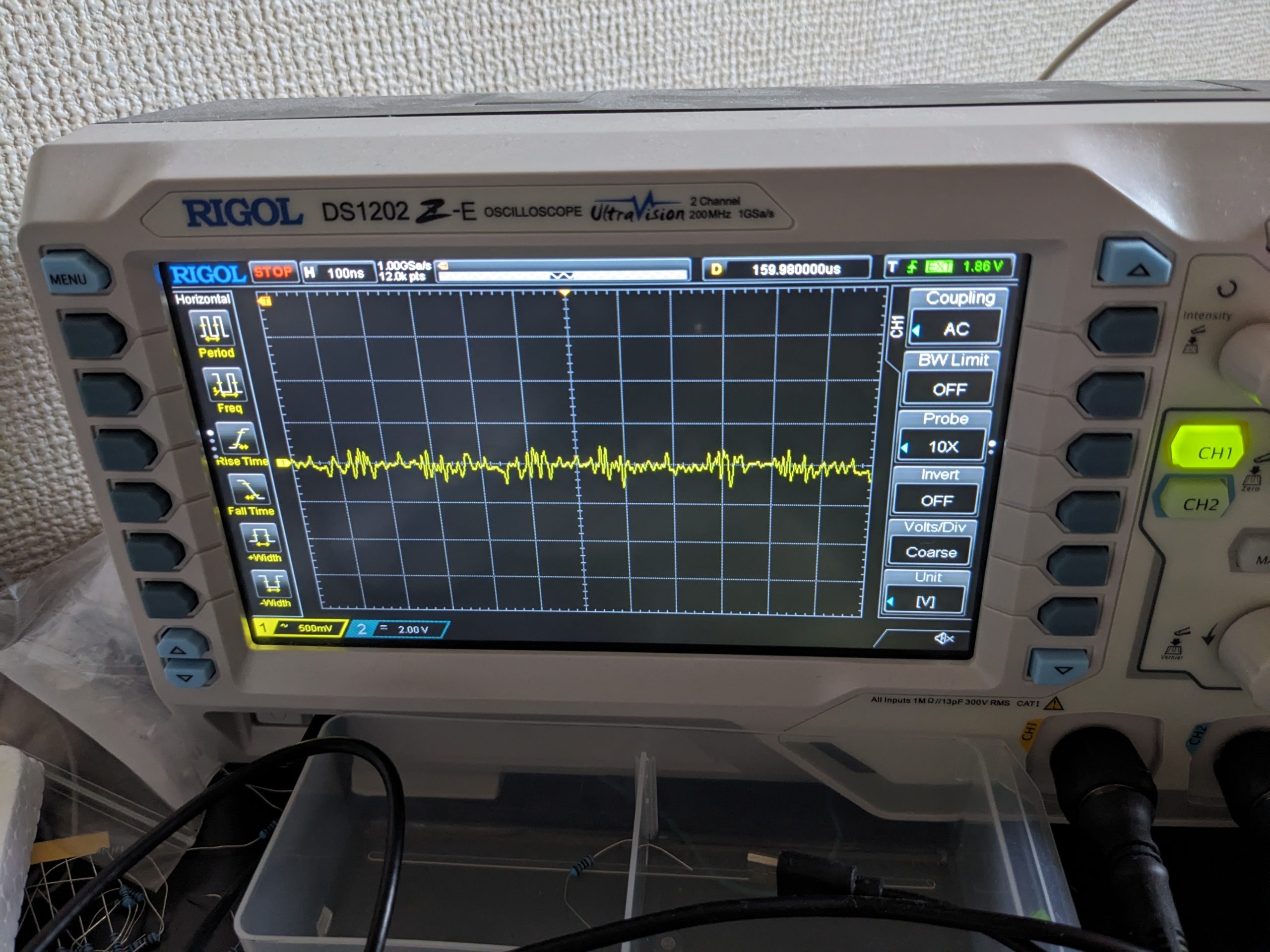
Noise after “completion” of this repair (note: using AC coupling here). Note that noise intensity has always been a bit random, so I this can’t be taken as proof that adding 103 capacitors to each chip is going to help in any case, and I am not too interested in performing rigorous testing. Anecdotally, I haven’t seen any garbled screens yet after the “repair”!Noise closeup (note: using AC coupling here)Check out this 7905’s limbo dance moves
Before looking at the picture of the bodge wires below, please keep in mind that it is rude to stare.
Hi, just a quick thing that may be useful if you’re trying to save memory while using libwebp to encode a monochrome image.
We assume that you already have the monochrome data, and you just want to encode it. Your data size is width*height*1, and is 100% equivalent to the Y channel in YUV.
Allocating a bunch of memory (width*height/2) for the UV part would be silly, but looks like it’s required, right?
Well, we can actually get away with just width/2, by doing this:
picture.y = y_data; // straightforward
picture.y_stride = width; // straightforward
picture.u = dummy_uv_data; // array of length width/2 full of 0x80 bytes
picture.v = dummy_uv_data; // it's the same array!
picture.uv_stride = 0; // stride is 0! this means we'll always read UV from the same location for every single pixel row
BTW, you can generate your y_data with the following ImageMagick command:
convert test.jpg y:test.y
Below is the full code demonstrating the use of this trick. Note that the code is about 90% generated by ChatGPT, and I haven’t cleaned it up beyond the minimum necessary to get it to work. Don’t forget to adjust the width and height variables to match your input image.
Ah yes, printf debugging. If you’re like me and occasionally need to place a dozen “got here”s at once, you may find this, or something like this helpful.
You need some kind of facility to create global shortcuts. If you, like many sensible people in the world, are a KDE user, you’ll find such a facility right in the settings:
Define two shortcuts, perhaps name them “Next” and “Redefine”. Perhaps Meta+Ctrl+Alt+Shift isn’t very ergonomic, but it’s probably unique at least.
Next, we’ll add actions. “Next” should type something like ‘printf(“Got here23”);’, and “redefine” allows you to change the ‘printf(“Got here’ prefix and the ‘”);’ suffix.
Here are two example shell scripts to accomplish this. Dependencies: xclip, xdotool. (Note: these scripts probably won’t work on Wayland, but I’d assume there are Wayland-compatible replacements for these two programs.)
#!/bin/bash
cd $(dirname -- "${BASH_SOURCE[0]}")
touch prefix_or_suffix
prefix_or_suffix=$(cat prefix_or_suffix)
if [ "$prefix_or_suffix" == 1 ]; then
xclip -o -selection primary > suffix
prefix_or_suffix=0
else # 0 or blank or junk
xclip -o -selection primary > prefix
prefix_or_suffix=1
fi
echo -n $prefix_or_suffix > prefix_or_suffix
echo -n 1 > next_i
If your system is kind of slow and xdotool’s output gets chopped up somehow, maybe try xdotool key –delay 50. You could also do echo $string_to_type | xclip, and then xdotool to send Ctrl-V in order to paste. That might be a little faster for long strings.
Here’s a short video clip that shows how this works:
By the way, this is the 100th post on this blog. :O
Hi! My sabbatical ended and I’ve been working again since two months ago. Boo. However there’s this thing I just wanted to get off my chest, so I spent a few hours that I did not really have and wrote some code and this blog post about it!
Last year, I made a 4164/4116 DRAM tester for the Raspberry Pi Pico, which works just as you would expect, you program the Pico, place it on a breadboard, add some wires and something to drop the 5V to 3.3V for the Q output, place the 4164 or 4116 chip you’d like to test on the breadboard, connect a USB cable from the Pico to a computer, and look at the terminal output (or just the on-board LED). This is useful if you have already extracted a 4164 chip that you have determined to be bad. (I have written previously how you could determine whether a 4164 chip is bad, here and here.)
We “allocate” 64 KB of RAM on the Pico. We need to read in two 8-bit addresses, and combine them to a 16-bit address. If a write is being attempted, we write the same bit value into the appropriate address of Pico’s RAM. If a read is being attempted, we check if the DRAM’s output is the same as what we have in the Pico’s RAM. (We could also use 64 Kb of RAM on the Pico at a minimum, but as we’ll see in the next section we do not really have a lot of time for such shenanigans.)
Note: to use this software, you need to at least mostly know what you’re doing.
Example usageTest clip close-upWiring closeup
One note on hooking up the Pico directly to 5V components, as seen in the above pictures
Not guaranteed to not fry your Pico (note the double negation), do this at your own risk. Your Pico will possibly also draw more current than a normal TTL chip when driven above 3.6V or so, which could easily damage your precious hardware! (The current on the address pins will likely be supplied by a pair of 74LS157 chips, on the Q pins by the RAM chip, and the current on the RAM’s data in pin by the CPU or any other. \RAS and \CAS probably by custom logic chips.) Use a 74HCT245 between the Pico and the device you’d like to test.
Caveat 1
The Pico is very fast when compared to an 8-bit computer from the 1980s, but 4164 transition times are extremely fast too. If you look at a timing diagram for the 4164 (which you will find in any 4164 datasheet), you will notice that all transition times listed are on the order of <ten, tens, or low hundreds of nanoseconds. Most 4164 chips have a -20, -15, -12, or -10 suffix in their part number. This indicates the minimum allowable number of nanoseconds × 10 for the sum of all transitions. (If the DRAM is driven faster, it probably won’t work correctly. However, if it’s driven slower, most things will generally work out, though if your system e.g. reads the DRAM’s output too slowly it might be too late and not work out.)
The stock Pico runs at 125 MHz, which means that one CPU cycle is 8 ns. From hearsay, you can probably overclock any Pico to 200 MHz (clock cycles are 5 ns), and many people report that their Pico runs fine even at 400 MHz (clock cycles are 2.5 ns). For -15 DRAMs, you have 150/8 = 18.75 CPU cycles per transition if the DRAM is driven at its max speed. (Note: it isn’t on MSX machines, at least.) 18 CPU cycles isn’t a lot. Remember, we need to convert two 8-bit addresses to a 16-bit address, and then check if the newly read value matches our previously recorded value. Is that doable in 18 CPU cycles? I don’t think so, but I’m not an ARM assembly expert.
So, did I get it to work? Well… sort of but not quite.
Caveat 2
Note that there are many failure modes for DRAM chips. For example, if the chip gets super-hot within a few seconds, it’s probably shorted. I’d expect there to be a very low resistance between ground and another pin. Before hooking up the “live” tester I’m going to explain on this page, check for that kind of stuff. I would not recommend using the live tester on a chip that gets super-hot within seconds. You could risk melting your connectors, and if the short is not between VCC and GND, potentially also risk your Pico due to excessive current on a pin driven by the Pico.
Caveat 3
Untested with 4116 chips, only tested with my MSX’s main RAM.
Current status
The live tester successfully verifies that a TMS4164-15 DRAM chip under test in my stand-alone 4164 RAM tester is outputting the correct values. (There is no reason why it shouldn’t work with a 4116 chip. The tester certainly does! You just need to re-wire slightly. Also, 5V on the Pico, yeah, it doesn’t seem to “explode immediately.” But -5V or 12V? You’d better leave those pins unconnected!)
On a real system (my trusty Hitachi MB-H2 MSX) with TMS4164-15NL DRAM chips, the live tester manages just fine from power up, up until the first ~11000 comparisons (which is a split second), but at some point reads a 0 when it should have been a 1, and prints an error. Printing errors takes a long time at 115200 bps, so we go completely off the rails once we’ve encountered the first error. (That’s slightly configurable though, see “Lnobs” section for details.)
However, in the live tester’s “DEBUG” mode, it just collects a lot of samples into memory, and prints them out when the sample memory is full. Using a simple script (the Perl script included in the repo), I can then verify that all the samples check out. Note that the DEBUG code also prints out who many times it had to wait until it got data from the PIO. The answer is 0 times every time, which means that we’re too slow or almost too slow. (Sometimes there is a handful of mismatches, I’ll look into those at some point. Could be that we were just too slow, or the 5V is messing with the system ;D)
There’s a lot that could be improved, hence the “WIP” attribute in title. The first obvious improvement would be to try a little harder in the non-debug mode. The Pico has two CPU cores, and we’re only using one. We could attain more throughput by running according to the following scheme:
Core 1: Wait for sample 1 Tell core 2 to wait for sample 2 Process sample 1 Wait for sample 3 Tell core 2 to wait for sample 4 Process sample 3 …
Core 2: Wait for instructions from CPU 1 Wait for sample 2 Process sample 2 Wait for instructions from CPU 1 Wait for sample 4 Process sample 2 …
Another potential optimization would be to write the processing code in ARM assembly. (My experience with ARM assembly is mostly read-only, so not sure how much better I can get without spending way too much effort.)
Also I haven’t tried overclocking yet. Probably should!
Some more technical details
We use two PIO state machines. One waits for RAS high→low (“RAS SM”, and the other one waits for CAS high→low (“CAS SM”, which comes after the RAS transition.
Not all RAS transitions are followed by CAS transitions. For example, refresh is mostly RAS-only. In addition, though perhaps not used on the MSX(?), RAS transitions may be followed by multiple CAS transitions.
In the C code, we wait for events on the CAS SM, and then read from both the RAS SM’s FIFO and the CAS SM’s FIFO. In the PIO code, the CAS SM tells the RAS SM whether to push its address or not. (We could alternatively (maybe) always push and have the CPU make sure the FIFO never gets full, but my experiments in that regard didn’t go that well.)
There are a lot of defines that change the way the system works.
Knobs
Setting PRINT_ERROR_THRESHOLD to something above 0 only starts printing errors after encountering that many errors.
CORRECT_ERRORS causes the Pico’s memory to be updated when we encounter a mismatch
VERBOSE_STATUS_LEDS causes the Pico to perform GPIO writes at GPIO16+ (or so, I recommend you check the source to find the exact GPIO pin number) to indicate whether we’re reading or writing. This isn’t very beneficial performance-wise.
SWAP_RAS_AND_CAS_ADDRESSES: my Hitachi MB-H2 MSX applies the CPU’s A0-A7 to the RAM pins at RAS time, and A8-A15 at CAS time. When thinking “rows” and “columns”, most people would probably assume that “rows” use the more significant bits, but that is not necessarily the case, and it doesn’t matter. When operating in DEBUG mode, you’ll see accesses that are mostly linear if this define is set correctly. Otherwise each access will be 256 apart.
I haven’t seen any DRAM chip failures (except on YouTube) where only some addresses were broken and the chip appeared to work otherwise. (SRAM chips are different story. I’m sort of planning on doing an SRAM tester too, but probably not too soon.) Most DRAM chips I’ve seen are an all-or-nothing affair. For all-or-nothing affairs, this chip tester is very likely to find the problem immediately, especially if you compare all 8 chips and only one is weird. For hypothetical chips with just a single address problem (or perhaps, a single broken row), either it’ll be difficult with the code not 100% working right now, or it might take several attempts and statistics.
(I do not recommend watching this demo on a smartphone. It’s quite flashy and exacerbated my headache. Also, the WebMSX code will ask you to go fullscreen, but I don’t think you can start the demo without going fullscreen and then back again.)
In part 1, we constructed a 48 KB ROM to play a tune called “Popsa 2”. We didn’t apply any real compression algorithms but implemented a set of scripts to find repeated sections in a binary file and added an instruction to the .psg file format to “call” repeated sections. Using real compression algorithms we could achieve much better compression, and each tune would just occupy a couple KBs. Using our method, we _just_ manage to fit the tune into a single cartridge. Popsa 2 fit into 48 KB, and the tune we’re going to do today is going to require a 64 KB ROM. If the previous track didn’t quite do it for you, I think it might be worth giving this one a chance. It’s a very complex piece of wonder-inducing music in my opinion. (Press the power button and in the menu that pops up, choose “Power” to boot the ROM.)
64 KB ROMs still require a header at 0x4000 or 0x8000. This means that we need to add a header and some entrypoint code to set up the slots right in the middle of our data. That’s inconvenient, but I didn’t feel like changing the structure of the program, so I just added one check each at the beginning and end of the main loop to see if the HL register has gone above a certain value. If yes: before the main loop, it adds an offset; after the main loop, it subtracts the same offset again. This way, we don’t have to do anything too complex when jumping to a previous section of the track.
In part 1, I mentioned a problem in WebMSX that prevented the 48 KB ROM from working. 64 KB ROMs are not affected by this problem. The WebMSX player at the top of this article page plays the ROM linked to above. The ROM also works on real hardware (the Hitachi MB-H2 MSX1 I repaired a while ago).
Aside: disabling WebMSX’ auto-scroll
In the unlikely event that you have read this blog’s front page sometime in the last few months, you might have noticed that it scrolled automatically to this WebMSX player, even though this post is now very much not the newest post on this blog! I only noticed this a short while ago and decided to fix it, because it’s quite annoying. The below code snippets are taken from the WebMSX commit with the tag “v6.0.4”. Older or newer versions may look different.
All you need to do is remove the “this.focus()” line in the powerOn function in CanvasDisplay.js:
this.powerOn = function() {
this.setDefaults();
updateLogo();
document.documentElement.classList.add("wmsx-started");
setPageVisibilityHandling();
this.focus(); // <-- this is the line you need to remove or comment out
if (WMSXFullScreenSetup.shouldStartInFullScreen()) {
setFullscreenState(true);
if (FULLSCREEN_MODE !== 2 & isMobileDevice) setEnterFullscreenByAPIOnFirstTouch(); // Not if mode = 2 (Windowed)
}
};
If you prefer to just edit the minified version, search for the call to setPageVisibilityHandling() and then edit out the “this.focus(),” bit.
This article is somewhat technical. If you just want to listen to a chip tune on WebMSX, maybe go for part 2 instead.
In previous articles I explored the YM2151 and the VGM file format. In this article, we’ll go back a generation and listen to some tunes written for the DSG (doorbell sound generator) PSG (programmable sound generator, i.e., the General Instruments AY-3-8910, or compatibly, Yamaha’s YM2149). PSG files (and particularly ASC files) are mainly used for ZX Spectrum chip tunes (I think), but the MSX has the same sound chip so why not play some chip tunes on the MSX?
Well, before we spend time working on something just slightly above PC beeper music… are there even any decent PSG tunes? Well, I’ve found at least one that like, “Popsa 2”, as is included in the below mix (scroll down a bit) on YouTube for example, and some of the commenters on this video seem to like “Illusion”.
Unfortunately, it doesn’t work in WebMSX (after 20 seconds or so). But it works in all three (NTSC) openMSX machines I bothered to test with, and it also works on my real MSX1 (Hitachi MB-H2). To get it to run in WebMSX, you have to “Set ROM format” -> “KonamiSCC”, but even then it’ll crash after a few minutes (vs. 20 seconds for e.g. ASCII8). For some reason it doesn’t let me choose “Normal”. I’m quite sure it would work with that setting if it were available. :p I’ll look into the matter at some point, probably. Looks like WebMSX will require a patch to work. Patch is submitted and will probably make it into the next version.
This machine produces NTSC color artifacts like there is no tomorrow.
Caution: writing to certain PSG registers is unsafe on certain MSX machines. I don’t think my code writes to these registers, but I didn’t make 100% sure. (However, openMSX gives you a warning when it notices unsafe writes, and I didn’t get a warning.)
“Popsa 2” was made in a program called ASC Sound Master. The “.asc” file can be downloaded here: https://zxart.ee/eng/authors/d/dreamer/popsa-2/. These .asc files are pretty small. They can be converted to PSG using ZXTune (https://bitbucket.org/zxtune/zxtune/) (and from PSG they can easily be converted to e.g. VGM, see bottom of this post), but the resulting files are too large to fit on a regular MSX1 cartridge.
ZXTune compilation and conversion:
git clone https://bitbucket.org/zxtune/zxtune.git
cd zxtune
make platform=linux system.zlib=1 -C apps/zxtune123/ -j4
bin/linux/release/zxtune123 --convert mode=psg,filename=foo.psg -- Dreamer\ -\ POPSA-2\ \(1994\).asc
The original .asc file is 3720 bytes. The resulting .psg is 129028 bytes. If you convert that to VGM, the resulting size is 187342 bytes.
The PSG file format
The PSG file format is very similar in concept to the VGM file format, except that only one chip is supported, the PSG. It seems it’s primarily used for ZX Spectrum chip tunes. As only one chip is supported, you don’t need the “command byte” that indicates what chip is to be written to. So you only have pairs of “register address” and “register value to write”.
There’s also a header in the first 16 bytes. The first three bytes are “PSG”, dunno about the rest.
The PSG only has 16 (IIRC) registers, and some of those aren’t even relevant for sound. In other words, the registers 0x10 to 0xff don’t exist and the designers of this file format used that opportunity to fit in a “wait” command at 0xff (one raster scan, so 1/50s or 1/60s depending on whether the system is PAL or NTSC). There’s also a command that waits multiple raster intervals, 0xfe, and a command that ends the tune, 0xfd. Ignoring the header, here are the first few bytes of the Popsa 2 PSG file:
All this means: wait 1 raster interval, then write to registers 00 through 0a with values 41, 05, 0b, 01, …, respectively, wait 1 raster interval, write to registers 02, 03, 07, 09, 0a, with values e0, 00, 38, 0d, 0c, respectively, wait 1 raster interval. (As you can see the 0xff command doesn’t take any parameters.)
Now that we know mostly how this file format works, it’s time to think about how to fit roughly 126 KB of data into my 48 KB cartridge. We could easily use an off-the-shelf compression library, but where’s the fun in that? That’s like… modern programming, ew.
We’ll invent another command for PSG, 0xfc, which takes a two-byte parameter that tells it to jump back somewhere (for a while, and then returns to its original location). We also need to write a program that identifies repetitive sections in the music (of which there are plenty). The former is pretty easy, so let’s talk about the latter program first.
Compute MD5 sums of a 100-byte window for every byte in the file. So we end up with 129028-100=128928 MD5 sums. Easy and fast on modern hardware. See code snippet below.
Check if we even have repeated chunks, e.g. by executing: md5sum chunks/* | awk ‘{print $1}’ | sort -n | uniq -c
We may want to check a couple other window sizes to see if we can get better results. A lower window size means we’ll find more repetition, but we need 3 bytes to encode a jump in our PSG file.
Re-assemble PSG file using a quick-and-dirty and probably somewhat buggy script. (See below.)
The resulting data length is 42158 bytes for the Popsa 2 song.
For task (1) we first convert the PSG file into hex, and later into tokens:
xxd -p Dreamer\ -\ POPSA-2\ \(1994\).psg | sed -r -e 's/(..)/\1 /g' | tr -d '\n' > Dreamer\ -\ POPSA-2\ \(1994\).psg.hex
# Then remove 16-byte header using a standard text editor
Then divide the tokens into chunks using the below script, divide_tokens_into_chunks.sh:
#!/bin/bash
N=100 # sliding window length
mkdir -p chunks_N$N
line_count=$(cat tokens | wc -l)
for ((i=0; i<$((line_count-N)); i++)); do
tail -n +$i tokens | head -n $N > chunks_N$N/chunk_$i
done
rm chunks_N$N/chunk_0 # same as chunk_1
You know, looking back at this code for the first time in a while, I see there’s a nice off-by-1 error and a nice rm command to fix half of the problem. But the great thing about this being a hobby is that I don’t need to care. :)
Next, we have a Perl script that creates our PSG file. It needs some help though, so we do this first:
(We can’t do md5sum chunks_N100/* because that expands to a tad too many arguments in our case. xargs automatically cuts down the number of arguments to a more reasonable value.) This is the main program. Usage: ./compress_aggressive_but_convert_to_psg.pl < chunks_N100_md5sums > foo.psg
#!/usr/bin/perl
# dependencies:
# chunks_N$N/ (directory)
# chunks_N$10_md5sums (file) # example generation: find chunks_N10/ | xargs md5sum > chunks_N10_md5sums
use strict;
use warnings;
use feature "switch";
my $N = 100;
my $md5s = {};
my @chunks;
my $md5;
my $file;
my $debug_logged = 0;
my $lines = [];
my $current_output_byte_number = 0;
for (my $chunk_number = 0; <>; $chunk_number++) {
/([a-z0-9]+)\s+([a-zA-Z0-9_\/]+)/;
$md5 = $1;
$file = $2;
if (exists $md5s->{$md5}) {
# can't call chunks that already contain a call because that call would take us beyond the N token window that we can see from where we are
# that means it's likely we'd generate wrong code
# so we'll just move on and maybe we'll find a nicer block
my $target_chunk_number = $md5s->{$md5}->{chunk_number};
my $concatted_chunks = join('', @chunks[max(0, $target_chunk_number-$N)..min($#chunks, $target_chunk_number+$N)]);
if (($concatted_chunks =~ /; call/) or # NOTE "call wait_for_raster" is allowed
($chunk_number - $target_chunk_number < $N)) {
# 1) can't convert due to existing call; nothing to be done here, or
# 2) we can't call something right behind us
# DANGER let's head back to the non-exists path
goto NON_EXIST_PATH;
} else {
if (!$md5s->{$md5}->{converted_to_call}) {
convert_to_callable_sub($target_chunk_number);
$md5s->{$md5}->{converted_to_call} = 1;
}
my $output_byte_number_high = int($md5s->{$md5}->{output_byte_number} / 256);
my $output_byte_number_low = $md5s->{$md5}->{output_byte_number} % 256;
$chunks[$chunk_number] = sprintf("fc %02x %02x ; call " . $md5s->{$md5}->{output_byte_number} . " ($md5)\n", $output_byte_number_high, $output_byte_number_low);
$current_output_byte_number += 3;
# skip next N-1 rows
for (0..$N-1) {
my $foo = <>;
$chunk_number++;
$chunks[$chunk_number] = "";
}
}
} else {
$md5s->{$md5} = {};
$md5s->{$md5}->{chunk_number} = $chunk_number;
$md5s->{$md5}->{converted_to_call} = 0;
NON_EXIST_PATH:
open my $fh, '<', $file or die "Can't open \"$file\": $!";
my $token = <$fh>;
close $fh;
my $asm = convert_to_asm($token);
$md5s->{$md5}->{output_byte_number} = $current_output_byte_number;
$current_output_byte_number += (scalar(split(" ", $asm)));
$chunks[$chunk_number] = $asm;
}
}
print foreach @chunks;
print "infloop:
jr infloop\n";
# no changes needed
sub convert_to_callable_sub($) {
my $block_number = shift;
}
# don't actually do anything here
sub convert_to_asm($) {
my $string = shift;
return "$string";
}
sub min($$) {
my ($a, $b) = @_;
return $a if ($a < $b);
return $b;
}
sub max($$) {
my ($a, $b) = @_;
return $a if ($a > $b);
return $b;
}
The output of this program is in hex. Now we just need some assembly code to read the data and put it into the PSG registers. Here’s the core part:
ld hl,psg_begin
main_loop:
ld a,(hl)
cp 0xff
jr z,wait
cp 0xfe
jr z,wait_n_times
cp 0xfd
jr z,end
cp 0xfc
jr z,jump
jr register_write
inc_loop:
inc hl
jr loop
wait:
call wait_for_raster
jr inc_loop
register_write:
ld a,(hl)
out (0xa0),a
inc hl
ld a,(hl)
out (0xa1),a
jr inc_loop
wait_for_raster:
in a,(0x99)
and 128
cp 128
jr nz,wait_for_raster
ret
psg_begin:
include "foo.psg"
ds 010000h-$ ; fill rest with 0s
Understanding the above should help understanding the full implementation. (The above doesn’t include the code for the 0xfe, 0xfd, and 0xfc commands.) Note that we can’t use the above wait_for_raster on NTSC machines because the tune assumes 50 Hz. So we’ll instead emulate the 50 Hz interval using a busy loop.
For 0xfd (end of song), we just enter an infinite loop. For 0xfe, we just call wait_for_raster multiple times. For 0xfc, we need to store where we left off, then set hl to the address in the parameter, then execute exactly 100 main loop runs, then set hl back to its previous address and continue as normal.
Here’s the code, which also includes some VRAM writes to visualize the music a little bit. Does it look good? Eh, I dunno. It was an experiment. I changed the registers to be displayed because some registers don’t see updates very often. The overall visuals are a bit noisy, but there is one section that looks good in my opinion, and it’s also the section that I like best in the tune, right at the end. You can clearly see one of the registers changing right in sync with the doorbell sound. (It looks even more in sync in openMSX.)
N: equ 100
org 4000H
db "AB"
dw entry_point
db 00,00,00,00,00,00,00,00,00,00,00,00
SetVdpWrite: macro high low ; from http://map.grauw.nl/articles/vdp_tut.php
ld a,low
out (0x99),a
ld a,high
add 0x40
out (0x99),a
endm
vpoke: macro value
ld a,value
out (0x98),a
endm
entry_point:
; copy cart rom (c000-f000) to ram
in a,(0a8h)
and 11000000b ; we want to know which slot is RAM, and AFAIK RAM should be mapped in at 0xc000-0xffff.
ld c,a ; save value for later
in a,(0a8h)
and 00001100b ; we are executing from cartridge ROM at 0x4000~0x7fff, so the 2-bit value for this region is known correct. we just have to make the slots above this one the same value.
ld b,a ; save a
rla ; << 1 (now have 000xx000b)
rla ; << 1 (now have 00xx0000b)
or b ; | saved b (now have 00xxxx00b)
rla ; << 1 (now have 0xxxx000b)
rla ; << 1 (now have xxxx0000b)
or b ; | saved b (now have xxxxxx00b)
; ld a,01010100b ; set pages 0: rom 1: rom 2: cart 3: cart
out (0a8h),a
copy_c000_f000:
ld hl,0c000h ; start at c000
copy_c000_f000_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
and 00111111b ; only keep settings for lower three slots
or c ; add in setting for top slot (saved earlier)
; ld a,011010100b
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 0f0h
jp z,other_init ; done with this copy
jp copy_c000_f000_loop
; entry_point:
; ld a,0xd4
; out (0xa8),a ; set slots
other_init:
; set ports to bios:cart:cart:ram
in a,(0a8h)
and 00111111b ; only keep settings for lower three slots
or c ; add in setting for top slot (saved earlier)
out (0a8h),a ; set port
; set colors
ld a,011110000b ; set data to be written into register (white on black)
out (099h),a
ld a,010000111b ; set register number (7)
out (099h),a
SetVdpWrite 0x20 0x05
vpoke 0x0f ; set white on black for some part of the screen
vpoke 0x0f ; set white on black for some other part of the screen
video_init:
; put chars /0123456789 into 0x1800-0x1AFF
SetVdpWrite 0x18 0x00
ld b,64 ; 64 chars
video_loop_1:
vpoke 0x2f
djnz video_loop_1
ld b,64 ; 64 chars
video_loop_2:
vpoke 0x2f
djnz video_loop_2
ld b,64 ; 64 chars
video_loop_3:
vpoke 0x33
djnz video_loop_3
ld b,64 ; 64 chars
video_loop_4:
vpoke 0x33
djnz video_loop_4
ld b,64 ; 64 chars
video_loop_5:
vpoke 0x36
djnz video_loop_5
ld b,64 ; 64 chars
video_loop_6:
vpoke 0x36
djnz video_loop_6
ld b,64 ; 64 chars
video_loop_7:
vpoke 0x31
djnz video_loop_7
ld b,64 ; 64 chars
video_loop_8:
vpoke 0x31
djnz video_loop_8
ld b,64 ; 64 chars
video_loop_9:
vpoke 0x35
djnz video_loop_9
ld b,64 ; 64 chars
video_loop_10:
vpoke 0x35
djnz video_loop_10
ld b,64 ; 64 chars
video_loop_11:
vpoke 0x37
djnz video_loop_11
ld b,64 ; 64 chars
video_loop_12:
vpoke 0x37
djnz video_loop_12
ld b,64 ; 64 chars
ld b,0 ; flag to indicate whether we are jumping around at the moment (0 means we aren't) (NOTE: nested jumping isn't supported)
ld c,0xa0 ; first PSG port
ld hl,psg_begin
jr main_loop
loop:
ld a,b
cp 0
jr z,main_loop ; b isn't set so just head back to the loop
pop af
dec a
cp -1
jr z,restore_hl
push af ; don't need this on the stack if we go to restore_hl, so place it after the jump
jr main_loop
restore_hl:
ld b,0 ; unset flag
pop hl
inc hl
; and continue executing into loop
main_loop:
ld a,(hl)
cp 0xff
jr z,wait
cp 0xfe
jr z,wait_n_times
cp 0xfd
jr z,end
cp 0xfc
jr z,jump
jr register_write
inc_loop:
inc hl
jr loop
wait:
call wait_for_raster_50hz_emu
jr inc_loop
wait_n_times: ; safe to assume that param isn't 0
push bc
inc hl
ld b,(hl)
wait_n_times_loop:
call wait_for_raster_50hz_emu
djnz wait_n_times_loop
pop bc
jr inc_loop
end:
jr end ; infinite loop
jump:
inc hl
ld d,(hl)
inc hl
ld e,(hl)
push hl
ld b,1 ; signal that we're calling a previous segment
ld a,N ; we want to execute N instructions before going back to where we left off
push af
ld hl,psg_begin
add hl,de
jr loop
register_write:
ld a,(hl)
out (c),a
; really we only need ld a,(hl) and out (0xa1),a, but let's poke around in the VRAM to make this program slightly less boring
; we'll modify the tile definitions of characters /, 0, ..., 9 (8 bytes each starting at 0x178) and just put in the same value we're writing to the PSG register
or a ; clear carry flag to make rla behave
; a = a*8 for vram write address
rla ; *2
rla ; *2 (*2*2 == *4)
rla ; *2 (*2*2*2 == *8)
ld d,a ; vram write address
inc hl
ld a,(hl)
ld e,a ; vram write value
out (0xa1),a
ld a,0x78
add a,d ; vram address low byte is 0x78 + (psg register)*8
; color change code currently commented out because it's not very pleasant to look at
; ; let's also change some colors when register 5 is written to, which doesn't appear to happen very often
; ; for register 5 a is 5*8 + 0x78 = 0xa0
; cp 0xa0
; jr nz,skip_color_change
; ld d,a
; ld a,e
; out (099h),a
; ld a,010000111b ; set register number (7)
; out (099h),a
; ld a,d
skip_color_change:
SetVdpWrite 1 a ; vram address high byte is 1 (full address: 0x178)
vpoke e
vpoke e
vpoke e
vpoke e
vpoke e
vpoke e
vpoke e
vpoke e
jr inc_loop
wait_for_raster:
in a,(0x99)
and 128
cp 128
jr nz,wait_for_raster
ret
wait_for_raster_50hz_emu:
; CPU clock is 3579545 Hz
; decrement and loop routine takes 36 instructions per loop run (wait_for_raster_50hz_emu_loop up to (not including) low_0)
; (https://www.overtakenbyevents.com/tstates/)
; want routine to finish in 1/50 or a second, so:
; 3579545/50/36=1988.636111111111, let's very scientifically, er, let's throw out that whole calculation and say 1650 because we have overhead and I have experimentally determined that to sound close enough to the original :p
; our overhead varies depending on code path. some rhythm problems are audible, but not _too_ terrible
ld de,1650
wait_for_raster_50hz_emu_loop:
dec de
ld a,e
cp 0
jr z,low_0
jr wait_for_raster_50hz_emu_loop
low_0:
ld a,d
cp 0
jr z,high_low_0
jr wait_for_raster_50hz_emu_loop
high_low_0:
ret
psg_begin:
include "foo.psg"
ds 010000h-$
Compiles with z80asm. Other assemblers might need some tweaks.
Bonus: converting PSG files to VGM
This is implemented in straight-forward C. Compilation: cc -o psg2vgm psg2vgm.c Execution: ./psg2vgm Dreamer\ -\ POPSA-2\ \(1994\).psg | xxd -r -p > foo.vgm
Motivation: test a probably broken YM2151 on a breadboard. We need to play certain instruments in a certain way to reproduce the problem. I won’t bother you with the details in this blog post, but I’d say it worked well.
Introduction
The MSX SFG-01 extension module contains some software on a 16 KB ROM, some MIDI hardware, and an FM audio generator chip. The software can be started by typing “CALL MUSIC” in the BASIC prompt. The software looks like this:
In this state, you can press left and right to select a different voice. There’s a lot of them!
If you have an external (piano) keyboard connected to the SFG-01 module (not via MIDI, but via a proprietary connector), you can now hit keys and hear them played using the settings displayed above. The above software makes it look like you can only select between a couple different instruments (currently, BRASS 1 is selected), but the YM2151 is a full-fledged synthesizer chip; you can define any instrument you want just by poking into a couple registers. And you have 8 independent voices!
5 YA=$9F40 : YD=$9F41 : V=0
10 REM: MARIMBA PATCH FOR YM VOICE 0 (SET V=0..7 FOR OTHER VOICES)
20 DATA $DC,$00,$1B,$67,$61,$31,$21,$17,$1F,$0A,$DF,$5F,$DE
30 DATA $DE,$0E,$10,$09,$07,$00,$05,$07,$04,$FF,$A0,$16,$17
40 READ D
50 POKE YA,$20+V : POKE YD,D
60 FOR A=$38 TO $F8 STEP 8
70 READ D : POKE YA,A+V : POKE YD,D
80 NEXT A
What’s going on over here? First, we poke $DC into register $20. Then $00 into $38. Then $1B into $40, $67 into $48, $61 into $50, etc. (We increase the address register by 8 on every loop execution because we only want to load the marimba sound into the registers for voice 0. For voice 1, the registers would be $39, $41, $49, $51, $59, $61, $69, etc. For voice 2, $3A, $42, $4A, etc.)
Getting the patches off the SFG-01’s firmware using openMSX and a TCL script
So what are these magic values? Well, I’m not a synthesizer expert, but they control stuff like ADSR (attack, decay, sustain, release), among other things. See https://en.wikipedia.org/wiki/Envelope_(music) for more information.
Well, if you’re like me you probably won’t immediately come up with the correct values that imitate a specific sound. So let’s extract these values! That’s the main part of this blog post. Unfortunately they aren’t in an easy-to-guess data structure on the software ROM. So instead we’ll be using openMSX’ VGM recording script! This script is in TCL and I’m in the process of getting some additions merged to make it work with the SFG-01’s YM2151. In the meantime, you can grab it from here: https://github.com/qiqitori/openMSX/blob/vgm_rec_ym2151/share/scripts/_vgmrecorder.tcl. Replace your openMSX’ installation’s version of this script (probably /usr/share/openmsx/scripts/_vgmrecorder.tcl) and restart openMSX. Then add the SFG-01 extension (Menu -> Hardware -> Extensions -> Add… -> Yamaha SFG-01 FM Sound Synthesizer Unit) and restart your emulated MSX. Then type “CALL MUSIC” and you should get something like the above screenshot.
Next, press F10 to open the console and type “vgm_rec start SFG-01”. Close the console by pressing F10 again. Then select a different instrument using the cursor keys. Then open the console again and type “vgm_rec stop”. If everything went well, you should now have a playable VGM file containing the instrument patch. (If you play it with vgmplay, nothing will happen because no note is being pressed.) Let’s look at the generated VGM file in a hex editor:
We have a header and a bunch of byte triplets, each starting with “54”, which indicates that a YM2151 command follows. We also have “61”s, which indicate that the YM2151 is to play a certain number of samples with the current settings. (These two numbers are defined in the VGM specification.) The next byte is the register address, the next byte the data to put into that register. We see a bunch of writes to registers $12 and $14. Remembering the BASIC script, we should actually only be interested in writes to $38 to $FF. We can easily extract these like this:
The firmware starts writing the patch at register address $E0. Note that this program doesn’t appear to be setting channel 0, just channels 1-7. Also note that we don’t have anything for registers $60-$7F. We don’t need those; they just control the loudness.
The X16 page also had a BASIC program that hits some keys so we can actually figure out if the patch sounds right. This is the code:
10 YA=$9F40 : REM YM_ADDRESS
20 YD=$9F41 : REM YM_DATA
30 POKE YA,$29 : REM CHANNEL 1 NOTE SELECT
40 POKE YD,$4A : REM SET NOTE = CONCERT A
50 POKE YA,$08 : REM SELECT THE KEY ON/OFF REGISTER
60 POKE YD,$00+1 : REM RELEASE ANY NOTE ALREADY PLAYING ON CHANNEL 1
70 POKE YD,$78+1 : REM KEY-ON VOICE 1 TO PLAY THE NOTE
80 FOR I=1 TO 100 : NEXT I : REM DELAY WHILE NOTE PLAYS
90 POKE YD,$00+1 : REM RELEASE THE NOTE
Note that this program is operating on voice 1, not voice 0. What’s going on here? We write $4A into register $29. This selects the “A” note in octave 4. It’s just a coincidence that hex A is note A. ($0 is C#, $1 is D, $2 is D#, …, $A is A.) Next we write 1 into register $08. That ends any note already playing on voice 1. (We could have done that first.) Then we put $79 into the same register to play our select note. (“A” in octave 4). Then we wait a bit, and release the note by putting 1 into the same register again.
Playing notes with the extracted patches
Now let’s see if these patches produce the expected sound. To do that, we could manually add a couple note commands to the generated VGM files using our hex editor. It would just be a couple byte triplets. However, I decided to quickly hack together a short Perl program that generates a hex dump that can be converted back to a binary file that then happens to be a VGM file. So you would put this in, say, brass1_patch_with_body_polyphonic.pl and concatenate its output to a header (which I’ll show below). The result can be played with vgmplay. (Note: there is a cleaned up version of this code at the bottom of this post.)
The header is as follows. Note that you should normally specify an end offset in the header, but vgmplay is nice and doesn’t care if that offset is set correctly or not. Name it simple_vgm_header.hex or something.
You can replace the contents of the @data array with the extracted patch. Remember that the @data array starts with $DC followed by the value to be put into $38, the value to be put into $40, $48, etc., while the extracted patch starts with register address $E0. ($E1 actually because it doesn’t set voice 0, just voices 1-7.) In addition, the extracted patch contains register writes to set all voices (except 0) to the selected instrument. So let’s have another look at portions of the extracted patch:
(Oh, never mind the 61 at the end, we didn’t actually want that.) This writes $00 to $39-$3F, $14 to $41-$47, $0C to $49-$4F, $12 to $51-$57, $06 to $59-$5F, $92 to $81-$87, etc.
So we modify the @data array like this:
@data = (0xDC, 0x00, 0x14, 0x0C, 0x12, 0x06, # above numbers
0x21, 0x17, 0x1F, 0x0A, # volume, can stay as-is
0x92, 0x5E, 0x12, 0x59, 0x0A, 0x06, 0x84, 0x85, 0x02, 0x02, 0x00, 0x00, 0x47, 0x19, 0x08, 0x09); # unfortunately I'm a bit silly and don't quite remember which patch this was, but it might have been PORGAN2 :p
Let’s also extract KOTO, just out of interest. We can make our command line a bit more intelligent so we can read off the values for @data a little easier:
As the koto has fast decay, we may want to reduce the amount of time to wait between notes by changing the “256” in “for ($i = 0; $i < 256; $i++) { # wait” to something much smaller, such as 8. Here’s what it sounds like:
As promised, here’s the cleaned up version of the VGM generator code:
#!/usr/bin/perl
my @data = (0xDC, 0x00, 0x1B, 0x67, 0x61, 0x31, 0x21, 0x17, 0x1F, 0x0A, 0xDF, 0x5F, 0xDE, 0xDE, 0x0E, 0x10, 0x09, 0x07, 0x00, 0x05, 0x07, 0x04, 0xFF, 0xA0, 0x16, 0x17); # marimba
# my @data = (0xDC, 0x21, 0x01, 0x01, 0x23, 0x11, 0x21, 0x17, 0x1F, 0x0A, 0x8d, 0x15, 0x4f, 0x52, 0x06, 0x0e, 0x08, 0x83, 0x02, 0x00, 0x00, 0x00, 0x18, 0x28, 0x18, 0x28); # brass 1
# my @data = (0xDC, 0x00, 0x14, 0x0C, 0x12, 0x06, 0x21, 0x17, 0x1F, 0x0A, 0x92, 0x5E, 0x12, 0x59, 0x0A, 0x06, 0x84, 0x85, 0x02, 0x02, 0x00, 0x00, 0x47, 0x19, 0x08, 0x09); # porgan2?
# my @data = (0xDC, 0x01, 0x33, 0x31, 0x34, 0x31, 0x21, 0x17, 0x1F, 0x0A, 0xda, 0xdc, 0xdd, 0xdf, 0x08, 0x04, 0x05, 0x8a, 0x05, 0x02, 0x04, 0x03, 0x27, 0x36, 0x14, 0x15); # koto
sub voice_init {
my ($v) = @_;
my $i = 0;
printf("%02x %02x %02x ", 0x54, 0x20+$v, $data[$i]);
$i++;
for ($a=0x38; $a <= 0xf8; $a += 8, $i++) {
printf("%02x %02x %02x ", 0x54, $a+$v, $data[$i])
}
}
sub play_note {
my ($v, $note, $length) = @_;
printf("%02x %02x %02x ", 0x54, 0x28+$v, $note);
printf("%02x %02x %02x ", 0x54, 0x08, 0x0+$v); # release voice $v
printf("%02x %02x %02x ", 0x54, 0x08, 0x78+$v); # key down for voice $v
for ($i = 0; $i < $length; $i++) { # wait
printf("%02x ", 0x63);
}
}
sub release_voice {
my ($v) = @_;
printf("%02x %02x %02x ", 0x54, 0x08, 0x0+$v); # release voice $v
}
voice_init(0);
voice_init(1);
voice_init(2);
for (1..3) {
play_note(0, 0x4a, 8); # 4 means octave 4, A means A (concidence)
play_note(1, 0x50, 8); # 5 means octave 5, 0 means C#
play_note(2, 0x54, 32); # 5 means octave 5, 4 means E (But it's just three semitones from C# to E? Shouldn't it be 0x53? No, for some reason, 3, 7, B, and F are skipped)
release_voice(0);
release_voice(1);
release_voice(2);
}
printf("\n");
Now that we have a koto, let’s play a tune that sounds good on the koto!
I have a Yamaha MSX1 (YS-503) with 64 32 KB of RAM and an SFG-01, which has a YM2151 on it. I do not have a floppy drive, but I have a way to easily “make cartridges” that are up to 48 KB in size. This blog post explores the source code of vgmplay-msx and ports portions of the program to work off a cartridge. Here’s how the result looks in openMSX:
Here are ROM files that work in OpenMSX, one with the SFG-01 inserted into slot 2, and the other with the SFG-01 inserted into slot 3, both playing the first ~20 seconds of track 2 on https://vgmrips.net/packs/pack/fantasy-zone-ii-dx-sega-system-16c, “10 Years After ~ Cama-Ternya [Demo]”.
VGM files have a 128 or 256-byte header followed by the actual song data. The song data entirely consists of 1-byte commands possibly followed by a couple bytes of arguments to the command. The only commands we are interested in are “YM2151 register write” and the “wait” commands, of which there are a few. (And maybe the end of song/loop commands.) Everything else is irrelevant for our setup and what we want to do.
We only have 48 KB of ROM space, which means that it’s a bit of a tight fit for the program and the song data. The stock vgmplay.com file is about 32 KB, but it includes code (src/drivers/) for a lot of chips. We only need src/drivers/SFG.asm. There are also vast regions of 0s. We also don’t need any code to make song data fit into more than 64 KB of RAM (src/MappedReader.asm). We don’t need support for compressed .vgm files. And we don’t need any MSX-DOS-specific code, nor do we need code to handle reading from the floppy drive. Song data tends to be relatively large too: the song I used in Raspberry Pi Pico implementation of the YM3012 DAC (mono) was around 1 minute and is 68 KB in size. We’ll have to either truncate it, or find something shorter or simpler.
vgmplay-msx is written in a rather unusual assembly dialect. The assembler supports scoping, and there appears to be a bit of a “class” hierarchy. For example, MappedReader (src/MappedReader.asm) extends Reader (lib/neonlib/src/Reader.asm).
After putting the MSXDOS22.ROM into .openMSX/share/systemroms and booting from MSXDOS22.dsk, and adding the Yamaha SFG-01 extension (Hardware -> Extensions), and executing ‘make’ in the vgmplay-msx source directory, I was able to execute ‘vgmplay foo.vgm’ in MSX-DOS and hear the VGM file being played back in openMSX. After reading the code for a little bit, I opened and connected the debugger. In System -> Symbol manager, we can read the symbols generated by the assembler, vgmplay.sym, which are quite convenient.
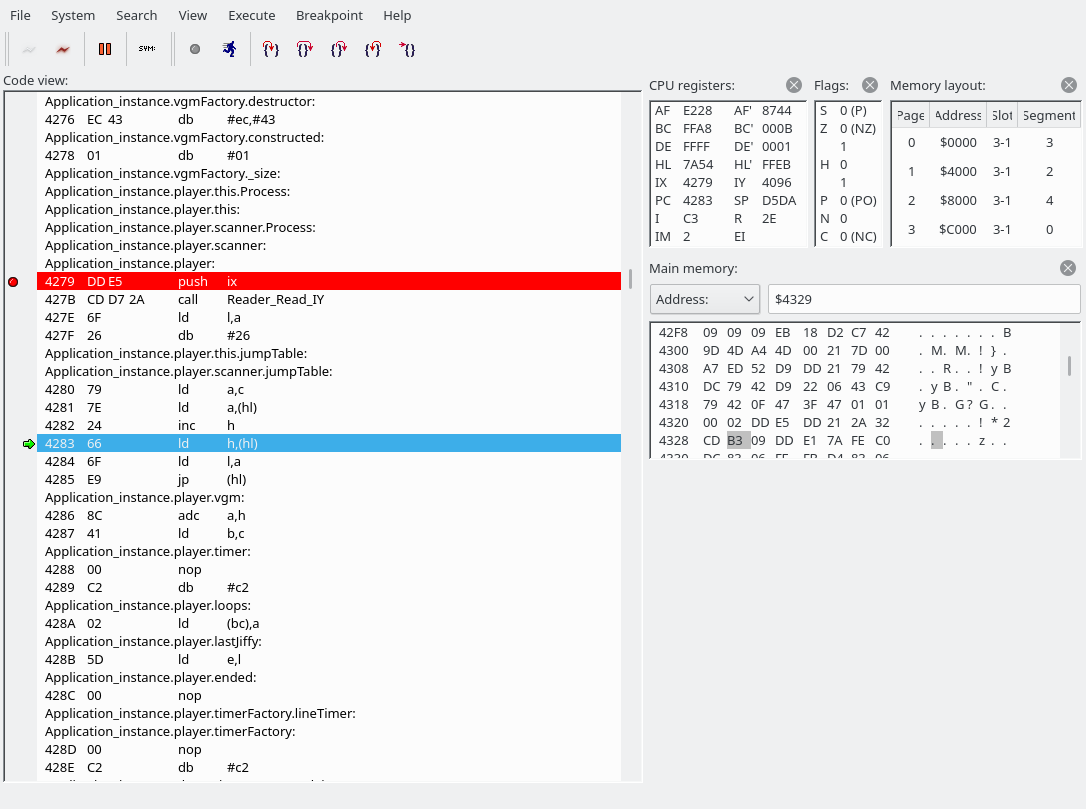
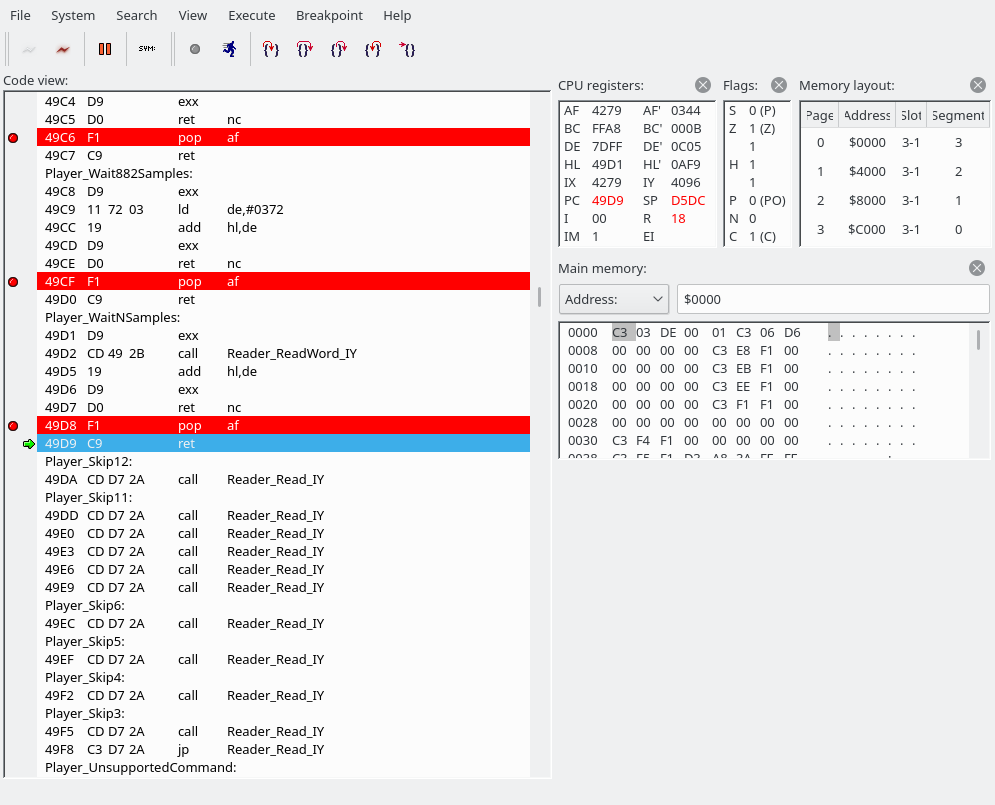
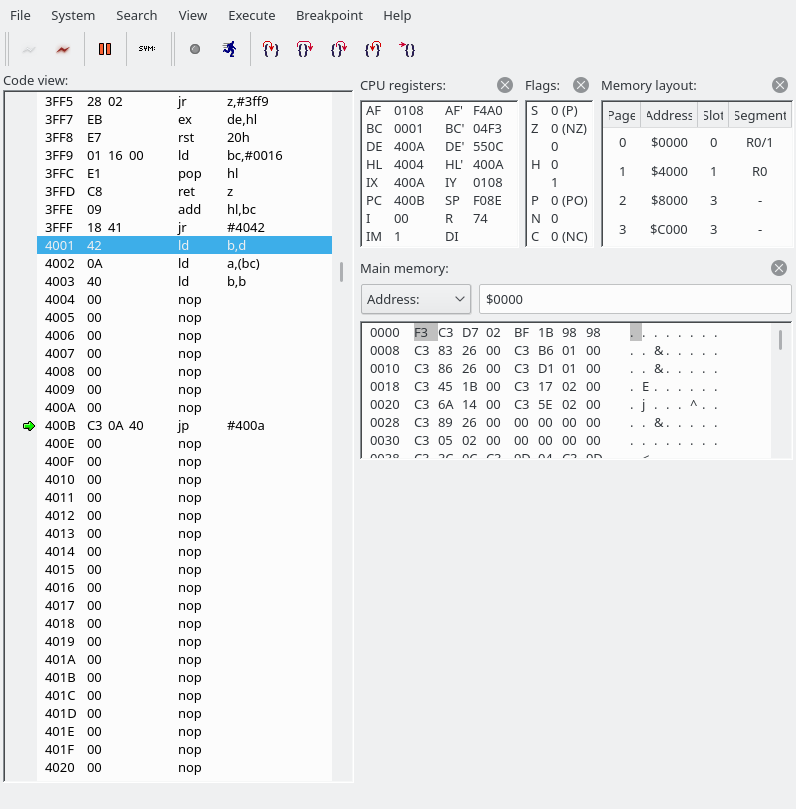
Note: openMSX debugger fails to show the correct disassembly when there is a label in the middle of an instruction. Below, 427F 26 db #26 and 4280 79 ld a,c are actually a single instruction, which you can manually decode using something like this:
Here, in Reader_Read_IY we read a byte from the VGM music data. We then create an address by reading one byte from 79xx (where xx is the read byte) and one byte from 80xx (again, xx is the previously read byte) and jump to it. This is the main jump table.
The jump table is defined in src/Player.asm, and for efficiency reasons is separated into two in Player_InitCommandsJumpTable in the same file.
; Shuffles the commands jump table so that the LSB and MSB are separated.
; This allows faster table value lookups.
Player_InitCommandsJumpTable: PROC
...
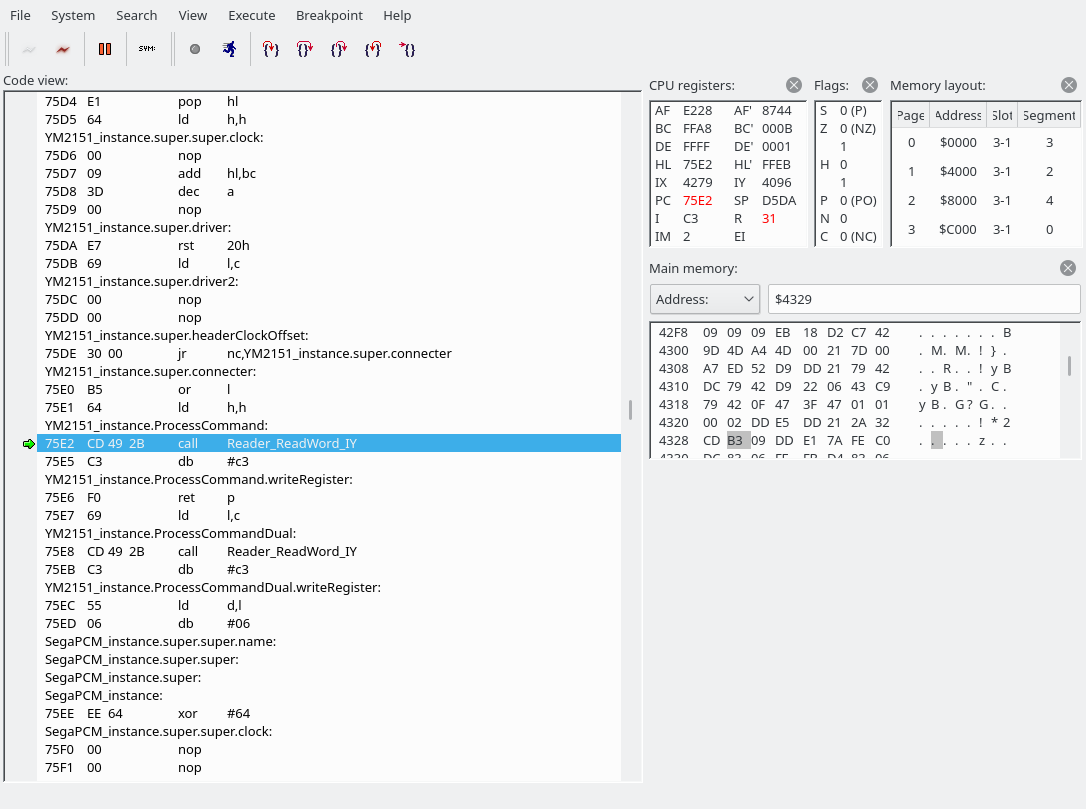
The byte we read was a 0x54, which indicates that we are going to write to the YM2151. This is where we have jumped:
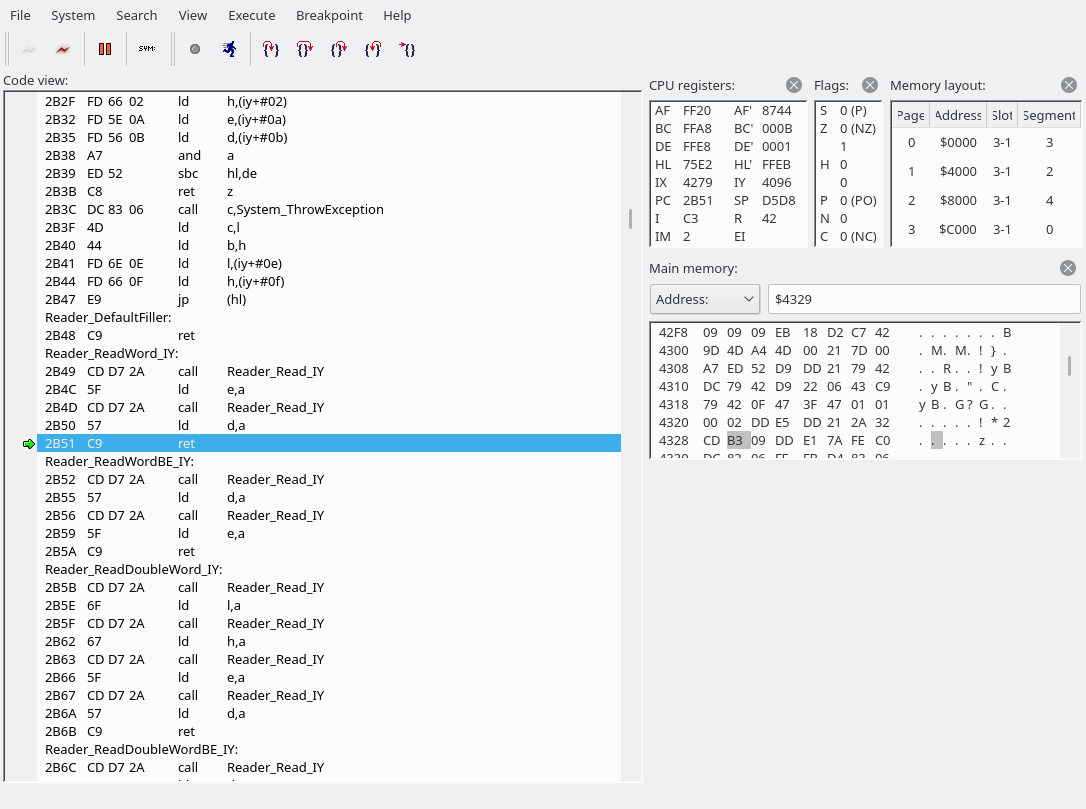
We are going to read a word (two bytes). The first byte holds the address of the YM2151 register to write to, the second byte the data. It looks like the next instruction has been butchered by the openMSX debugger again. C3F069 is actually “JP 69F0”.Reader_ReadWord_IY simply calls Reader_Read_IY twice. (The first screenshot also used Reader_Read_IY to fetch the command byte.) The address goes into the E register, the data into the D register.
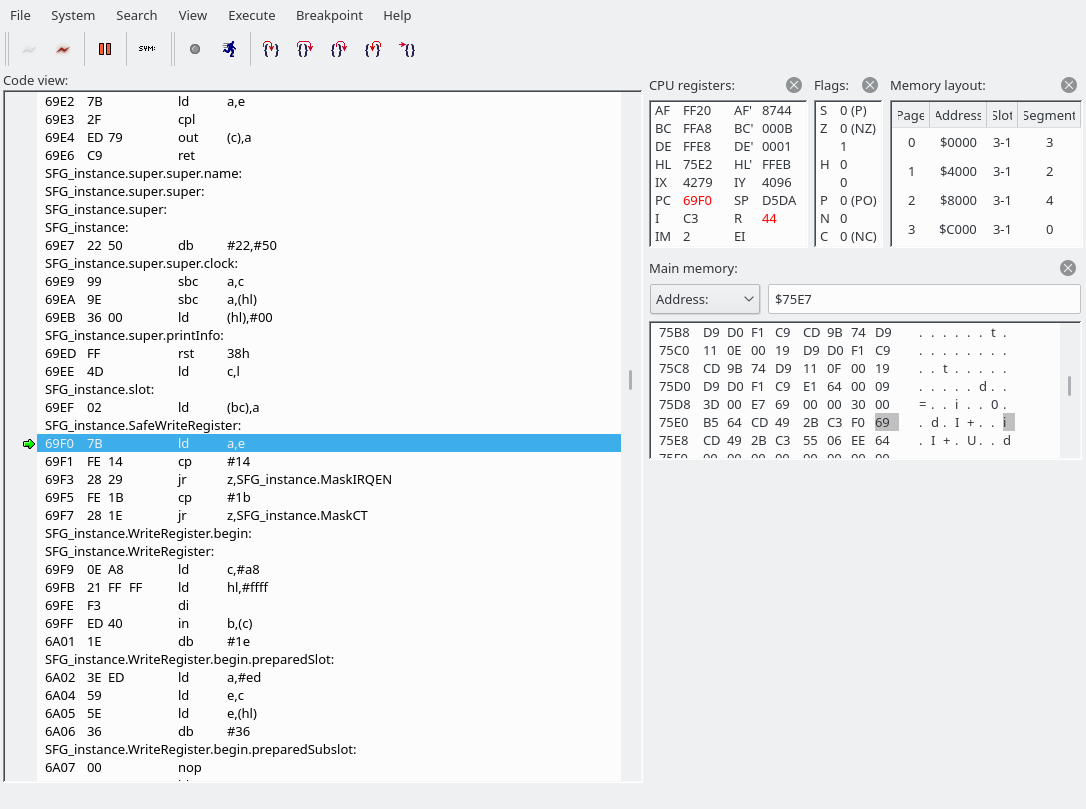
We have now jumped to 69F0. The source file is src/drivers/SFG.asm.
There are a few things to unpack here.
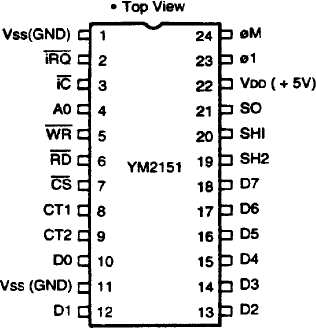
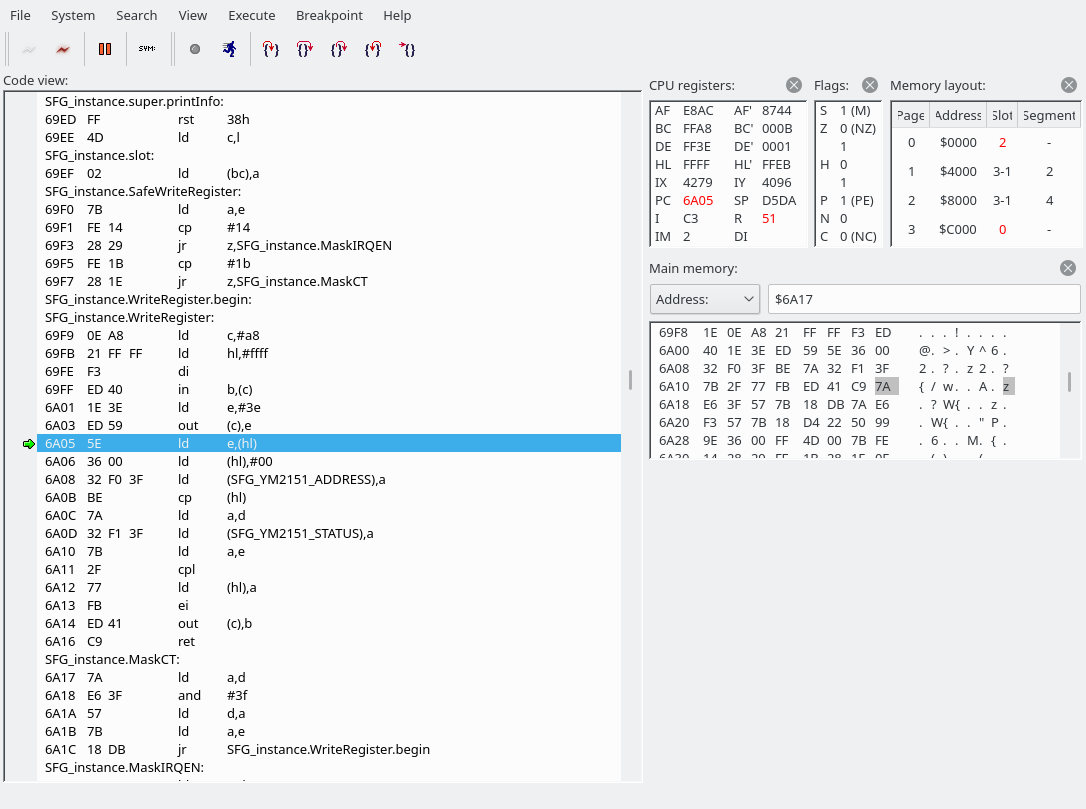
First of all, we look into the address value and may jump to MaskIRQEN or MaskCT if the address is exactly 0x14 or 0x1b, respectively. Our E is set to E8, so that doesn’t apply here, so we fall right through into SFG_instance.WriteRegister. I am going to guess that the MaskIRQEN and MaskCT sections modify some bits in the address register to perhaps turn off a feature in the YM2151 that would trigger output on the interrupt or one of the CT pins, but I don’t know for sure. Here’s a pinout of the YM2151 BTW:
There are IRQ and CT pins, and IIRC they are output pins.
Next, let’s edit the symbol file to work around the debugger’s inability to disassemble instructions that have labels in the middle… Search for ‘6a02’ and ‘6a07’ in the symbol file, remove the symbol file from the debugger, and add it back in again. Then our WriteRegister function becomes a little clearer:
We read from and write to the A8 I/O port. This screenshot is from after executing the OUT instruction, which modifies the slot selection; the modifed slots are highlighted in red in the upper-right corner.
The SFG’s YM2151 registers are memory-mapped(!) at the following addresses:
If you know quite a bit about how the MSX works, you may know that the MSX in general doesn’t use memory-mapped I/O, and you may also know that 0000-3FFF is where the system ROM is usually located (mapped; it can be unmapped and something else can be mapped instead). In the screenshot above, you can see that there’s an “in b,(c)” instruction at 69FF, where C holds #A8. This is the I/O register that allows you to remap stuff. See this link if you want to know more about how this register works: http://map.grauw.nl/resources/msx_io_ports.php#ppi. (BTW, this page is probably authored by the same person who wrote vgmplay-msx.) So “in b,(c)” saves the contents of the #A8 into B.
In order to perform memory-mapped I/O, we have to unmap any ROM or RAM currently mapped in. And when we’re done, we obviously have to map it back in. (Oh, good that we saved the #A8 contents into B.) ROM and RAM mappings vary between MSX models, which means the OUT part of the code is probably generated dynamically somewhere in the init code. (Hence the labels in the middle of our instructions.) The next instructions (6A05 and 6A06) save the contents of the subslot register (FFFF) into E (so we can change it back later) and set the subslot register to 0. (Note that at this point our register address has already been moved into register A, while data is still in register D.)
After the OUT is done, we just write our address to SFG_YM2151_ADDRESS and our data to SFG_YM2151_STATUS (which is an alias of SFG_YM2151_DATA, the address is 100% the same). The “cp (hl)” instruction in the middle is just to wait a short moment according to the comment in the source code: “; R800 wait: ~4 bus cycles”. When we’re done, we set the slot and subslot registers back to what they were.
So that’s how we perform a register write. We also need to know how to wait a specific number of cycles. VGM files are full of wait commands, and if the amount of waiting we do is too imprecise, that will definitely be audible. The wait commands in VGM files assume an output sample rate of 44100 Hz, which is different from the actual sample rate on real hardware. The number specifies the number of samples to just leave the YM2151 alone to do its thing. In reality, the YM2151 in the SFG-01 outputs at 3579545/2/32 = 55930.390… Hz. The Z80 runs at 3579545 Hz. So we get 64 Z80 cycles per sample, but because the VGM file wait cycles assume a different sample rate, just adding NOPs would end up being rather imprecise. What’s more, some VGMs are for machines where the YM2151 is clocked at 4000000 Hz, which results in an output rate of 4000000/2/32 = 62500 Hz.
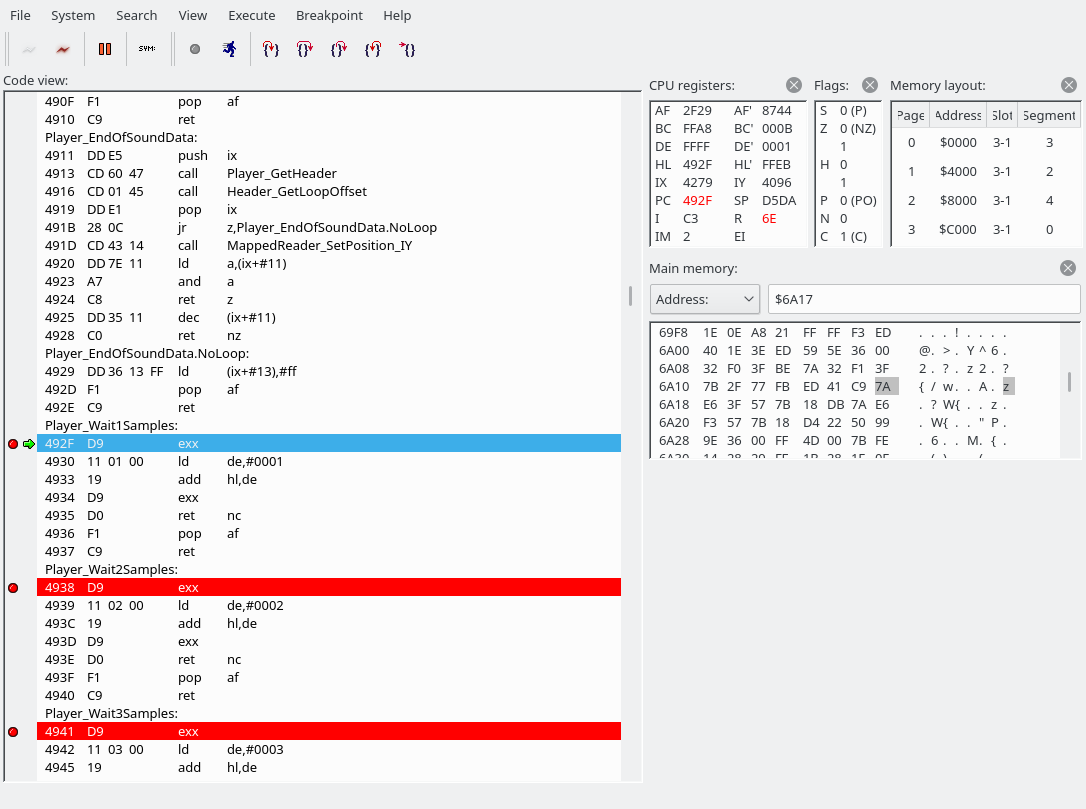
So let’s… jump back to our jump table to see what happens when a wait instruction is encountered!
As we can see, there are a lot of commands that perform waits. For Player_Wait1Samples, we jump to 492F:
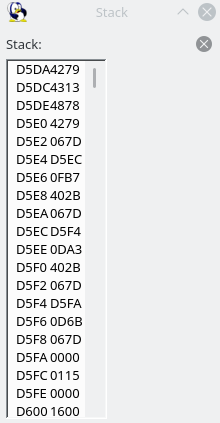
The “exx” instruction switches between the directly usable registers and the shadow registers. (“EXX exchanges BC, DE, and HL with shadow registers BC’, DE’, and HL’.”) Wow, the Z80 has so many registers. All we do here is add 1 to hl’. In a special case, we pop AF from the stack, but we have no choice but to ignore that for now. And basically, Player_Wait2Samples, Player_Wait3Samples, …, Player_Wait16Samples, Player_Wait735Samples, Player_Wait882Samples, all work the same. Player_WaitNSamples grabs its argument, and apart from that also works the same as the others. Here’s a screenshot of the stack, and it’s always the same for all Player_Wait* sections:
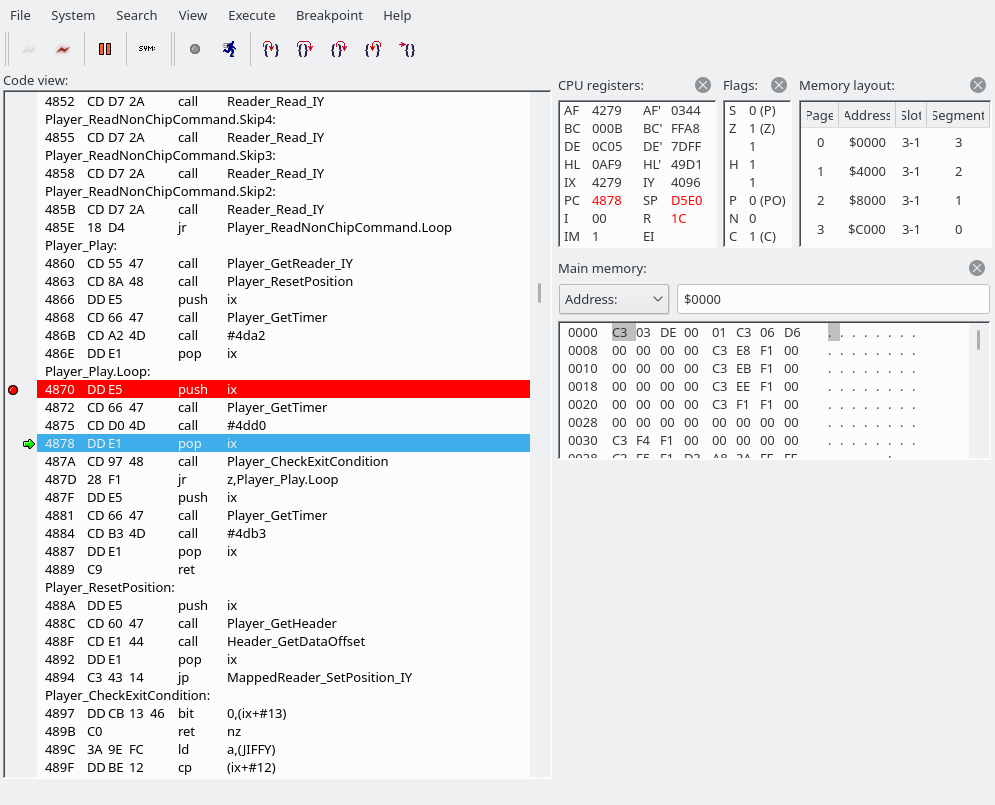
That is, we are going to jump back to 4279, and we have already seen the code at 4279. Scroll up to see it again. It’s our main loop body, where we grab a command and use the jump table to jump somewhere. (What I hadn’t noticed or mentioned above was that it begins with a “push ix” command, which seemingly puts 4279 back on the top of the stack each time.)
Well, this is a good time to think about that “ret nc pop af ret” bit again, right? If the carry flag is set, we do not return. Instead, we grab 4279 off the stack and shove it into the AF register. Then we return, and this time we should return to 4313, according to the above stack screenshot. The carry flag is set if shadow HL overflows. Currently, it’s FF71. Hmm, just a few F9 presses maybe.
Intermission, sort of
But let’s take a step back and think about what we have seen so far. Perhaps the MSX is just way too slow to play VGMs in real time with perfect timing, and it just makes sense to skip all wait commands and just sync whenever the carry flag is set?
There’s a lot of timing code, and it’s all a bit complicated because the code seems very un-assembly-like. (But as this piece of software supports many different configurations, the somewhat object-oriented patterns may maybe make sense.) Looking back at the projects homepage, it appears that on the MSX2, the timing is 300 Hz, so perhaps that means the waits are ignored as they are encountered, but everything is put in sync (up to?) 300 times a second. It looks like on the MSX1 the timing is either 50 or 60 Hz.
The timing resolution is 50 or 60 Hz on MSX1 machines with a TMS9918 VDP, 300 Hz on machines with a V9938 or V9958 VDP, 1130 Hz if a MoonSound or OPL3 is present, and 4000 Hz on MSX turboR.
While the site says that vgmplay-msx works on MSX1 machines, I’m not entirely sure what kind of hardware configuration in e.g. openMSX would allow us to do that, because vgmplay-msx needs 128 KB of RAM, and MSX-DOS2. As far as I know you also can’t give an existing MSX2 machine an MSX1-class TMS9928A VDP, because the MSX2 logo requires the V9938. (Maybe you could try to give it an MSX1 BIOS too, but I think I’m outta here.)
(End of intermission)
So what we’re going to do is: recompile without LineTimer support by commenting out in src/timers/TimerFactory.asm:
TimerFactory_Create:
; call TimerFactory_CreateTurboRTimer ; this line and
; call nc,TimerFactory_CreateOPLTimer ; this line and
; call nc,TimerFactory_CreateLineTimer ; this line.
call nc,TimerFactory_CreateVBlankTimer ; this line is left as-is
ret
So anyway, we’re now running using the VBlankTimer and added breaks like this:
And after the ret we end up here:
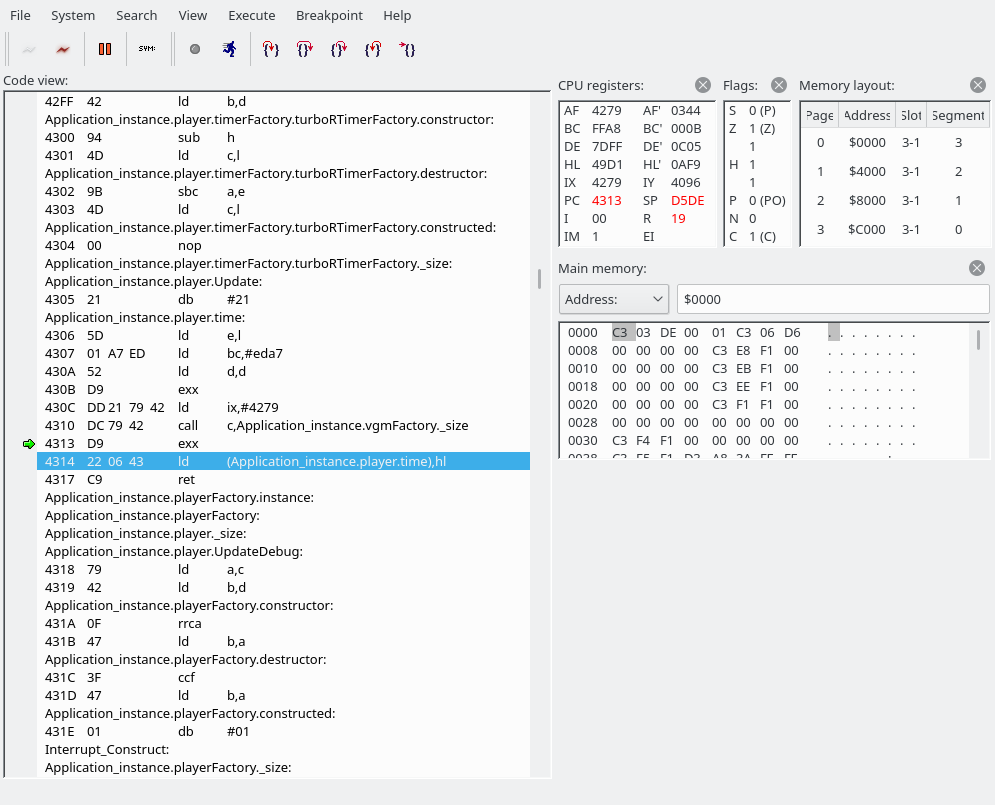
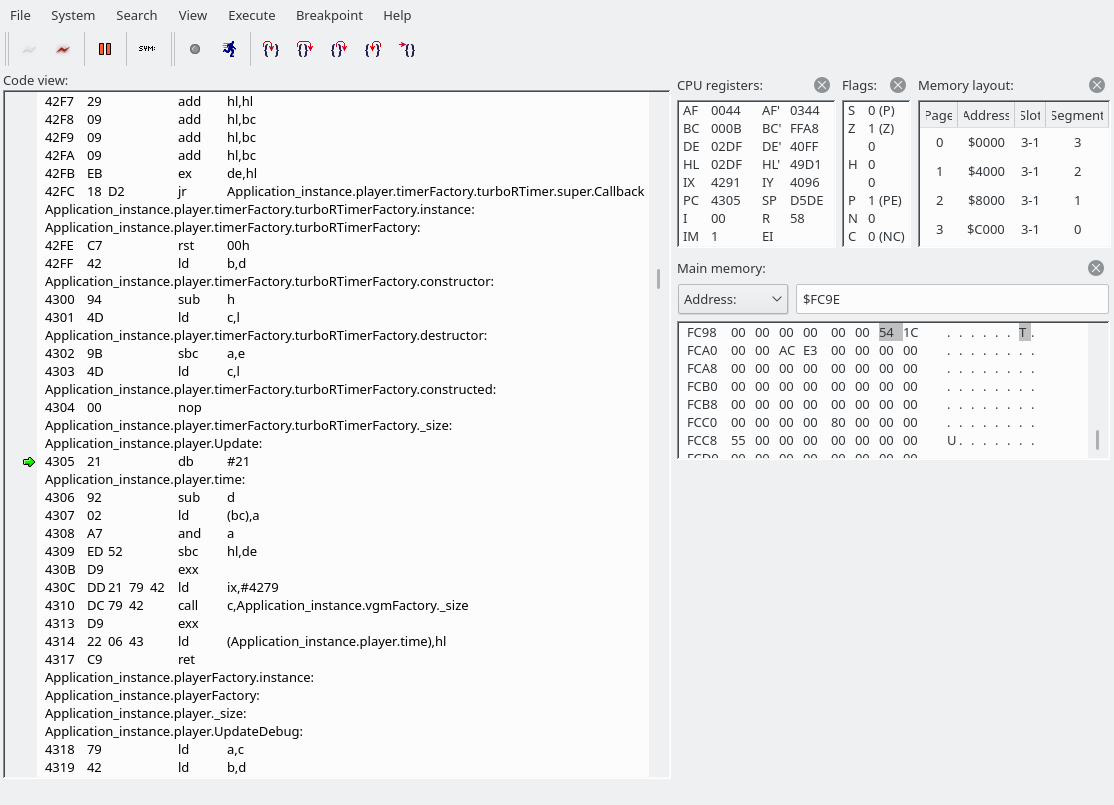
Note that Application_instance.player.time is a variable, not something disassemblablablable.
So what we do here: we save our shadow HL (which has gone past FFFF; it’s currently 0AF9) to a variable called Application_instance.player.time. And after the next ret we’re here:
At some point, we get to “Application_instance.player.timerFactory.vBlankTimer.Update”. Wait, what language is this again?
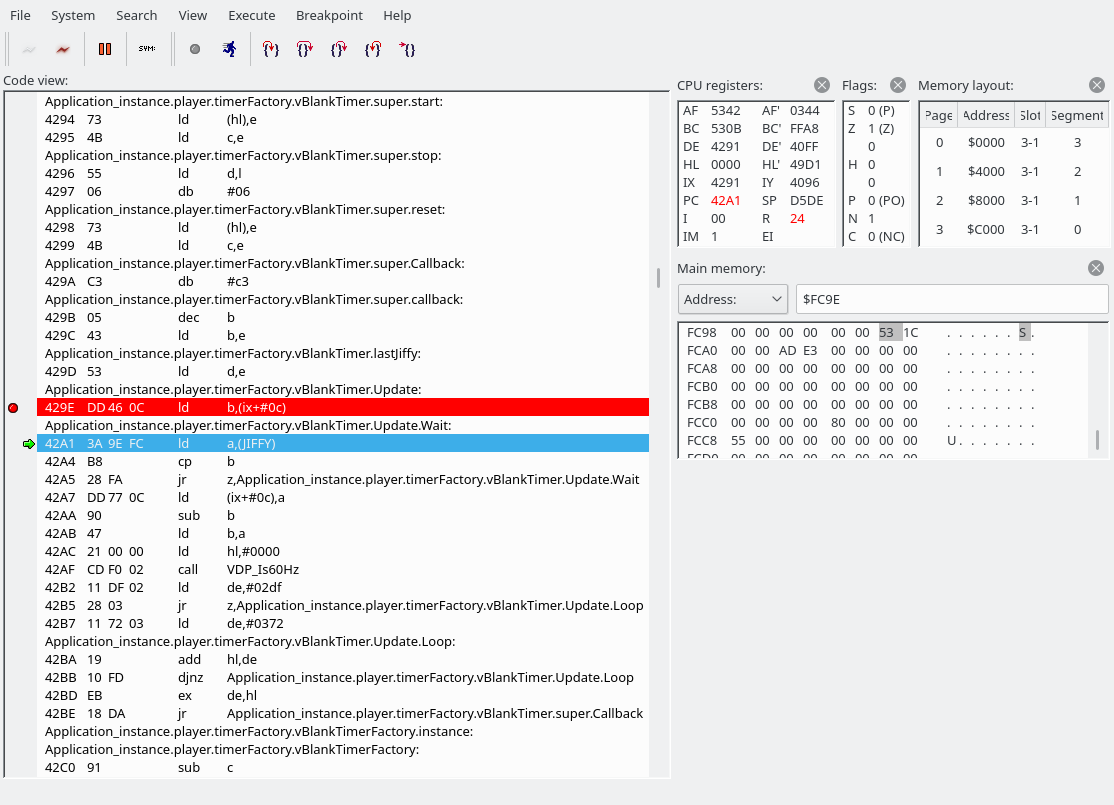
Over here we loop between 42A1 and 42A5 until the JIFFY value contains something different.
Here’s the code with more symbols:
Update: PROC
ld b,(ix + VBlankTimer.lastJiffy)
Wait:
ld a,(JIFFY)
cp b
jr z,Wait
Wait, what’s JIFFY? It’s actually a system variable:
Address: FC9Eh Name: JIFFY Length: 2
Contains value of the software clock, each interrupt of the VDP it is increased by 1. The contents can be read or changed by the function ‘TIME’ or instruction ‘TIME’
After the tight loop is finished, we update lastJiffy with the new JIFFY. Then we set a value for our shadow HL. We either initialize DE with 0x2DF or 0x372 depending on whether we’re on 60 Hz or 50 Hz. (Update: I don’t think this routine works on the MSX1!) Then, we jump to a callback that was set way back when our Timer was first created (i.e., during program initialization), in src/Player.asm:
Actually executing the code we see that we end up in Application_instance.player.Update:
Application_instance.player.time causes the disassembly to look wonky. 4305-4307 loads Application_instance.player.time, currently set to 0292, into the HL register. The next valid instruction is 4308. Also, Application_instance.vgmFactory._size is an alias of Scanner.Process (which is the code we have seen a number of times, where we grab a byte and use the jump table)
We are about to do “sbc hl,de”. The HL register has 0292, DE contains 02DF or 0372, depending on whether the system is 60 Hz or 50 Hz. Note: I don’t think the routine to figure out whether the system is 50 or 60 Hz works on MSX1s.
Address: FFE8h Name: RG09SAV Length: 1
System saves the byte written to the register R#09 here, Used by VDP(10). (MSX2~)
Anyway, I don’t really know where the carry flag that SBC is supposed to take into account comes into play (it’s not set in the code visible in the above screenshot). But anyway, 0292 – 02DF = FFB3. And this is the value we will add numbers to again in the Wait* procedures. Or let’s use our brains just one more time:
There are 0x02DF samples per 60 Hz VSYNC (or 0x0372 samples per 50 Hz VSYNC)
We already “overshot” our previous target by 0x0292 samples in the previous run
We have 0x02DF-0x0292=0x4D samples left until we should wait for VSYNC again
Note: 0x10000-0xFFB3=0x4D
We have now seen enough to take just the parts we need.
What parts do we need?
Jump table
We’ll edit it to remove support for anything but the YM2151 though
We’ll also need the remaining jump locations of course (loop, end of song, wait, etc.)
(Also code to make jump table more efficient)
SFG register writing code
(If possible, also init code to figure out correct slot selection register values.)
Timing code
VSYNC-based timer only
The song data will be directly on the cartridge, so
Let’s do it
For convenience/compatibility with the existing code we will be using the same assembler, Glass, though I don’t think we’ll be using any of its unique features. We won’t be using constructors or a heap, even, but we will use the stack in the same way the existing code is using it.
Cartridge contents are mapped to 4000-7FFF, or if no cartridge was detected at 4000-, then 8000-BFFF. (The MSX BIOS maps in the candidate addresses (starting with 4000-7FFF) and checks for the presence of a header at the beginning of this address space to see check if a cartridge is inserted.) Thus, programs must start like this (I added some useless code in the entry_point that makes it easier to test that this thing is working):
org 4000h ; hex number syntax may differ from assembler to assembler
db "AB" ; all cartridges have this
dw entry_point ; 16-bit absolute pointer
db 00,00,00,00,00,00 ; can be anything probably
entry_point:
nop
jp entry_point
Compilation example if saved as foo.asm:
$ z80asm -o foo.rom foo.asm
$ dd if=/dev/zero of=foo.rom bs=16384 seek=1 count=0 # actually creates a sparse file but that's fine for all intents and purposes
$ hexdump -C foo.rom
00000000 41 42 aa 0f 00 00 00 00 00 00 00 18 fd 00 00 00 |AB..............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00001000
The disassembler is (rightly) confused again at 3FFF, but we can see our code and we are indeed executing a NOP and then jumping right back to that NOP, ad infinitum.
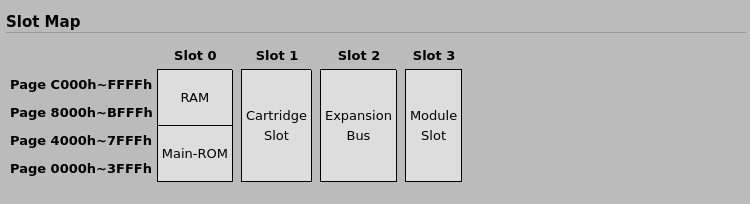
However, we only got our cartridge mapped up to 7FFF, but if we want its whole 48 KB mapped, we need to set port #A8. #A8 of course holds an 8-bit number, but you should interpret it as four 2-bit numbers. “00 00 00 00” (0x00) would mean that everything is on slot 0. “01 01 01 01” (0x55) would mean that everything is on slot 1. You can choose any combination your hardware likes.
All MSXs have Main-ROM in primary slot 0 or in secondary slot 0-0 (see variable EXPTBL below for more details). Cartridge slot that is on top of computer is typically slot 1. If there is another expansion port then this is often slot 2. Although the internal RAM should preferably be in slot 3, this is often not the case for MSX1s.
https://www.msx.org/wiki/Slots
The cartridge slot is “typically slot 1”. I don’t know if there are any computers that have a different number, but it’s easy to determine the number in software: we’re running off 4000-7FFF, so the slot is already set correctly here. We just need to set the page we want to the same number.
Now, if we want to set 4000-FFFF to the cartridge, we won’t have any RAM. And therefore, no stack. vgmplay uses the stack (as seen earlier). vgmplay also uses the BIOS (mapped into 0000-3FFF) because we need the VSYNC interrupt handler, and this interrupt handler writes to a system variable called JIFFY, which is located at FC9E, as mentioned above. We could decide to leave the last slot for RAM, limiting the amount of song data we can play to less than 32 KB. But the amount of RAM we need isn’t exactly very much. In addition, as we have seen, some parts of the vgmplay code are self-modifying.
So what we’ll do instead is: copy the entire cartridge to RAM. Then we’ll be able to use self-modifying code, and we’ll be able to have a stack too. Sounds easy? Well, let’s say we have our copying routine at ROM address 4100. What happens if we try to copy the ROM at 4000-7FFF to RAM? We’ll execute instructions at 4100, and these instructions say to switch 4000-7FFF to RAM, which we do, and then what? We’ll have pulled the carpet from under our feet! One way to avoid this problem is by having two (or more) copies of the copying code.
So first we could copy 8000-BFFF to RAM, which doesn’t require any precautions. For the page starting at C000, we probably shouldn’t copy past F000, which is where the stack and some system variables appear to be located. (Not that the stack holds anything.) But otherwise no precautions are required. Then, we jump to (e.g.) 8100, where we have another copy of our copy routine, and copy 4000-7FFF. (We’ll choose a different location for the second copy because we’d expect the song data to start before 8100. Perhaps F200 or so.) If we copy byte-by-byte (or word-by-word), switching between ROM and RAM every time, we can use a single register to hold the read value and won’t need any buffer memory (which would complicate things a bit). (It finishes in less than 1 second per 16 KB, so no issues here as this is init code.)
One more annoyance is that since we do not have a stack, it doesn’t make a lot of sense to ‘call’ the copy code. Jumping to the code isn’t exactly fun either because we’d have to know where to jump back, and the register dance becomes a little annoying. So we’ll just copy and paste the code. Here’s the first-draft code to copy 4000-F000 from ROM to RAM. This code assumes that the BIOS ROM is in slot 0, the cartridge ROM in slot 1, all RAM in slot 3, and that there are no subslots. This assumption doesn’t hold on many systems. This code can be compiled using z80asm using the following command line:
z80asm -o foo.rom foo.asm
org 4000h
db "AB"
dw entry_point
db 00,00,00,00,00,00
entry_point:
ld a,01010100b ; set rom - cart - cart - cart
out (0a8h),a
; copy 8000-bfff
copy_8000_bfff:
ld hl,08000h ; start at 8000
copy_8000_bfff_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
or 000110000b ; set bits 5-4 to 11 (RAM) (actual value depends on machine)
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 0c0h
jp z,copy_c000_f000 ; done with this copy
jp copy_8000_bfff_loop
copy_c000_f000:
ld hl,0c000h ; start at c000
copy_c000_f000_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
or 011000000b ; set bits 5-4 to 11 (RAM) (actual value depends on machine)
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 0f0h
jp z,copy_4000_7fff ; done with this copy
jp copy_c000_f000_loop
done_copying:
ld a,011111100b ; switch to 4000-ffff to RAM
out (0a8h),a
nop:
nop
jr nop ; infinite loop
seek 0b000h ; b000+4000 = f000
org 0f000h
copy_4000_7fff:
ld hl,04000h ; start at c000
copy_4000_7fff_loop:
ld a,(hl) ; read from ROM address (hl)
ld d,a
in a,(0a8h)
ld b,a ; store original value
or 000001100b ; set bits 5-4 to 11 (RAM) (actual value depends on machine)
out (0a8h),a ; set port
ld (hl),d ; store value read from ROM address (hl) to RAM address (also hl of course)
ld a,b ; load a with original value
out (0a8h),a ; set port back
inc hl
ld a,h
cp 080h
jp z,done_copying ; done with this copy
jp copy_4000_7fff_loop
This is pretty almost all that we need to code ourselves, everything else will be copy and pasted from vgmplay-msx! Note: the above doesn’t actually assemble in Glass because Glass requires that reserved words like “org” are indented, and “seek” isn’t supported. The final code will therefore look a bit different.
Putting all the necessary bits together (and throwing out everything else)
I got it to work on an emulated version of my Hitachi H2. (My apologies to the original author of vgmplay. I completely butchered their code.) And right when I start looking at the slot map of the computer I actually intended to run this one (Yamaha YIS-503), I noticed that the silly machine only has 32 KB of RAM, har har har. And (this was expected though not quite to this extent) the slot map is different, so the #a8 port settings will have to adjusted. With 64 KB we could load the whole 48 KB ROM into RAM, but with 32 KB, arranged the way it is, we’ll boot from 8000 and ignore 4000-7FFF. (We could rewrite the self-modifying code to refer to variables in RAM space instead, but unfortunately I’m running out of steam on this project. I’d planned two days and it’s about three days already! :p)
It ended up working on this machine too, of course. Except, I think that openMSX might be putting the SFG-01 into a different slot (2), rather than slot 3 as sort of indicated in the above screenshot. Due to the limited amount of RAM, our music gets truncated even earlier than before. Feel free @ anyone wanting to fix this. TBH, I just want to be able to hear if the music sounds okay or not. (Edit 2023/04/08: I checked on a real YIS-503 and the SFG-01 was indeed in slot 3, so the above screenshot is correct.)
Today’s post is AI-heavy! AI as in OCR (“optical character recognition”). We will OCR (“optical character recognize”) a hex listing for a Prolog interpreter (which used to be thought of as an “AI language”) for the Commodore VIC-20! (As a bonus, some small parts of the tools I made to verify the OCR transcription were written by ChatGPT.)
As you may have heard before, OCRing stuff is error-prone. Ls and Is and 1s being mixed up makes natural language texts annoying to read, and program listings almost useless, because you’ll spend a long time trying to find the error. Why does this take a long time? Because our eyes (and attached circuitry) don’t notice tiny imperfections in a sea of details. However, we are quite good at noticing things that look completely different from the surrounds.
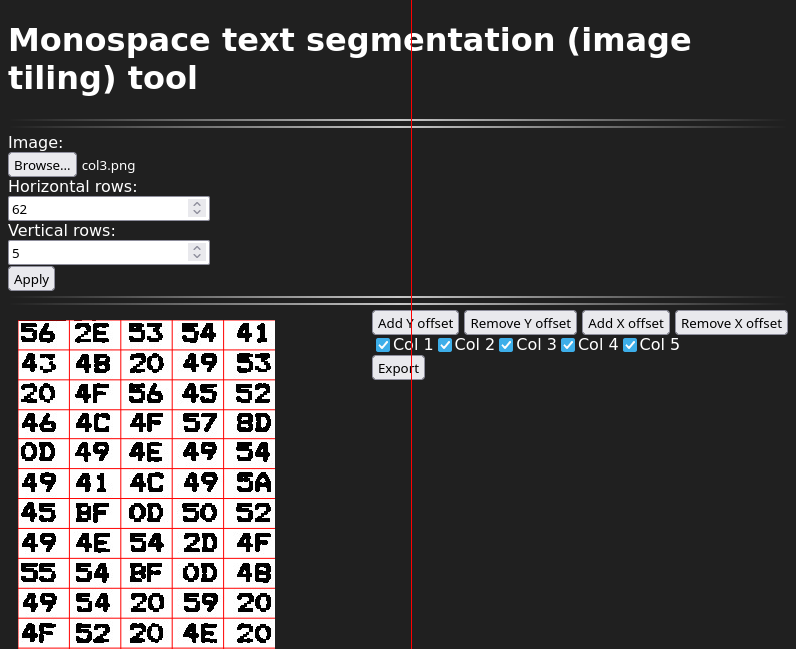
With hex OCR, we really only have to worry about 16 different classes (types of digit). This makes it relatively easy to verify if our OCR is correct (and perform fixes), because we can take our OCR’d digits and temporarily (while remembering their original position) display them all, sorted by class. Like this:
We can easily see that all these are indeed 3s, 4s, and 5s.
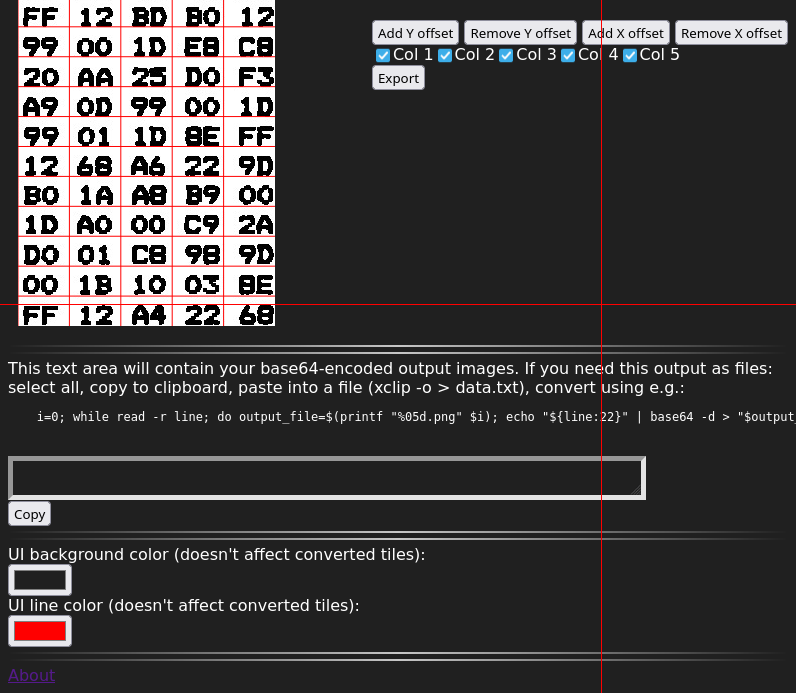
Or like this:
We can easily see that there’s a 0 in our list of 6s and a 9 in our list of 7s.
(Note: occasionally, OCR tools will turn a single character into two characters, or the other way round. That kind of problem will require manual edits.)
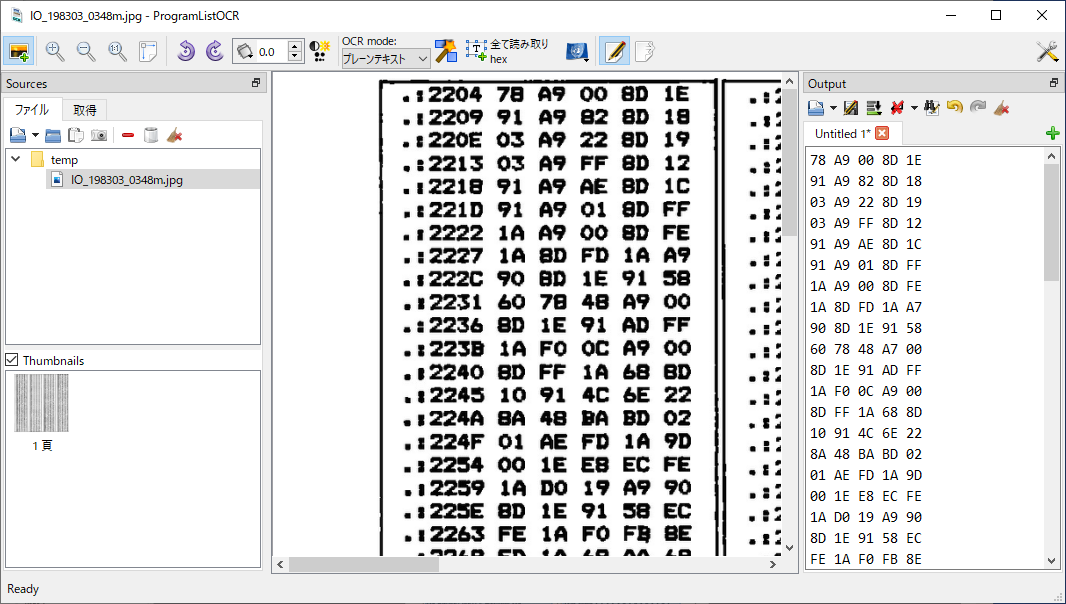
For the original OCR, I used a program called ProgramListOCR. The program supports OCRing hex dumps. This program requires that you touch up input images in (e.g.) Gimp before loading them. It’s not difficult, and the program’s README describes what needs to be done. Unfortunately, this process removes a small amount of detail from the image, making it harder to distinguish between, e.g., Bs and 8s. And unfortunately, I believe the program only runs in Windows. Here’s a screenshot of the program running:
ProgramListOCR made 142 digit mistakes. The hex dump consisted of 7310 digits, so the overall error rate is 1.943%, or the accuracy is 98.057%.
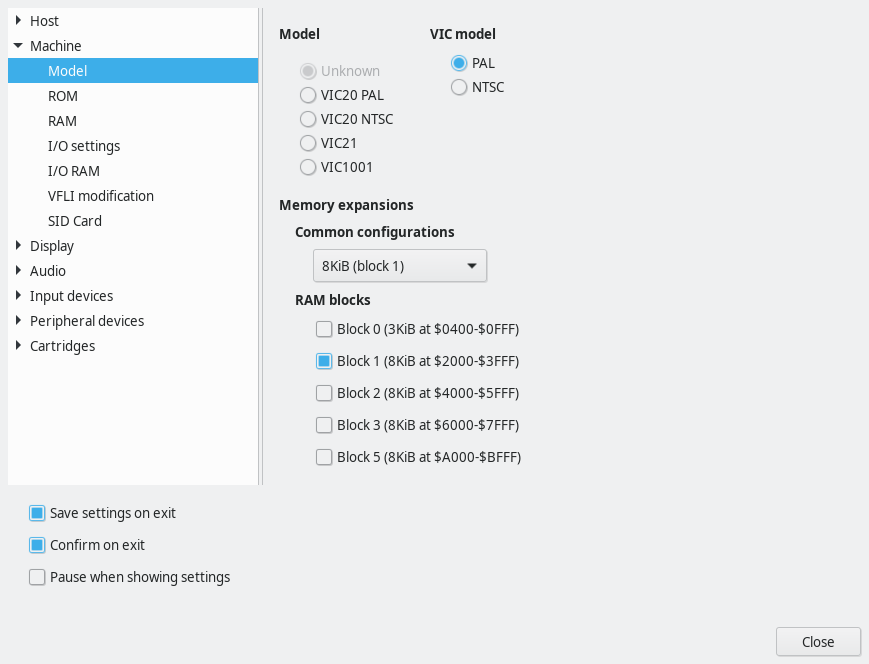
In order to run this on your VIC-20 emulator, you need to set it to have an 8K memory expansion. Then you need to load the binary data into RAM; starting address is 2204. In VICE, you can add the memory expansion in this config window:
Select at least “Block 1 (8KiB at $2000-$3FFF)”. PAL/NTSC etc. do not matter.
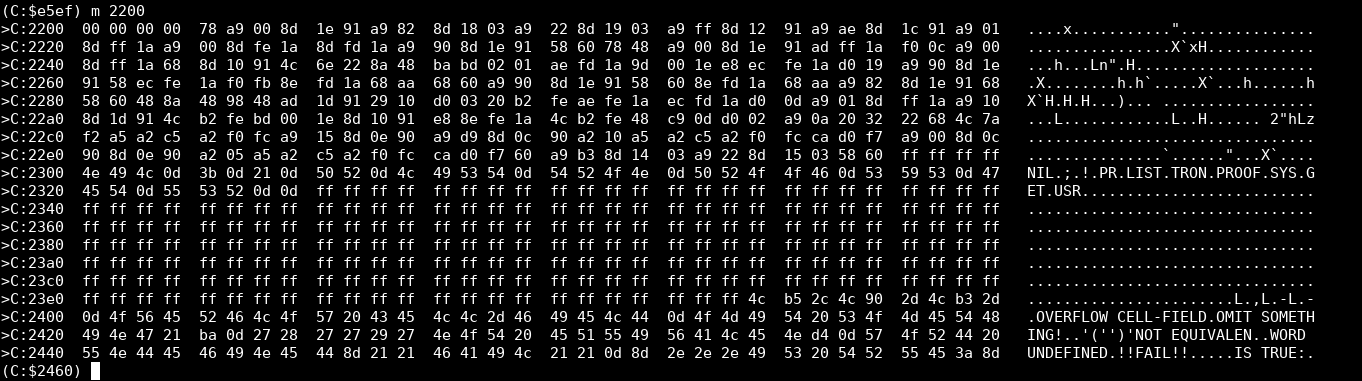
To load the binary data into address $2204 and beyond, start the monitor (Alt+H), and then I wish it’d work with ‘load “/path/to/prolog.bin” 0 2204’. But for some reason that doesn’t work; the first few bytes are garbled and the reset isn’t aligned correctly. If you have this issue, try the other file and ‘load “/path/to/prolog_prefixed_with_zeros.bin” 0 2202’. Execute “m 2200” in the monitor to see if VICE loaded your file into the correct address. The following is an example of a successful load:
2200-2203 don’t matter, 2204- should be 78 a9 00 8d, etc.
Then you close the monitor and type “SYS 11445” in the BASIC prompt, and you should get something like this:
Having fun with Prolog
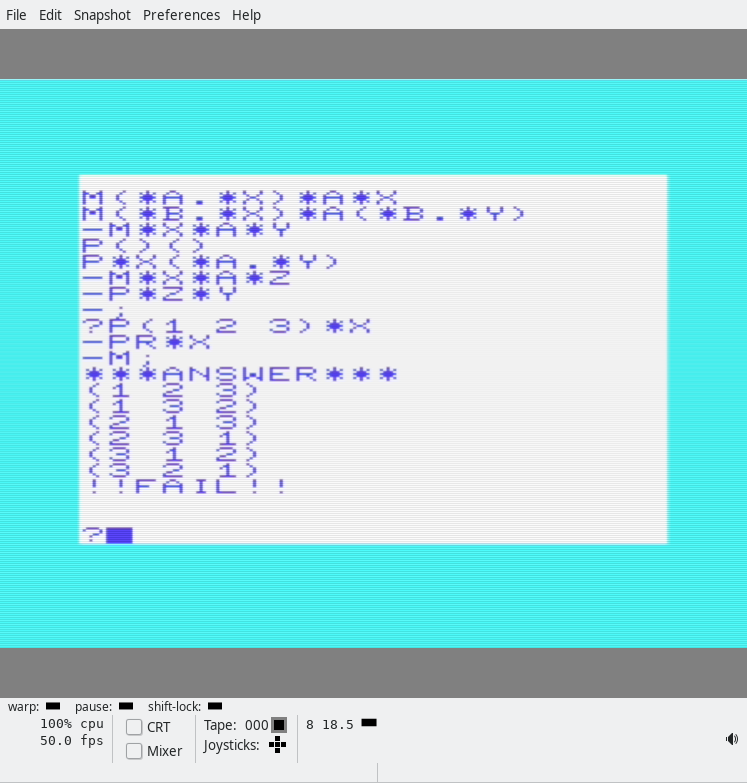
There are various sample programs in the magazine. Note that the Prolog interpreter sometimes gives you a question mark prompt, and sometimes a hyphen prompt. You have to delete these manually by pressing backspace (Delete), depending on what you want to do! Let’s start with this short program:
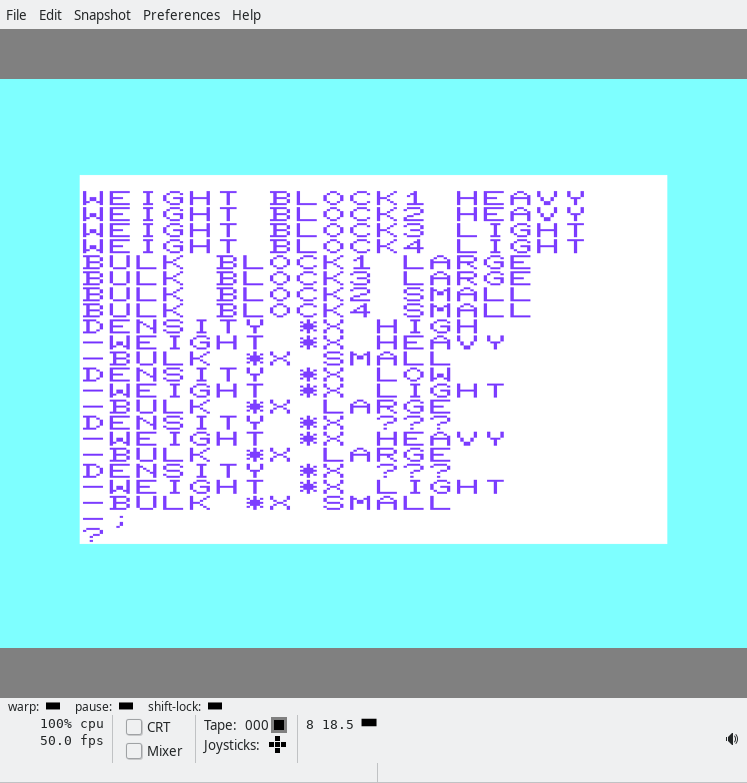
The next program (actually the first in the magazine, and easiest) is a program that tells you whether the density of blocks 1-4 is high or low, or unknown:
That’s the data and the functions, er, I mean predicates.
weight block1 heavy
weight block2 heavy
weight block3 light
weight block4 light
bulk block1 large
bulk block3 large
bulk block2 small
bulk block4 small
density *x high
-weight *x heavy
-bulk *x small
density *x low
-weight *x light
-bulk *x large
density *x ???
-weight *x heavy
-bulk *x large
density *x ???
-weight *x light
-bulk *x small
-;
?
I believe I speak for us all when I say, the syntax looks a bit weird? Anyway, the first few things are the data, er, I means facts. Then you get a function, er, predicate “signature”, and below the predicate signature you get the actual… predicate definition (the lines that start with a hyphen). (Predicates may also be called rules.) Want to finish up the current rules and start a new one with a different signature? Just backspace away the hyphen. When you’re all done, type a semicolon, and you’ll be back at the ‘?’ prompt. Now we can run queries!
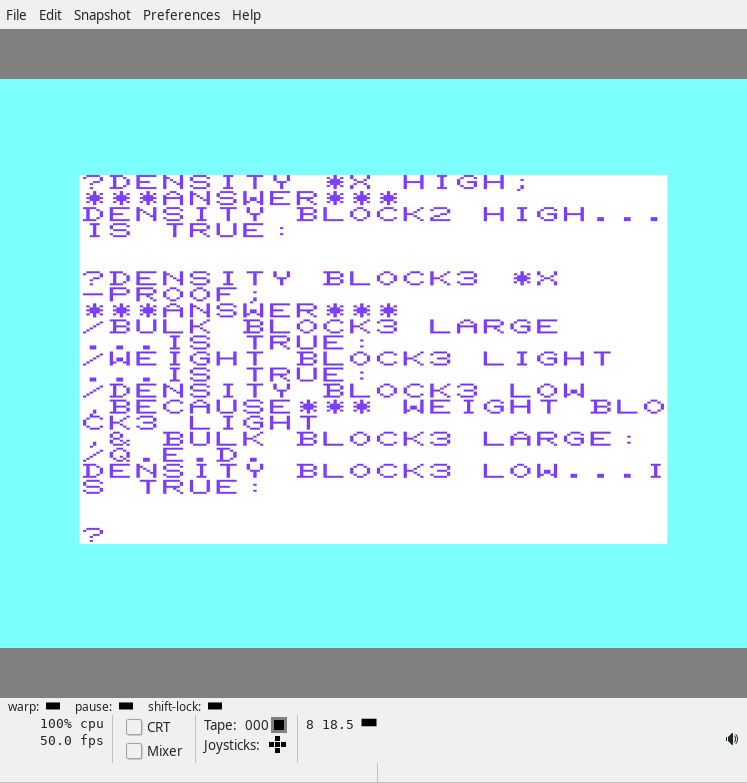
In the screenshot, we first ask which blocks have a high density. The answer is BLOCK2!
Then we ask it the density of BLOCK3 and ask it the reason using the PROOF
Summary: Segmentation tool and OCR verification tool. You can use these tools to either verify an existing OCR’d hex dump, or use them to run your own OCR. (Which isn’t hard! You can probably get ChatGPT to produce a probably working Python script using PyTorch to learn the digits, and easily get 97% (or so) accuracy. Maybe something along the lines of, “Write a Python script that uses PyTorch to train recognition of something like MNIST, except there are 16 classes, not 10. The recognition should use convolutional layers. Input images are PNG files. Labels are in a text file.” (I just tried and the result looks plausible.))
Why hex dumps anyway? Because in the 1980s computer magazines sometimes included printed hex dumps of programs. But that’s just how I got motivated to write these tools. More on that in this post.
If you are familiar with basic image recognition concepts, you may know that detecting hand-written digits is generally considered to be a very easy task, the “hello world” of AI image recognition even. (Didn’t know this? Maybe search for “MNIST dataset”)
If recognizing handwritten digits is considered so easy, recognizing printed digits should be even easier, no? The answer is “yes” and “no”, because I left out some information above. The MNIST dataset consists of images that contain exactly one digit. OCR, on the other hand, requires segmentation. In general, recognizing typed letters if you have them in a nicely cropped single image is quite easy. (Except for letters that look very similar or even identical, of course.) Is segmentation an easy task? Well, there are all kinds of layouts out there. If you want to know more about segmentation, Andrew Ng explained the basics in this and the following few videos: https://www.youtube.com/watch?v=CykIW9hFK24&list=PLLssT5z_DsK-h9vYZkQkYNWcItqhlRJLN&index=108. These videos are part of Andrew Ng’s Machine Learning course on coursera.org, but I can’t find the specific lecture that contained this bit. (tl;dr: basically, you have a pipeline with multiple stages: first you detect regions that vaguely look like text, then a stage that detects if you have a single character or more than one character, and finally a stage that can recognize single characters.)
Performing segmentation on hex dumps and other monospace text is quite easy. However, getting the segmentation wrong can ruin the OCR. Either hardly anything will be recognized, or things will be jumbled up. I played around with Tesseract and a couple other OCR systems but wasn’t able to get good results on hex dumps. Hex dumps have the additional benefit that there are only 16 symbols that need to be recognized. One tool that work pretty well was ProgramListOCR (https://github.com/eighttails/ProgramListOCR). I think it was over 95% accurate with my input images. If it could output the segmentation too, it would be even better, in my opinion.
In this blog post I’m going to describe the tools I linked to above (Segmentation tool and OCR verification tool) and how we can use these tools to get a perfect OCR scan of a hex dump. Because let’s face it… A 99% correct hex dump isn’t all that useful, unless you enjoy sending old CPUs off the rails, or playing spot the difference.
Text segmentation/image tiling tool
The segmentation tools sort of looks like this (at the time of this writing):
Top of page (let’s skip the middle)Bottom
What you can do here is: select an image from a file, specify the number of columns and rows, adjust the rows and columns using the buttons on the right (and then clicking somewhere in the image to that row or column smaller or larger), export to tiles. The adjustment process is best done at high zoom levels (use Ctrl+scroll wheel to zoom). You can also choose to skip certain columns when exporting. You can use the keyboard to do most things. (Cursor keys: move around, space: use current tool at cursor position, T: toggle column export tool, x/X: add/remove X offset tool, y/Y: add/remove Y offset tool.) The tiles will be output into data URLs in the text area at the bottom of the page. You can convert the data URLs back into files using the given shell code snippet. Also reproduced here:
# put contents of clipboard into a file:
xclip -o > data.txt
# convert data URLs in data.txt to PNG files:
i=0; while read -r line; do output_file=$(printf "%05d.png" $i); echo "${line:22}" | base64 -d > "$output_file"; i=$((i+1)); done < data.txt
You can of course also tile into single characters. You’ll just have to fiddle a little more with the offset tools.
OCR verification tool
Here are two screenshots that may help to get some intuition on how to use this tool:
Top of pageBottom
This tool (at the time of this writing) expects as input 1) images as data URLs, to be pasted into the textarea at the top of the page, and 2) the predicted labels corresponding to each image.
The tool then displays the input images sorted into their classes for easy verification by a human. ;) And this is pretty easy for humans, because there are just 16 classes and the human eye is very sensitive to objects that don’t look like the surrounding objects. Here’s another screenshot to demonstrate that it should be easy to find things that look out of place:
The 0 surrounded by 6es and 9 in the cluster of 7s should be pretty easy to spot. (It is also possible that there are Bs surrounded by 8s, but that’s a different topic.)
The web page allows you to drag the images around to put them in the correct category, and to then reconstruct the labels, taking the fixes into account.
Dragging and dropping 9s mis-identified as 7s.
Here’s a more real-world example, with unpolished input images. (If you invest a couple minutes to add/remove offsets in the segmentation tool, you should get slightly better images than this.)
This is one page (around 1/3) of the entire hex dump